BoincFiles
The BOINC storage model is based on files. Examples of files:
- The inputs and outputs of computation;
- Components of application: executables, libraries, etc.
- Data for its own sake, e.g. as part of a distributed storage system.
The BOINC client transfers files to and from project-operated data servers using HTTP.
The name of a file is called its "physical name". A file of a given physical name is immutable. This means that all replicas of that file are assumed (and required) to be identical. If a file is changed, even by a single byte, it becomes a new file, and must be given a different name.
Note: systems for combining or compressing files, like tar and gzip, may add timestamps, so archiving the same set of files can produce differing results. With gzip, the --no-name option suppresses this.
You can assign various properties to files, including:
- Logical name: the name by which an application refers to a file. Must be nonempty, at most 255 chars, and may not contain '..', '/', or '%'.
- Sticky: don't delete file on client (see below).
- Report on RPC: include a description of this file in scheduler requests.
- Maximum size: if an output file exceeds its maximum size, the computation is aborted.
File properties are specified in job input and output templates.
The BOINC client uses the following directory structure:
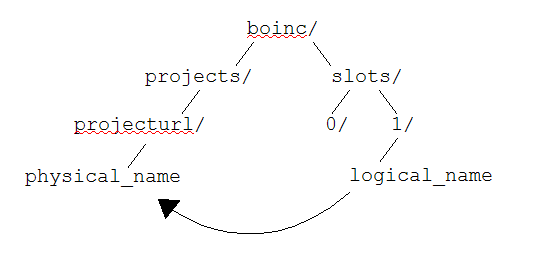
Each project has its own project directory where its file reside. The names of files in this directory are physical names.
Each job executes in its own slot directory (slots/0, etc.).
The slot directory contains links to the job's input and output files.
The name of each link is a logical name.
(These links aren't symbolic or hard links, because Windows doesn't have them;
rather, they're XML files containing the path of the file in the project directory).
Applications call a BOINC API function boinc_resolve_filename()
to map logical names to physical names prior to opening them.
This architecture provides two advantages:
- Multiple concurrent jobs can access a given file without having separate copies of it.
- Applications can contain hardwired (logical) file names, but can be run against different physical files.
The way a job uses a file is called a file reference, and is specified in job input and output templates. A file reference includes the logical name. It can also specify a copy file attribute; if present, the linking mechanism described above is not used; rather, the BOINC client copies the file from the project directory to the slot directory before running the application (for input files) or copies the file from the slot directory to the project directory after running the application (for output files). This mechanism is needed for legacy applications that don't use BOINC's API functions.
BOINC's default behavior is to delete files when they aren't needed any more. Specifically:
- On the client, input files are deleted when no workunit refers to them, and output files are deleted when no result refers to them. Application-version files are deleted when they are referenced only from superseded application versions.
- On the client, the 'sticky' flag overrides the above mechanisms and suppresses the deletion of the file. Sticky files may be deleted in either of two ways.
- On the server, the file deleter daemon deletes input and output files that are no longer needed. This can be suppressed by setting the 'no_delete' property on the file, or using command-line options to the file deleter.