This is a Keras implementation of a CNN for estimating age and gender from a face image [1, 2]. In training, the IMDB-WIKI dataset is used.
- [Jun. 30, 2019] Another PyTorch-based project was released
- [Nov. 12, 2018] Enable Adam optimizer; seems to be better than momentum SGD
- [Sep. 23, 2018] Demo from directory
- [Aug. 11, 2018] Add age estimation sub-project here
- [Jul. 5, 2018] The UTKFace dataset became available for training.
- [Apr. 10, 2018] Evaluation result on the APPA-REAL dataset was added.
- Python3.5+
- Keras2.0+
- scipy, numpy, Pandas, tqdm, tables, h5py
- dlib (for demo)
- OpenCV3
Tested on:
- Ubuntu 16.04, Python 3.5.2, Keras 2.0.3, Tensorflow(-gpu) 1.0.1, Theano 0.9.0, CUDA 8.0, cuDNN 5.0
- CPU: i7-7700 3.60GHz, GPU: GeForce GTX1080
- macOS Sierra, Python 3.6.0, Keras 2.0.2, Tensorflow 1.0.0, Theano 0.9.0
Run the demo script (requires web cam).
You can use --image_dir [IMAGE_DIR] option to use images in the [IMAGE_DIR] directory instead.
python3 demo.pyThe pretrained model for TensorFlow backend will be automatically downloaded to the pretrained_models directory.
First, download the dataset.
The dataset is downloaded and extracted to the data directory by:
./download.shSecondly, filter out noise data and serialize images and labels for training into .mat file.
Please check check_dataset.ipynb for the details of the dataset.
The training data is created by:
python3 create_db.py --output data/imdb_db.mat --db imdb --img_size 64usage: create_db.py [-h] --output OUTPUT [--db DB] [--img_size IMG_SIZE] [--min_score MIN_SCORE]
This script cleans-up noisy labels and creates database for training.
optional arguments:
-h, --help show this help message and exit
--output OUTPUT, -o OUTPUT path to output database mat file (default: None)
--db DB dataset; wiki or imdb (default: wiki)
--img_size IMG_SIZE output image size (default: 32)
--min_score MIN_SCORE minimum face_score (default: 1.0)Firstly, download images from the website of the UTKFace dataset.
UTKFace.tar.gz can be downloaded from Aligned&Cropped Faces in Datasets section.
Then, extract the archive.
tar zxf UTKFace.tar.gz UTKFaceFinally, run the following script to create the training data:
python3 create_db_utkface.py -i UTKFace -o UTKFace.mat
[NOTE]: Because the face images in the UTKFace dataset is tightly cropped (there is no margin around the face region),
faces should also be cropped in demo.py if weights trained by the UTKFace dataset is used.
Please set the margin argument to 0 for tight cropping:
python3 demo.py --weight_file WEIGHT_FILE --margin 0The pre-trained weights can be found here.
Train the network using the training data created above.
python3 train.py --input data/imdb_db.matTrained weight files are stored as checkpoints/weights.*.hdf5 for each epoch if the validation loss becomes minimum over previous epochs.
usage: train.py [-h] --input INPUT [--batch_size BATCH_SIZE]
[--nb_epochs NB_EPOCHS] [--lr LR] [--opt OPT] [--depth DEPTH]
[--width WIDTH] [--validation_split VALIDATION_SPLIT] [--aug]
[--output_path OUTPUT_PATH]
This script trains the CNN model for age and gender estimation.
optional arguments:
-h, --help show this help message and exit
--input INPUT, -i INPUT
path to input database mat file (default: None)
--batch_size BATCH_SIZE
batch size (default: 32)
--nb_epochs NB_EPOCHS
number of epochs (default: 30)
--lr LR initial learning rate (default: 0.1)
--opt OPT optimizer name; 'sgd' or 'adam' (default: sgd)
--depth DEPTH depth of network (should be 10, 16, 22, 28, ...)
(default: 16)
--width WIDTH width of network (default: 8)
--validation_split VALIDATION_SPLIT
validation split ratio (default: 0.1)
--aug use data augmentation if set true (default: False)
--output_path OUTPUT_PATH
checkpoint dir (default: checkpoints)Recent data augmentation methods, mixup [3] and Random Erasing [4],
can be used with standard data augmentation by --aug option in training:
python3 train.py --input data/imdb_db.mat --augPlease refer to this repository for implementation details.
I confirmed that data augmentation enables us to avoid overfitting and improves validation loss.
python3 demo.pyusage: demo.py [-h] [--weight_file WEIGHT_FILE] [--depth DEPTH]
[--width WIDTH] [--margin MARGIN] [--image_dir IMAGE_DIR]
This script detects faces from web cam input, and estimates age and gender for
the detected faces.
optional arguments:
-h, --help show this help message and exit
--weight_file WEIGHT_FILE
path to weight file (e.g. weights.28-3.73.hdf5)
(default: None)
--depth DEPTH depth of network (default: 16)
--width WIDTH width of network (default: 8)
--margin MARGIN margin around detected face for age-gender estimation (default: 0.4)
--image_dir IMAGE_DIR
target image directory; if set, images in image_dir
are used instead of webcam (default: None)Please use the best model among checkpoints/weights.*.hdf5 for WEIGHT_FILE if you use your own trained models.
python3 plot_history.py --input models/history_16_8.h5 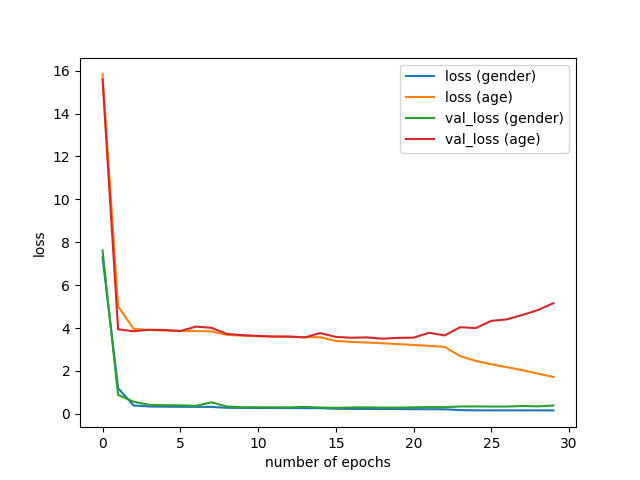

