NLP做分类任务时常需要提交自己的算法到GLUE进行评测,可是就能找到的评测代码而言,它们不太容易读懂和修改(毕竟耦合了其他很多操作)。因此,就打算写一个袖珍版的GLUE评测代码,供大家使用。所有任务经过测试,已复现官方效果,且大多数高于官方。
GLUE benchmark: General Language UnderstandingEvaluation
- val set:
| Task | Metric | BERT-base* | BERT-base# |
|---|---|---|---|
| CoLA | Matthews corr | 56.53 | 57.11 |
| SST-2 | Accuracy | 92.32 | 92.66 |
| MRPC | F1/Accuracy | 88.85/84.07 | 89.00/84.64 |
| STS-B | Pearson/Spearman corr | 88.64/88.48 | 89.13/88.54 |
| QQP | Accuracy/F1 | 90.71/87.49 | 90.84/87.70 |
| MNLI | M acc/MisM acc | 83.91/84.10 | 83.27/83.65 |
| QNLI | Accuracy | 90.66 | 91.47 |
| RTE | Accuracy | 65.70 | 72.20 |
| WNLI | Accuracy | 56.34 | 56.34 |
* Huggingface # Our
- test set:
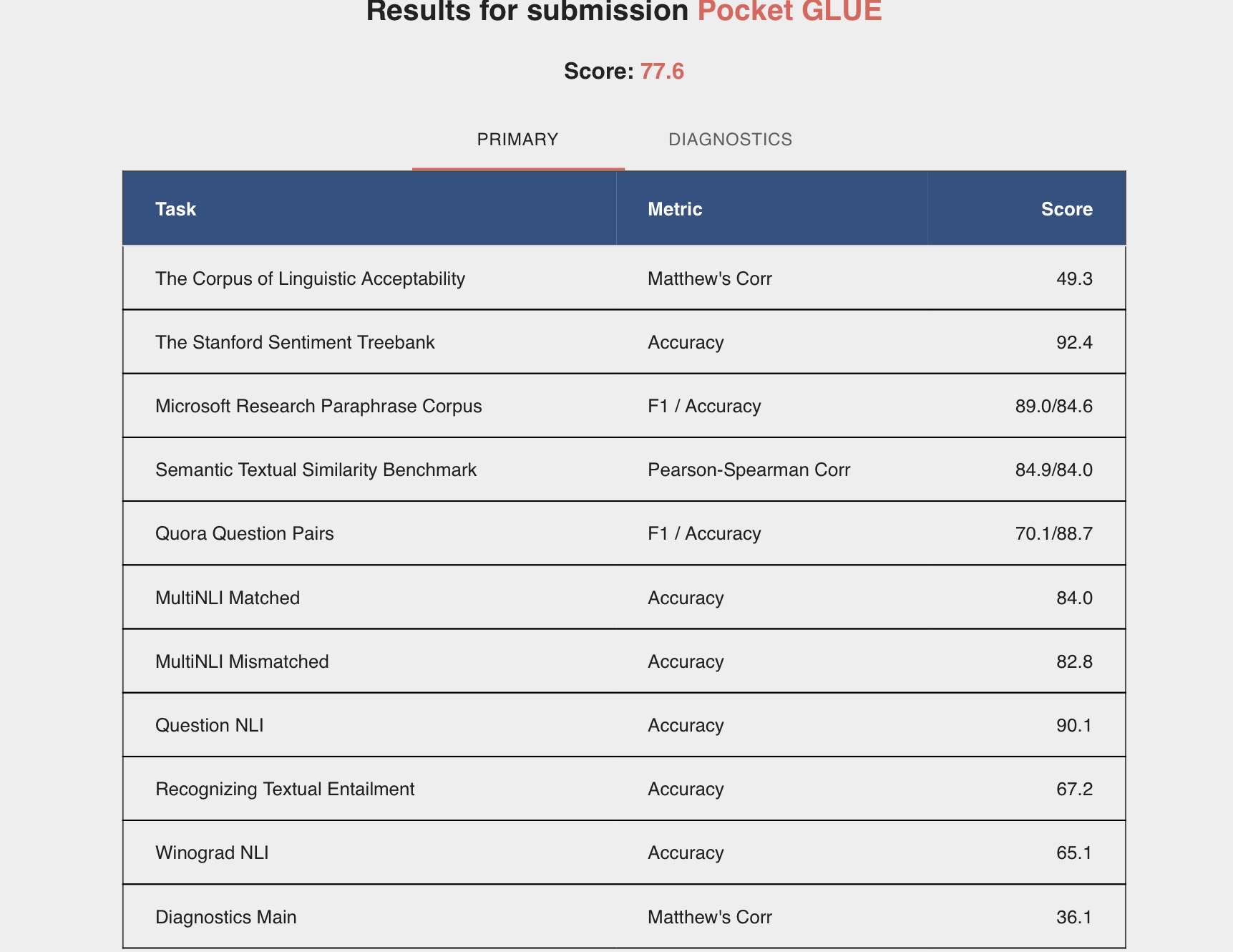
-
下载GLUE数据集,若不方便可从以下链接下载:
百度网盘 链接 提取码: 94jy 腾讯微云 链接 无提取码 -
下载bert预训练的权重(这里使用的是HuggingFace的bert)到指定文件夹;
-
代码组成。运行时配置好超参和环境之后直接
python main.py即可├── main.py ├── config.py ## 配置超参数 ├── load_data.py ## 加载GLUE的数据 ├── helper.py ## 设置随机种子 ├── requirements.txt ## 环境