Ambari service for easily installing and managing Apache Zeppelin on HDP cluster
Author: Ali Bajwa
Special thanks: Prabhjyot Singh for adding install via rpm in HDP 2.4
Zeppelin is now officially available via Ambari in HDP 2.5 so as of this release this project is not longer needed. Official Zeppelin Ambari service code can be found in Apache github here
- Quick start
- Option 1: Deploy Zeppelin on existing cluster/sandbox - Setup Pre-requisites - Setup YARN queue - Setup Ambari service - Configure Zeppelin
- Option 2: Automated deployment of a fresh HDP cluster that includes Zeppelin (via blueprints)
- Getting started with Zeppelin after deployment:
- Other:
- HDP 2.4.x with at least HDFS, YARN, Zookeper, Spark installed. Hive installation is optional. Instructions for older releases available here
- Have 2 ports available and open for zeppelin and its websocket. These will be defaulted to 9995/9996 (but can be configured in Ambari). If using sandbox on VirtualBox, you need to manually forward these.
- Automates deployment, configuration, management of zeppelin 0.5.6 on HDP cluster
- Runs zeppelin in yarn-client mode (instead of standalone). Why is this important?
- Multi-tenancy: The service autodetects and configures Zeppelin to point to default Spark YARN queue. Users can use this, in conjunction with the Capacity scheduler/YARN Queue Manager view, to set what percentage of the clusters resources get allocated to Spark.
- Security: Ranger YARN plugin can be used to setup authorization policies on which users/groups are allowed to submit spark jobs. Both allowed requests and rejections can also be audited in Ranger.
- Supports both default HDP Spark version (e.g. 1.6.0 with HDP 2.4.x)
- Automates deployment of Ambari view to bring up Zeppelin webapp (requires manual ambari-server restart)
- Runs zeppelin as configurable user (by default zeppelin), instead of root
- Uploads zeppelin jar to /apps/zeppelin location in HDFS to be accessible from all nodes in cluster
- Exposes the zeppelin-site.xml and zeppelin-env.sh files in Ambari for easy configuration
- Deploys sample notebooks from Hortonworks Gallery that demo hive, spark and sparksql, shell intepreters
- Use Ambari APIs to autodetect and configure Zeppelin interpreter to point to:
- HiveServer2 to enable Zeppelin hive interpreter (if Hive is installed)
- Hive metastore so Spark commands can access Hive tables out of the box (if Hive is installed)
- Phoenix JDBC connect url to enable Zeppelin Phoenix interpreter (if Hbase is installed).
- Offline install using local repo
- This is not an officially supported service and is not meant to be deployed in production systems. It is only meant for testing demo/purposes
- It does not support Ambari/HDP upgrade process and will cause upgrade problems if not removed prior to upgrade
- Only tested on CentOS/RHEL 6 so far
- Does not yet support install on secured (kerborized) clusters
- Unless otherwise configured, Zeppelin view will be setup using internal hostname, so you would need to have a corresponding hosts file entry on local machine to access.
- Use 'public name' property of 'Advanced zeppelin-ambari-config' to change this on cloud setups
- After install, Ambari thinks HDFS, YARN, Hive, HBase need restarting (seems like Ambari bug)
- These steps were tested on:
- HDP 2.4.x cluster installed via Ambari 2.2.0 (comes with Spark 1.6.0) on Centos 6.
- Latest HDP 2.4.x sandbox (comes with Spark 1.6.0) on Centos 6.
- There are two options to deploy Zeppelin from Ambari:
- Download HDP 2.4.x sandbox VM image (Hortonworks_sanbox_with_hdp_2_4_virtualbox.ova) from Hortonworks website
- Import Hortonworks_sanbox_with_hdp_2_4_virtualbox.ova into VMWare and set the VM memory size to 8GB
- Now start the VM
- After it boots up, find the IP address of the VM and add an entry into your machines hosts file e.g.
192.168.191.241 sandbox.hortonworks.com sandbox
- Connect to the VM via SSH (password hadoop)
-
If you deployed in a VirtualBox Sandbox environment, enable port forwarding on ports 9995 and 9996. If you don't enable port 9996, the Zeppelin UI/Ambari View shows disconnected on the upper right and none of the default tutorials are visible.
-
Ensure Spark is installed. If not, use Add service wizard to install Spark. You can also bring down services that are not used by this tutorial (like Oozie/Falcon) and, additionally, install Hive if you want to leverage from Hive tables in Zeppelin Notebook.
-
(Optional) You can setup/configure a YARN queue to customize what portion of the cluster the Spark job should use. To do this follow the two steps below:
i. Open the Yarn Queue Manager view to setup a queue for Spark with below capacities:
- Capacity: 50%
- Max Capacity: 90% (on sandbox, do not reduce below this or the Spark jobs will not run)

ii. In Ambari under Spark > Configs, set the default queue for Spark. The Zeppelin Ambari service will autodetect this queue and configure Zeppelin to use the same.



