-
Notifications
You must be signed in to change notification settings - Fork 93
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
5c7acc8
commit b39cf13
Showing
4 changed files
with
142 additions
and
12 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,106 @@ | ||
| --- | ||
| title: 别再被同质化的内容淹没!用 AI 克隆技术打造你独特的声音品牌! | ||
| date: 2023-10-07 | ||
| category: | ||
| - 工具 | ||
| tag: | ||
| - AI | ||
| - VITS | ||
| - 声音克隆 | ||
| order: -56 | ||
| --- | ||
|
|
||
| 每个人的声音都是独一无二的,克隆自己的声音可以用于制作高度个性化的内容,如播客、视频、音乐等。 | ||
|
|
||
| 你的声音是个人品牌的重要组成部分。利用人工智能,你可以不需要亲自录音就能生成大量优质音频内容,节省时间的同时确保内容质量和一致性。市场上虽有众多第三方语音生成技术,但它们大多数使用通用或他人的声音,导致内容缺乏个性化特质。例如,「注意看,这个男人叫小帅」的声音已经在众多影视作品中被重复使用。与之不同,AI 克隆技术能提供前所未有的个性化和定制体验。 | ||
|
|
||
| 艾什莉的播客就是一个典型例子,她利用 AI 生成了根据当日新闻热点定制的讲稿,再用 AI 克隆的自己的声音进行朗读,配上背景音乐,既经济又高效。 | ||
|
|
||
| <AudioPlayer src="https://oss.newzone.top/audio/clonevoice00.wav" title="克隆音频实例"/> | ||
|
|
||
| 我使用了 [VITS-fast-fine-tuning](https://github.com/Plachtaa/VITS-fast-fine-tuning) 来克隆我的声音。这款工具能从短音频、长音频或视频中克隆特定角色的声音,只需几小时即可完成预训练的 VITS 模型的微调。微调后的模型不仅能进行声线转换,还能完成中、日、英三种语言的文本到语音的转换。 | ||
|
|
||
| ## 收集语音样本 | ||
|
|
||
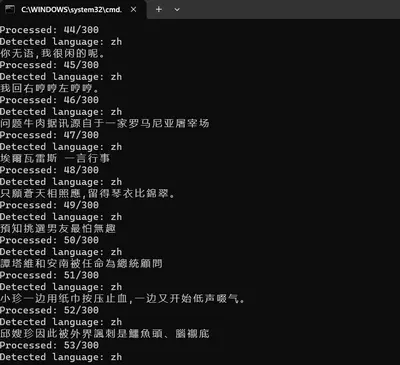
| 克隆声音的第一步是准备自己的声音样本。确保录音中只有你的声音,且语音清晰、语速均匀。录音完成后,需检查 `final_annotation` 等 txt 文件的音频转写情况,确认停顿和文字是否正确。 | ||
|
|
||
|  | ||
|
|
||
| 为增加语音样本的多样性,选择不同主题和领域的文本材料。我使用的文本来自[标贝数据集](https://weixinxcxdb.oss-cn-beijing.aliyuncs.com/gwYinPinKu/BZNSYP.rar),该数据集包含 10000 条文本和对应的读音。我选了 300 条用于短音频录制,每条录音时长在 2 至 10 秒之间。语料的质量优于数量,如果需要,可以减少语料条数或使用长视频。VITS-fast-fine-tuning 工具会自动将长音频剪切成短音频。 | ||
|
|
||
|  | ||
|
|
||
| ## 云端训练模型 | ||
|
|
||
| 关于模型的微调和部署,你可以参考官方 GitHub [页面](https://github.com/Plachtaa/VITS-fast-fine-tuning/blob/main/README_ZH.md)的详细操作指南。 | ||
|
|
||
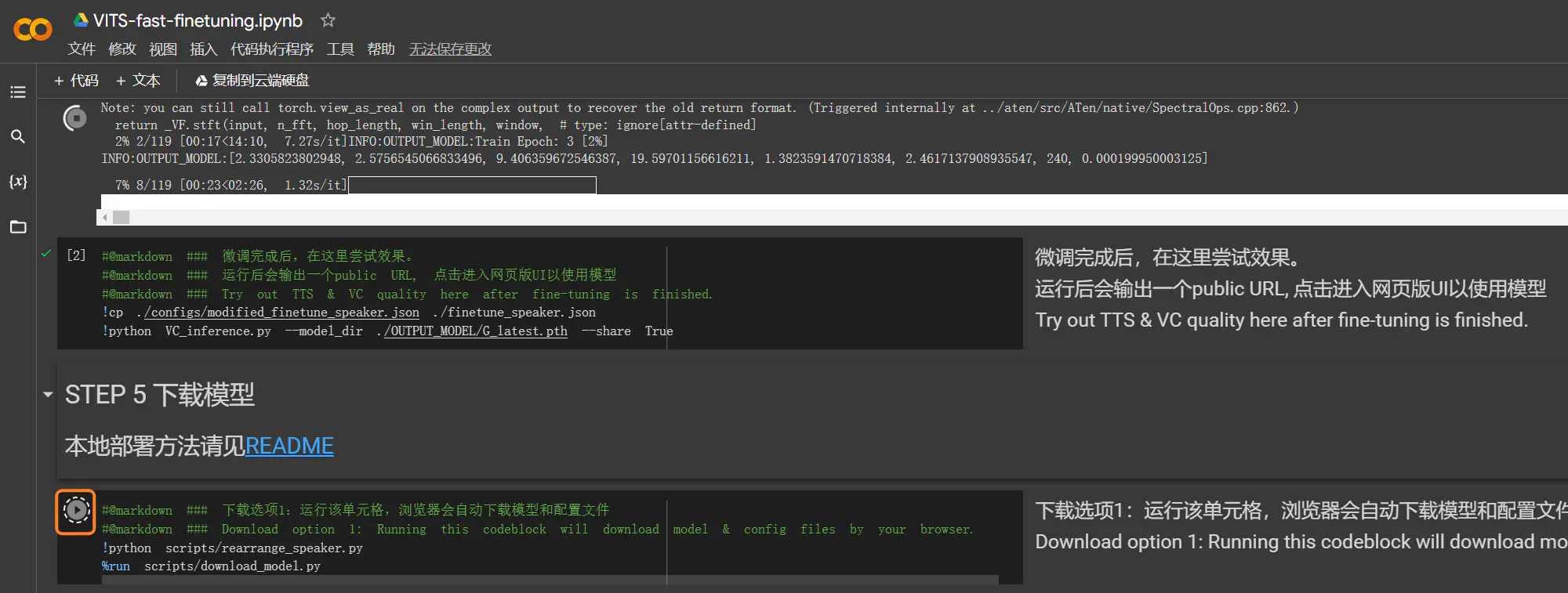