The best val_loss was improved from 3.969 to 3.731:
- Without data augmentation: 3.969
- With standard data augmentation: 3.799
- With mixup and random erasing: 3.731

We can see that, with data augmentation, overfitting did not occur even at very small learning rates (epoch > 15).
In the original paper [1, 2], the pretrained VGG network is adopted. Here the Wide Residual Network (WideResNet) is trained from scratch. I modified the @asmith26's implementation of the WideResNet; two classification layers (for age and gender estimation) are added on the top of the WideResNet.
Note that while age and gender are independently estimated by different two CNNs in [1, 2], in my implementation, they are simultaneously estimated using a single CNN.
Trained on imdb, tested on wiki.

You can evaluate a trained model on the APPA-REAL (validation) dataset by:
python3 evaluate_appa_real.pyPlease refer to here for the details of the APPA-REAL dataset.
The results of pretrained model is:
MAE Apparent: 6.47
MAE Real: 7.61
The best result reported in [5] is:
MAE Apparent: 4.08
MAE Real: 5.30
Please note that the above result was achieved by finetuning the model using the training set of the APPA-REAL dataset, while the pretrained model here is not and the size of images is small (64 vs. 224).
Anyway, I should do finetuning on the training set of the APPA-REAL...
If you want better results, there would be several options:
- Use larger training images (e.g. --img_size 128).
- Use VGGFace as an initial model and finetune it (https://github.com/rcmalli/keras-vggface).
- In this case, the size of training images should be (224, 224).
- Use more "clean" dataset (http://chalearnlap.cvc.uab.es/dataset/18/description/) (only for age estimation)
This project is released under the MIT license. However, the IMDB-WIKI dataset used in this project is originally provided under the following conditions.
Please notice that this dataset is made available for academic research purpose only. All the images are collected from the Internet, and the copyright belongs to the original owners. If any of the images belongs to you and you would like it removed, please kindly inform us, we will remove it from our dataset immediately.
Therefore, the pretrained model(s) included in this repository is restricted by these conditions (available for academic research purpose only).
[1] R. Rothe, R. Timofte, and L. V. Gool, "DEX: Deep EXpectation of apparent age from a single image," in Proc. of ICCV, 2015.
[2] R. Rothe, R. Timofte, and L. V. Gool, "Deep expectation of real and apparent age from a single image without facial landmarks," in IJCV, 2016.
[3] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, "mixup: Beyond Empirical Risk Minimization," in arXiv:1710.09412, 2017.
[4] Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, "Random Erasing Data Augmentation," in arXiv:1708.04896, 2017.
[5] E. Agustsson, R. Timofte, S. Escalera, X. Baro, I. Guyon, and R. Rothe, "Apparent and real age estimation in still images with deep residual regressors on APPA-REAL database," in Proc. of FG, 2017.