- To deploy the Zeppelin service, run below on ambari server
VERSION=`hdp-select status hadoop-client | sed 's/hadoop-client - \([0-9]\.[0-9]\).*/\1/'`
sudo git clone https://github.com/hortonworks-gallery/ambari-zeppelin-service.git /var/lib/ambari-server/resources/stacks/HDP/$VERSION/services/ZEPPELIN
- Restart Ambari
#on sandbox
service ambari restart
#on non-sandbox
sudo service ambari-server restart
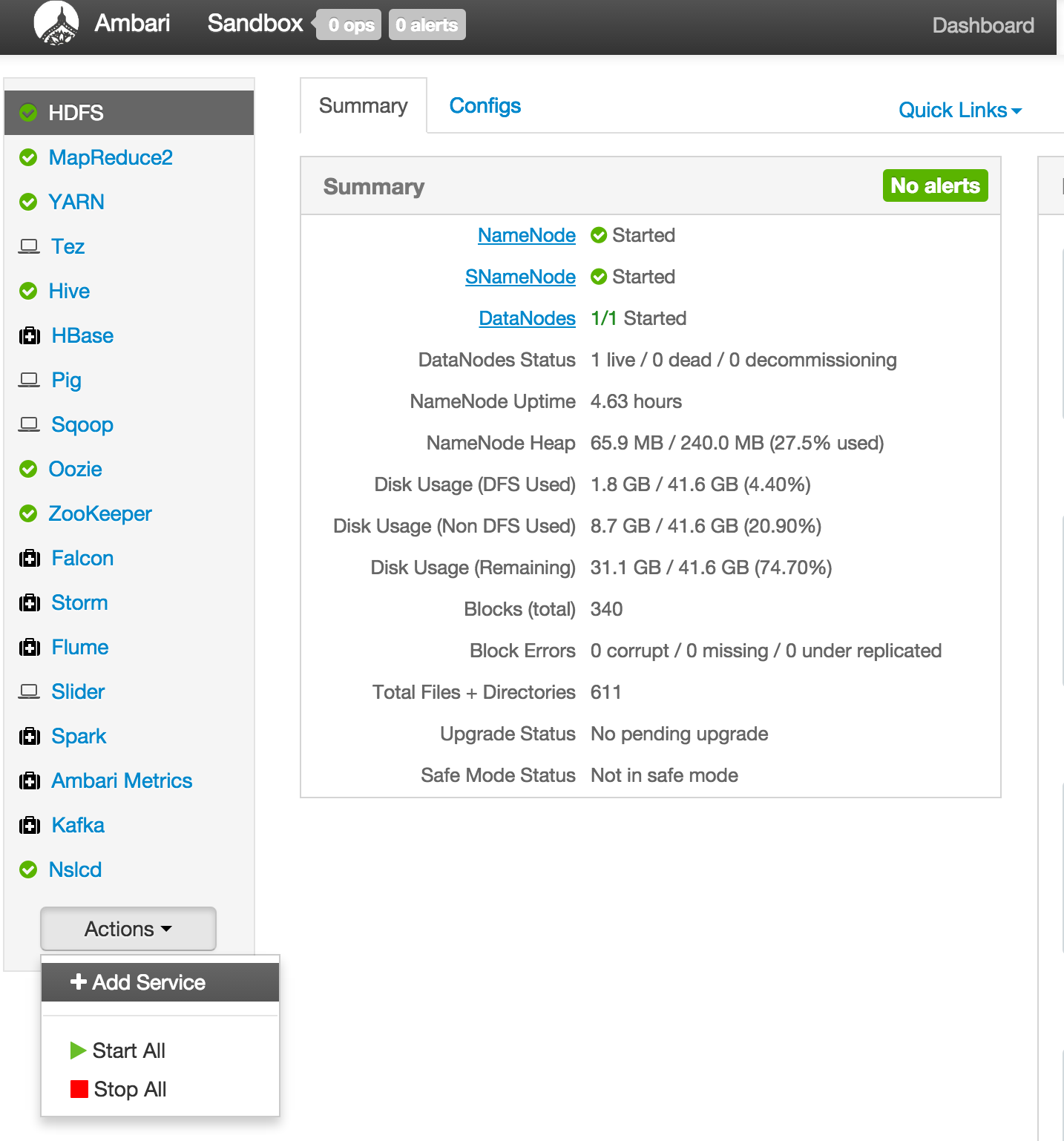
- Once Ambari comes back up and the services turn green, you can click on 'Add Service' from the 'Actions' dropdown menu in the bottom left of the Ambari dashboard:
On bottom left -> Actions -> Add service -> check Zeppelin service -> Next -> Next -> Next -> Deploy.

-
This will bring up the Customize Services page where you can configure the Zeppelin service. Note that default configurations will work fine on sandbox.