| 在 [Google Colab](https://colab.research.google.com/drive/1pn1xnFfdLK63gVXDwV4zCXfVeo8c-I-0?usp=sharing) 进行模型微调时,可能会因长时间未连接或超出免费配置限制而中断。为防止数据丢失,应提前选择「STEP 5 下载模型」的下载选项。在 Colab 进行云端训练时,建议长音频时长控制在 20 分钟以内,`max_epochs` 设置为 100。如需进一步提升模型质量,可继续训练模型,再进行 100 次 epochs。 | ||
|
|
||
|  | ||
|
|
||
| 我曾在 Colab 上用 8 分钟的 B 站视频进行训练,但三小时后由于超出免费额度被终止。后来我在配备了 3080Ti 的本地设备上进行训练,4 小时后便完成了调试。 | ||
|
|
||
| ## 本地训练模型 | ||
|
|
||
| 如果需要进行深入的模型调整,比如执行 5000 次 epochs,可能需要数天的时间。为此,你可以参考 [LOCAL.md](https://github.com/Plachtaa/VITS-fast-fine-tuning/blob/main/LOCAL.md) 来在本地环境进行训练。而针对其中可能存在的不明确部分,以下补充具体步骤和建议。 | ||
|
|
||
| - 第 0 步:预先确认本地环境的 Python 版本为 3.8,并且已经安装了 [Microsoft C++ 生成工具](https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/) 和 ffmpeg。这样可以预防潜在错误。在启动本地运行之前,执行 `pip install --upgrade numpy` 来更新 numpy 版本。 | ||
| - 第 6 步:鉴于 wget 下载命令在 Windows 中可能不起作用,建议手动下载 [sampled_audio4ft_v2.zip](https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/sampled_audio4ft_v2.zip),随后将文件解压至运行路径。 | ||
| - 第 7 步 (下载模型与配置): | ||
| - C 模型(纯中文):下载 HuggingFace 平台上的 [D_0.pth](https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/D_0.pth)、[G_0.pth](https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/G_0.pth) 和 [config.json](https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/config.json)。 | ||
| - CJ 模型(中日):下载 [D_0-p.pth](https://huggingface.co/spaces/zomehwh/vits-uma-genshin-honkai/resolve/main/model/D_0-p.pth)、[G_0-p.pth](https://huggingface.co/spaces/zomehwh/vits-uma-genshin-honkai/resolve/main/model/G_0-p.pth) 和 [config.json](https://huggingface.co/spaces/zomehwh/vits-uma-genshin-honkai/resolve/main/model/config.json)。 | ||
