DataFlow
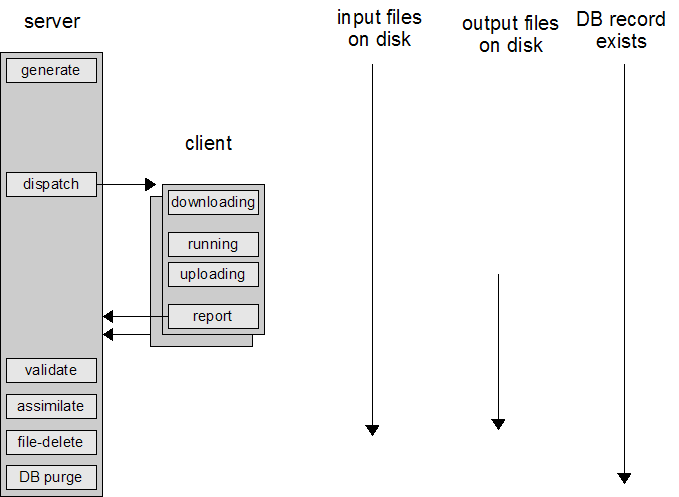
BOINC is designed for high throughput: millions of volunteer hosts, millions of jobs per day. To maximize your project's performance it's important to understand the life-cycle of a job:
- A work generator (a program you supply) creates the job and its associated input files.
- BOINC creates one or more instances of the job.
- BOINC dispatches the instances to different hosts.
- Each host downloads the input files.
- After some queueing delay due to other jobs in progress, the host executes the job, then uploads its output files.
- The host reports the completed job, possibly after an additional delay (whose purpose is to reduce the rate of scheduler requests).
- A validator (a program you supply) checks the output files, perhaps comparing replicas.
- When a valid instance is found, an assimilator (a program you supply) handles the results, e.g., by inserting them in a separate database.
- When all instances have been completed, a file deleter deletes the input and output files.
- A DB purge program deletes the database entries for the job and job instances.
Each job can have arbitrarily many input and output files. Each file has various attributes, e.g.:
- Sticky: the file should remain on the client even when no job is using it.
- Upload when present: upload the file when it's complete (the default is to not upload it).
Jobs don't need to have any input or output files; the input can come from command-line arguments (which are stored in the database record for the job) and the output can be written to stderr (which is returned to the server and stored in the DB).
Suppose you have many jobs that use the same input file. In that case mark it as sticky; clients will then download it just once.
Suppose your application generates a file which can potentially be used by subsequent jobs. In that case make it a sticky output file, without upload-when-present.
Suppose you have an application that has large input files, and many jobs use the same input file. In that case, once a file has been downloaded to a client, you'd like to issue it jobs that use that file if possible. To support this, BOINC offers a mechanism called locality scheduling.