-
There are three sections of configuration:
-
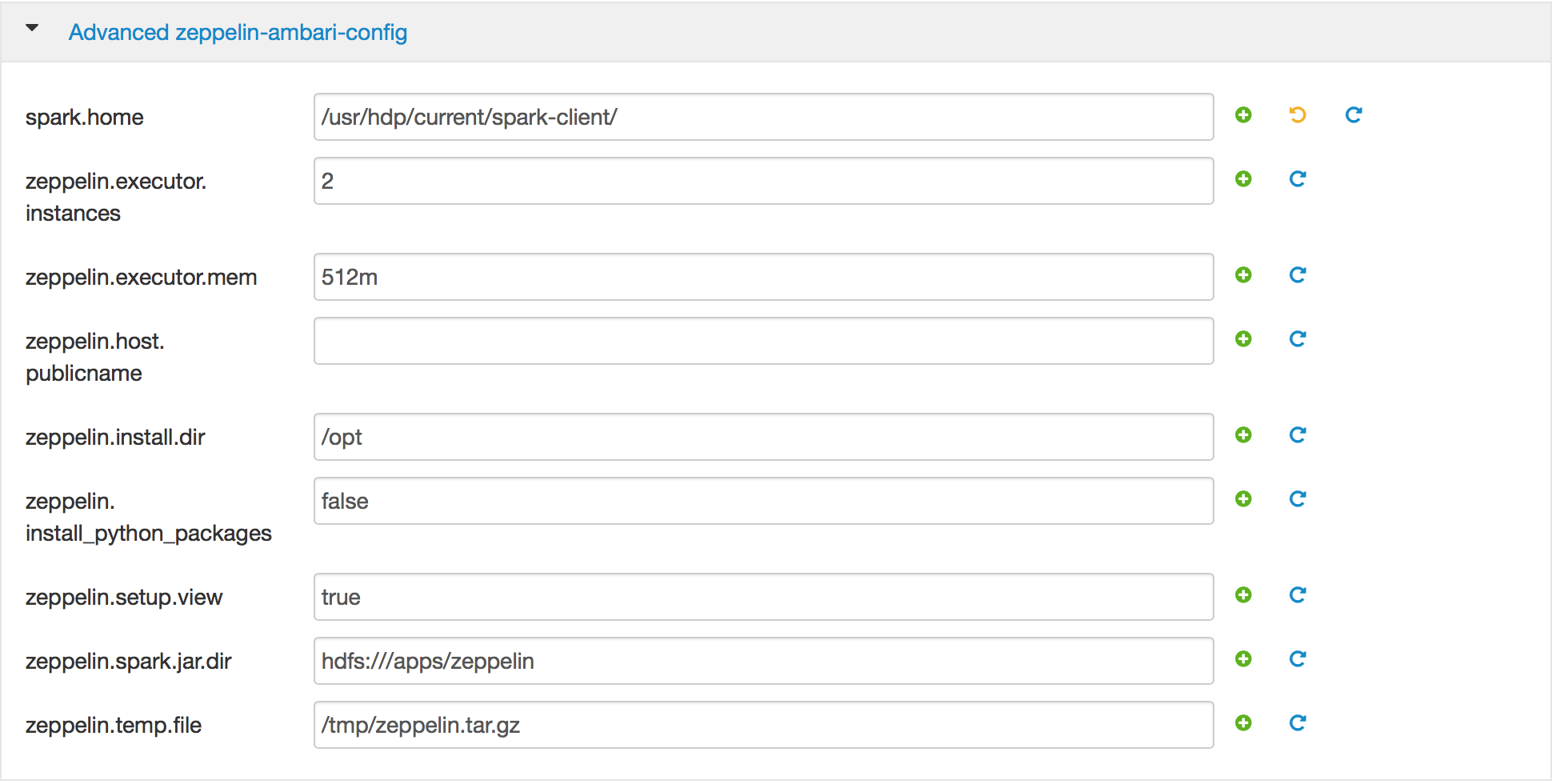
i) Advanced zeppelin-ambari-config: Parameters specific to Ambari service only (will not be written to zeppelin-site.xml or zeppelin-env.sh)
-
install dir: Local dir under which to install component
-
setup prebuilt: If true, will download previously built package (instead of building from source). To compile from source instead, set to false. If cluster does not have internet access, manually copy the tar.gz to /tmp/zeppelin.tar.gz on Ambari server and set this property to true.
-
setup view: Whether the Zeppelin view should be compiled. Set to false if cluster does not have internet access
-
spark jar dir: Shared location where zeppelin spark jar will be copied to. Should be accesible by all cluster nodes. Its possible to manually host this on object store. For example to point this to WASB, you can set this to
wasb:///apps/zeppelin -
executor memory: Executor memory to use (e.g. 512m or 1g)
-
temp file: Temporary file where pre-built package will be downloaded to. If your env has limited space under /tmp, change this to different location. In this case you must ensure that the zeppelin user must be able to write to this location.
-
public name: This is used to setup the Ambari view for Zeppelin. Set this to the public host/IP of zeppelin node (which must must be reachable from your local machine). If installing on sandbox (or local VM), change this to the IP address of VM. If installing on cloud, set this to public name/IP of zeppelin node. Alternatively, if you already have a local hosts file entry for the internal hostname of the zeppelin node (e.g. sandbox.hortonworks.com), you can leave this empty - it will default to internal hostname
-
spark home: Spark home directory. Defaults to the Spark that comes with HDP (e.g. 1.6.0 with HDP 2.4.x). To point Zeppelin to different Spark build, change this to location of where you downloaded Spark to (e.g./usr/hdp/2.3.4.0-3485/spark/). The service will detect the version of spark installed here (via RELEASE file) and pull appropriate prebuilt Zeppelin package
-
python packages: (Optional) (CentOS only) - Set this to true to install numpy scipy pandas scikit-learn. Note that selecting this option will increase the install time by 5-10 min depending on your connection. Can leave false if not needed, but note that the sample pyspark notebook will not work without it
-
Sample settings for using the Spark that came installed with HDP (no changes needed if you already created the hosts file entry for sandbox.hortonworks.com)