| - CJE 模型(中日英):下载 [D_trilingual.pth](https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/D_trilingual.pth)、[G_trilingual.pth](https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/G_trilingual.pth) 和 [uma_trilingual.json](https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/configs/uma_trilingual.json)。 | ||
| - 选择上方一种模型进行下载。完成下载后,将 G 模型重命名为 `G_0.pth`,将 D 模型重命名为 `D_0.pth`,并将配置文件 .json 重命名为 `finetune_speaker.json`。特别注意,要保证 json 文件是直接下载而非复制粘贴,以防后续步骤中打开 inference 出现问题。 | ||
| - 第 8 步:由于 LOCAL.md 教程中未包含在线视频,所以需要将相关视频文件下载到本地。 | ||
| - 第 9 步:运行以下命令: | ||
|
|
||
| ```shell | ||
| python scripts/video2audio.py | ||
| python scripts/denoise_audio.py | ||
|
|
||
| python scripts/long_audio_transcribe.py --languages C --whisper_size large-v2 | ||
| python scripts/short_audio_transcribe.py --languages C --whisper_size large-v2 | ||
|
|
||
| python scripts/resample.py | ||
| ``` | ||
|
|
||
| - 第 10 步:执行 `python preprocess_v2.py --add_auxiliary_data True --languages C`。 | ||
| - 第 11 步: | ||
| - 开始训练:`python finetune_speaker_v2.py -m ./OUTPUT_MODEL --max_epochs 5000 --drop_speaker_embed True`。 | ||
| - 如果训练过程中断,要继续训练,执行 `python finetune_speaker_v2.py -m ./OUTPUT_MODEL --max_epochs 10000 --drop_speaker_embed False --cont True`。 | ||
|
|
||
|  | ||
|
|
||
| ## 语音生成 | ||
|
|
||
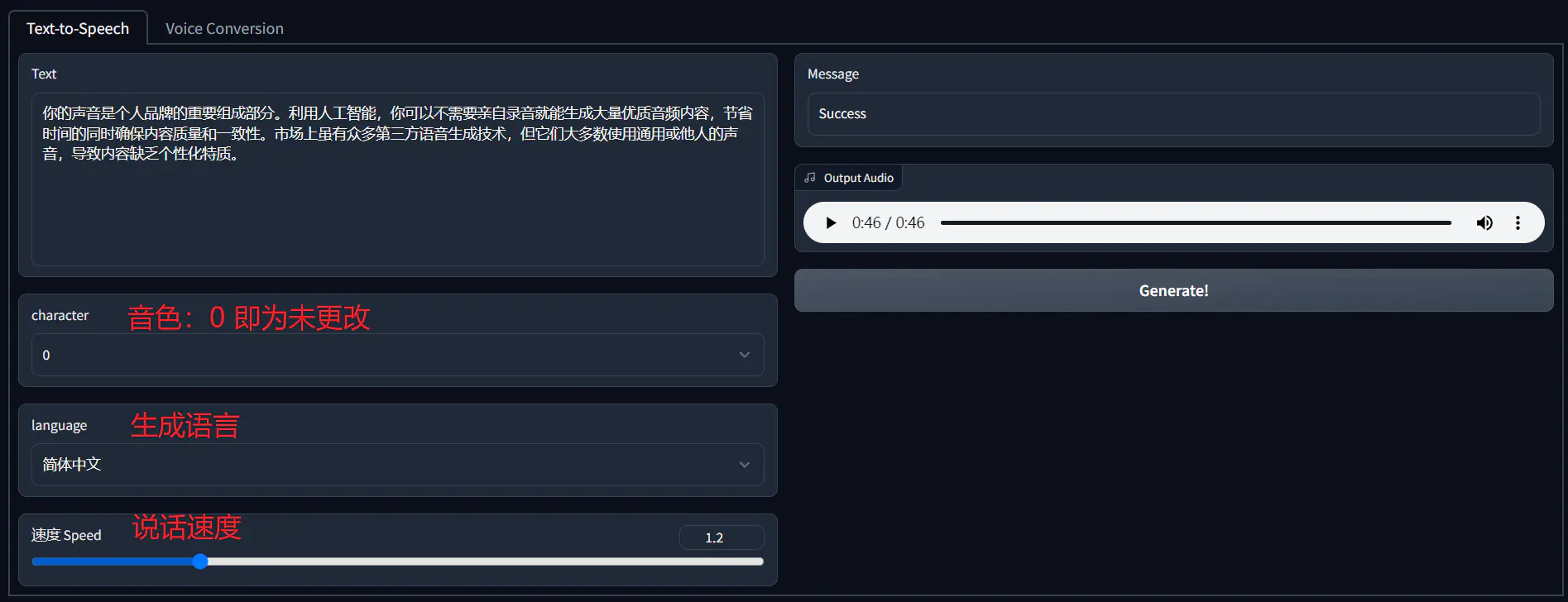
| 微调完成后,你可以下载微调好的模型和语音生成工具 [inference](https://github.com/Plachtaa/VITS-fast-fine-tuning/releases),在本地环境下生成个性化的语音内容。 | ||
|
|
||
|  | ||
|
|
||
| 在这个阶段,特别注意中文模型(即 languages C)的 `finetune_speaker.json` 格式问题。确保「speaks」部分被修改为字典格式,否则在运行 inference 时,你可能会遇到 `File "inference.py", line 99` 的报错。为方便,你可以直接点击[这里](https://wwva.lanzouq.com/iIy5m1b4bosf)下载我调整好的 json 文件。 | ||
|
|
||
| ## 常见问题 | ||
|
|
||
| ### 语音克隆的「口音」问题 | ||
|
|
||
| > 每个人的声音都是独一无二的,克隆自己的声音可以用于制作高度个性化的内容。 | ||
| 示例音频:<AudioPlayer src="https://oss.newzone.top/audio/clonevoice01.wav" title="克隆音频实例 2" /> | ||