-
Sample settings if you installed custom Spark (e.g. assuming you manually installed spark 1.5 as described above):
- set
spark.home=/usr/hdp/current/spark/
- set
-
-
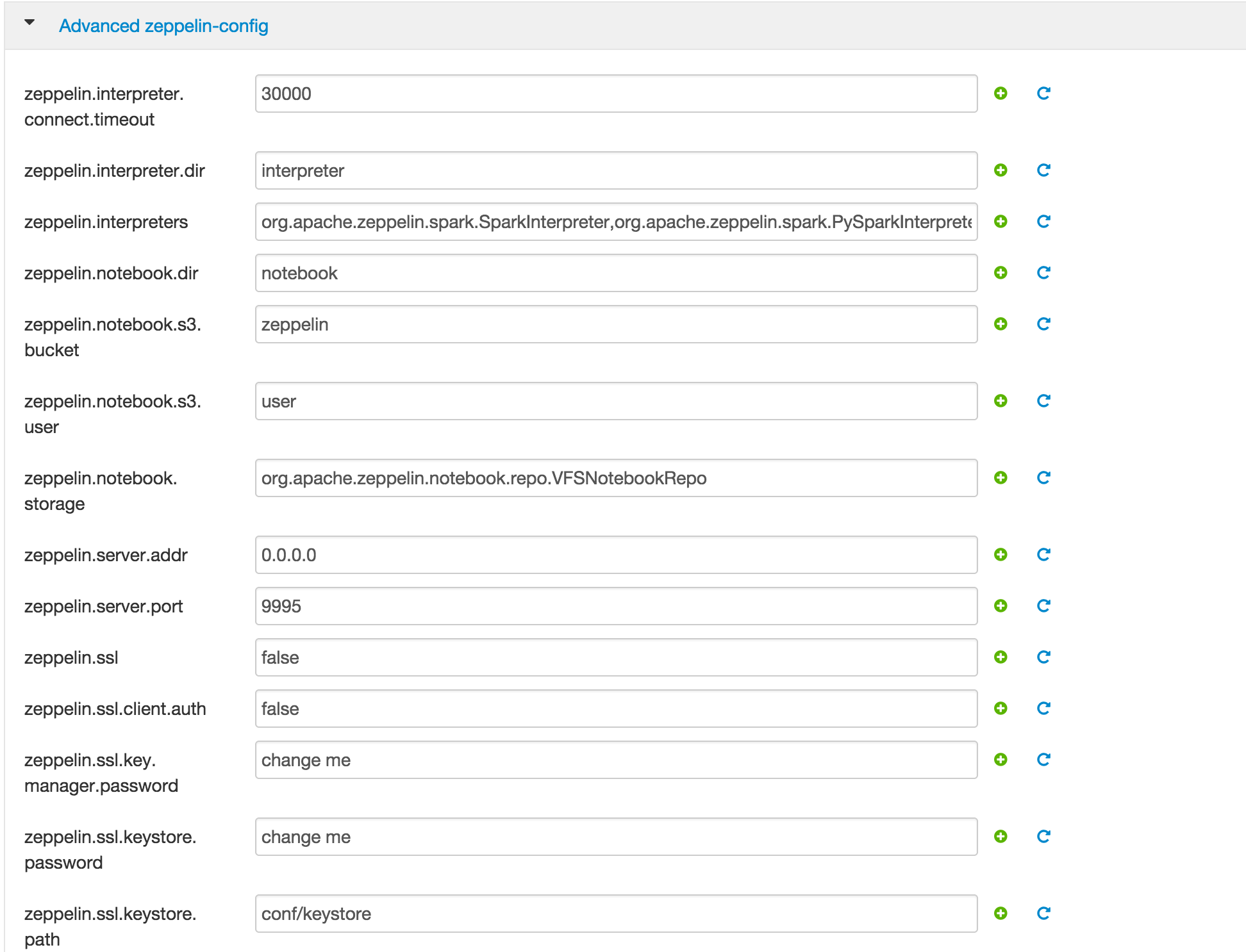
ii) Advanced zeppelin-config: Used to populate zeppelin-site.xml
- If needed you can modify the zeppelin ports here (default to 9995,9996)

- If needed you can modify the zeppelin ports here (default to 9995,9996)
-
iii) Advanced zeppelin-env: Used to populate zeppelin-env.sh. See Zeppelin docs for more info
- Under
export ZEPPELIN_JAVA_OPTSnotice that the Spark jobs will by default be sent to the default spark queue-Dspark.yarn.queue={{spark_queue}}. - To have Zeppelin jobs submitted to a different queue instead, just change to
-Dspark.yarn.queue=my_zeppelin_queuename(based on your queue name)
- Under
-
-
Click Next to accept defaults...

-
Click Deploy to start the installation


Note that:
-
The default mode of the service sets up Zeppelin in yarn-client mode by downloading a tarball of precompiled bits (ETA: < 5min)
-
(Optional) To instead pull/compile the latest Zeppelin code from the git page (ETA: < 40min depending on internet connection):
- While adding zeppelin service, in the configuration step of the wizard:
- set zeppelin.setup.prebuilt to false
- While adding zeppelin service, in the configuration step of the wizard:
-
To track the progress of the install you can run the below:
tail -f /var/log/zeppelin/zeppelin-setup.log
-
On successful deployment you will see the Zeppelin service as part of Ambari stack and will be able to start/stop the service from here:

-
You can see the parameters you configured under 'Configs' tab

-
Now you can skip to the section on 'Getting started with Zeppelin'


-
Sample steps below for installing a 4-node HDP cluster that includes Zeppelin, using Ambari blueprint and Ambari boostrap
-
Pre-reqs: Bring up 4 VMs imaged with RHEL/CentOS 6.x (e.g. called node1-4 in this case)
-
On non-ambari nodes (e.g. nodes2-4), use bootstrap script to run pre-reqs, install ambari-agents and point them to ambari node (e.g. node1 in this case)
export ambari_server=node1
curl -sSL https://raw.githubusercontent.com/seanorama/ambari-bootstrap/master/ambari-bootstrap.sh | sudo -E sh
- On Ambari node (e.g. node1), use bootstrap script to run pre-reqs and install ambari-server
export install_ambari_server=true
curl -sSL https://raw.githubusercontent.com/seanorama/ambari-bootstrap/master/ambari-bootstrap.sh | sudo -E sh
yum install -y git
git clone https://github.com/hortonworks-gallery/ambari-zeppelin-service.git /var/lib/ambari-server/resources/stacks/HDP/2.3/services/ZEPPELIN
sed -i.bak '/dependencies for all/a \ "ZEPPELIN_MASTER-START": ["NAMENODE-START", "DATANODE-START"],' /var/lib/ambari-server/resources/stacks/HDP/2.3/role_command_order.json
- Restart Ambari
service ambari-server restart
service ambari-agent restart
- Confirm 4 agents were registered and agent remained up
curl -u admin:admin -H X-Requested-By:ambari http://localhost:8080/api/v1/hosts
service ambari-agent status
- (Optional) - In general, you can generate BP and cluster file using Ambari recommendations API using these steps. However in this example we are providing some sample blueprints which you can edit, so this is not needed. These for reference only For more details, on the bootstrap scripts see bootstrap script git
yum install -y python-argparse
git clone https://github.com/seanorama/ambari-bootstrap.git
#optional - limit the services for faster deployment
#for minimal services
export ambari_services="HDFS MAPREDUCE2 YARN ZOOKEEPER HIVE ZEPPELIN SPARK"
#for most services
#export ambari_services="ACCUMULO FALCON FLUME HBASE HDFS HIVE KAFKA KNOX MAHOUT OOZIE PIG SLIDER SPARK SQOOP MAPREDUCE2 STORM TEZ YARN ZOOKEEPER ZEPPELIN"
export deploy=false
cd ambari-bootstrap/deploy
bash ./deploy-recommended-cluster.bash
cd tmpdir*
#edit the blueprint to customize as needed. You can use sample blueprints provided below to see how to add the custom services.
vi blueprint.json
#edit cluster file if needed
vi cluster.json
- Download either minimal or full blueprint for 4 node setup
#Pick one of the below blueprints
#for minimal services download this one
wget https://raw.githubusercontent.com/hortonworks-gallery/ambari-zeppelin-service/master/blueprint-4node-zeppelin-minimal.json -O blueprint-zeppelin.json