|
|
||
| 这个示例是使用 8 分钟 B 站视频和 CJE 模型训练出的。但你可能注意到了明显的断调口音问题,仿佛一个日本人在说中文。正如 @zachx121 指出的,「CJE 用的时候 romaji 的注音,就好比说用汉语拼音去标注英文单词的发音一样会有“口音”」。为了避免这个问题,可以使用纯中文设计的 C 模式进行训练和生成,以确保音频的自然和准确性。增加训练次数也有助于改善口音问题。 | ||
|
|
||
| ### 无法启动 inference | ||
|
|
||
| 如果你遇到无法启动 inference 的问题,通常是因为 `finetune_speaker.json` 配置文件有问题。确保你下载的 json 文件是对应的版本,并且格式完整。如果问题仍然存在,可以考虑使用 `configs/modified_finetune_speaker.json` 文件替代原有配置文件,通常这样可以解决运行中出现的错误。 | ||
|
|
||
| ### 长音频识别问题 | ||
|
|
||
| 要注意,长音频需要采用 wav 格式。即即使原本为 mp3 格式的音频文件在后期转为 wav,也可能出错。因此,直接使用 wav 格式进行长音频录制或选择是更好的做法。 | ||
|
|
||
| ### 录音中出现 zh | ||
|
|
||
| 在使用纯中文模式调试时,音频前后可能会标注当前语言,例如,中文语言中出现 ZH 标注。为去除这些不必要的语言标注,可以将生成语言设置为 `Mix`模式。 | ||
|
|
||
| ## 最后 | ||
|
|
||
| 声音不仅仅是交流的工具,它还代表了个人品牌的一部分。AI 和声音克隆技术的联合运用,让你能快速、高效地生成具有个性特色的音频内容,拥有更多未来的可能。 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,30 @@ | ||
| --- | ||
| article: false | ||
| title: MT Photos:分享家庭照片 | ||
| order: 3 | ||
| --- | ||
|
|
||
| [MT Photos](https://mtmt.tech/) 是一款专为 Nas 用户设计的照片管理系统。它能自动整理和分类您的照片,包括按时间、地点、人物和照片类型分类。MT Photos 可在任何支持 Docker 的系统上运行,Windows 用户也可以直接运行服务端程序。一次性付费 99 元即可永久使用,系统将每周自动检查授权状态。其中一个突出的特点是支持通过网页分享特定的图片影集,这使得将大量宝宝照片分享给家人变得方便快捷。 | ||
|
|
||
| ```yml | ||
| version: "3" | ||
|
|
||
| services: | ||
| mtphotos: | ||
| image: mtphotos/mt-photos:latest | ||
| container_name: mtphotos | ||
| restart: always | ||
| ports: | ||
| - 8063:8063 | ||
| - 8163:8163 | ||
| volumes: | ||
| - /volume1/docker/MTphotos/config:/config | ||
| - /volume3/Pictures/upload:/upload | ||
| - /volume3/Pictures/photos:/photos | ||
| environment: | ||
| - TZ=Asia/Shanghai | ||
| - SSL_NAME=home.newzone.top | ||
| - MT_SERVER_SSL_PORT=8163 | ||
| ``` | ||
| 我在使用 MT Photos 时发现,视频播放可能需要全屏模式才能正常播放,尽管其他用户反馈视频播放功能正常。 |