#for most services download this one
wget https://raw.githubusercontent.com/hortonworks-gallery/ambari-zeppelin-service/master/blueprint-4node-zeppelin-all.json -O blueprint-zeppelin.json
- If running on single node, download minimal blueprint for 1 node setup
#Pick one of the below blueprints
#for minimal services download this one
wget https://raw.githubusercontent.com/hortonworks-gallery/ambari-zeppelin-service/master/blueprint-1node-zeppelin-minimal.json -O blueprint-zeppelin.json
- (optional) If needed, change the Zeppelin configs based on your setup by modifying these lines
vi blueprint-zeppelin.json
-
if deploying on public cloud, you will want to add
"zeppelin.host.publicname":"<public IP or hostname of zeppelin node>"so the Zeppelin Ambari view is pointing to external hostname (instead of the internal name, which is the default) -
Upload selected blueprint and download a sample cluster.json that provides your host FQDN's. Modify the host FQDN's in the cluster.json file your own env. Finally deploy cluster and call it zeppelinCluster
#upload the blueprint to Ambari
curl -u admin:admin -H X-Requested-By:ambari http://localhost:8080/api/v1/blueprints/zeppelinBP -d @blueprint-zeppelin.json
- download sample cluster.json
#for 4 node setup
wget https://raw.githubusercontent.com/hortonworks-gallery/ambari-zeppelin-service/master/cluster-4node.json -O cluster.json
#for single node setup
wget https://raw.githubusercontent.com/hortonworks-gallery/ambari-zeppelin-service/master/cluster-1node.json -O cluster.json
- modify the host FQDNs in the cluster json file with your own. Also change the default_password to set the password for hive
vi cluster.json
- deploy the cluster
curl -u admin:admin -H X-Requested-By:ambari http://localhost:8080/api/v1/clusters/zeppelinCluster -d @cluster.json
-
You can monitor the progress of the deployment via Ambari (e.g. http://node1:8080).
-
Once install completes, you will have a 4 node HDP cluster including Zeppelin
-
Now you can proceed to the section on 'Getting started with Zeppelin'
-
If Zeppelin was installed on the Ambari server host, simply restart Ambari server
-
Otherwise copy the zeppelin view jar from
/home/zeppelin/zeppelin-view/target/zeppelin-view-1.0-SNAPSHOT.jaron zeppelin node, to/var/lib/ambari-server/resources/views/dir on Ambari server node. Then restart Ambari server -
Now the Zeppelin view should appear under views: http://sandbox.hortonworks.com:8080/#/main/views
-
Troubleshooting: By default the view will be setup using the
hostname -fentry of host where zeppelin will be installed. If the corresponding url(e.g. http://:9995) is not reachable from your local browser, you can either:- create entry in your local hosts file for the internal hostname of the zeppelin node or
- reconfigure the view to point to a different url using steps below:
#on node where zeppelin is running
su zeppelin
cd /home/zeppelin/zeppelin-view
#change the url to one that you can successfully open zeppelin using
vi src/main/resources/index.html
mvn clean package
#Now copy the zeppelin view jar from `/home/zeppelin/zeppelin-view/target/zeppelin-view-1.0-SNAPSHOT.jar` on zeppelin node, to `/var/lib/ambari-server/resources/views/` dir on Ambari server node.
#Then restart Ambari server
-
Lauch the notebook either via navigating to http://sandbox.hortonworks.com:9995 or via the view by opening http://sandbox.hortonworks.com:8080/#/main/views/ZEPPELIN/1.0.0/INSTANCE_1 should show Zeppelin as Ambari view

-
There should be a few sample notebooks created. Select the Hive one (make sure Hive service is installed and started first)
-
On first launch of a notebook, you will the "Interpreter Binding" settings will be displayed. You will need to click "Save" under the interpreter order.

-
Now you will see the list of executable cells laid out in a sequence

-
Execute the cells one by one, by clicking the 'Play' (triangular) button on top right of each cell or just highlight a cell then press Shift-Enter
-
Next try the same demo using the Spark/SparkSQL notebook (highlight a cell then press Shift-Enter):

- The first invocation takes some time as the Spark context is launched. You can tail the interpreter log file to see the details.


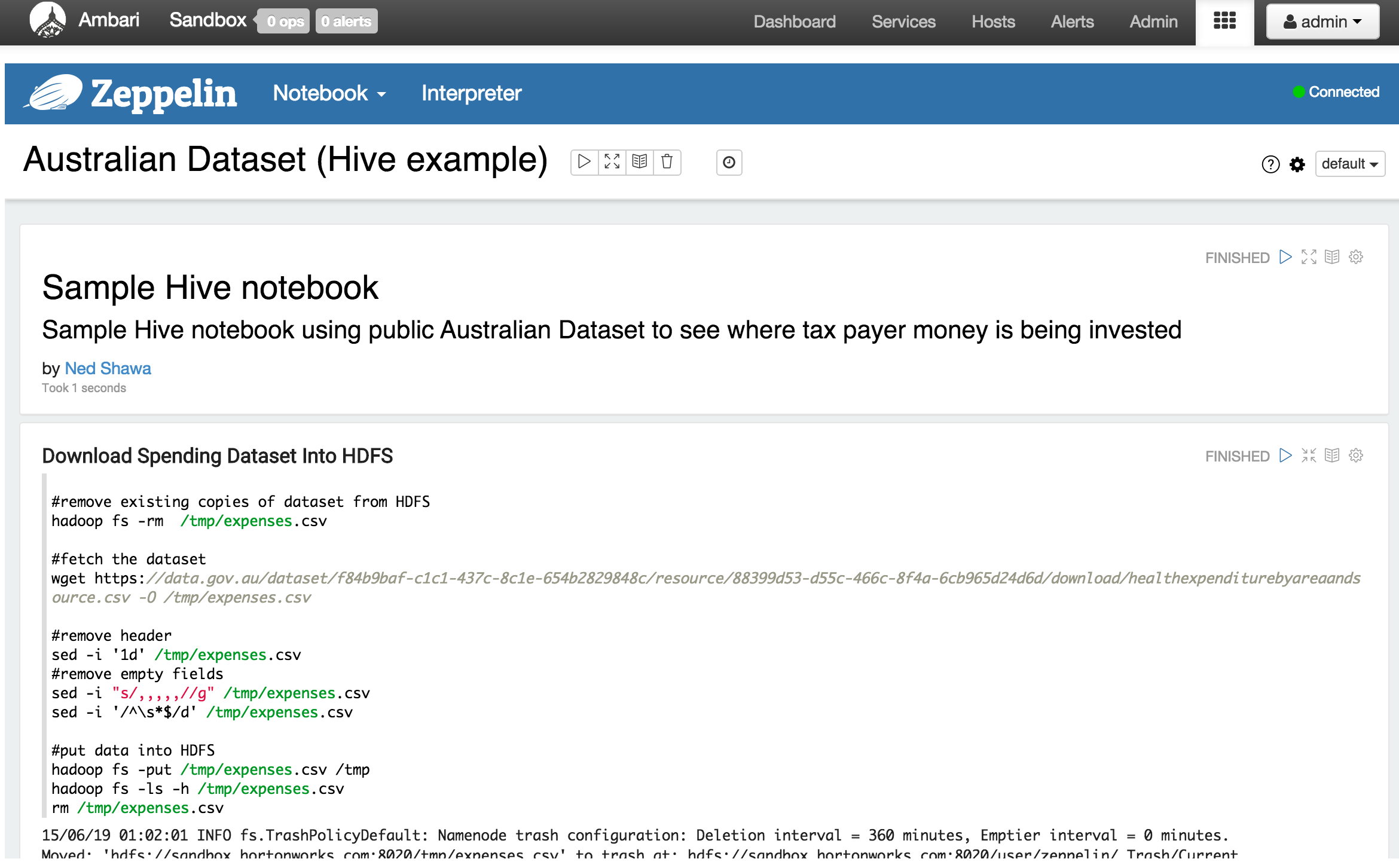

tail -f /var/log/zeppelin/zeppelin-zeppelin-sandbox.hortonworks.com.out
-
Now try the AON Demo for an example of displaying data on a map

- Once the Spark notebook has completed, you can restart the Spark interpreter via 'Interpreter' tab to free up cluster resources
-
Start Hbase via Ambari and run the Phoenix notebook (make sure HBase is started and Phoenix is enabled/installed first)
- To check if Phoenix client is installed, run below on Zeppelin node and ensure below dir is not empty

ls /usr/hdp/current/phoenix-client/*
-
If Phoenix is not installed, follow the below to install:
- In Ambari, under Hbase > Configs > Settings > Phoenix SQL > Enabled
- Stop Hbase and then start Hbase to invoke the Phoenix install
-
Once setup, you should be able to run through the sample Phoenix notebook

-
Other things to try
-
Access hive tables from SparkSql
- If Hive metastore is installed/started, you should be able to run queries against Hive tables from SparkSql
-
If you installed the optional python packages, you can run the pyspark notebook
-
Test settings by checking the spark version and spark home, python path env vars.
-

sc.version
sc.getConf.get("spark.home")
System.getenv().get("PYTHONPATH")
System.getenv().get("SPARK_HOME")
-
For exmaple for Spark 1.6,
sc.versionshould returnString = 1.6.0andSPARK_HOMEshould be/usr/hdp/2.4.0.0-169/spark(or whatever you set) -
To enable Dependency loading (e.g. loading jars or maven repo/artifacts) or create a form in your notebook, see Zeppelin docs
- Open the ResourceManager UI by opening http://sandbox.hortonworks.com:8088/cluster and notice that:
- Spark (and Tez) jobs launched by Zeppelin are running on YARN
- Assuming you setup the spark queue above, Spark job should be running on spark queue
- Hive/Tez job is running on default queue

- To access the Spark UI, you can click on the ApplicationMaster link in YARN UI:

-
Use the scheduler link to validate the proportion of the cluster used by Spark/Tez. For example, if you setup the Spark YARN queue as above, when only Spark is running, the UI will show Spark taking up 89% of the cluster

-
The Ambari metrics on the main Ambari dashboard will show the same:

-
You can also use this YARN UI for troubleshooting hanging jobs. For example if Hive job is stuck waiting for Spark to give up YARN resources (or vice versa), you can restart the Spark interpreter via Zeppelin before running the Hive query
-
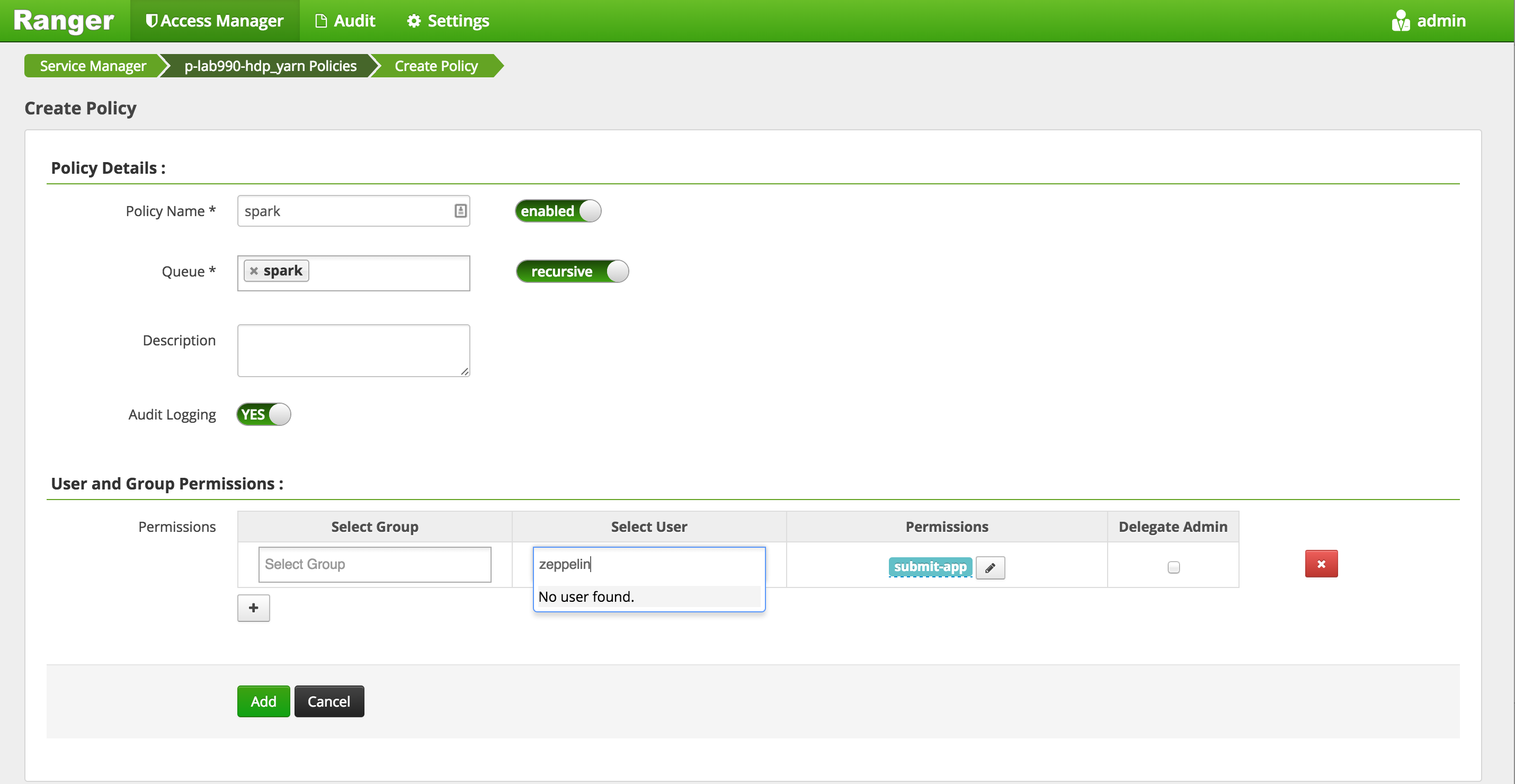
The other benefit to setting up dedicated queue for Spark is that you can bring up Ranger (http://sandbox.hortonworks.com:6080) and install the Ranger YARN plugin to set authorization policies of which users/groups are allowed to submit Spark jobs, and also see audits of who was allowed or denied access. These user/groups can synced with the corporate identity management system or LDAP.
- For more details: see sample steps to setup Ranger's YARN plugin and setup YARN queue and Ranger policy on an Ambari installed HDP 2.3 cluster.
- Note: on the current version of HDP 2.3 sandbox, Ranger YARN plugin has not been setup
- Screenshot of how you would create a Ranger policy for 'zeppelin' user to access 'spark' YARN queue:


- Don't want to take our word for the benefits of Spark on YARN? Check this Spark Summit talk by Kelvin Chi (Uber)
- One benefit to wrapping the component in Ambari service is that you can now monitor/manage this service remotely via REST API
export SERVICE=ZEPPELIN
export PASSWORD=admin
export AMBARI_HOST=sandbox.hortonworks.com
export CLUSTER=Sandbox
#get service status
curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' -X GET http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER/services/$SERVICE
#start service
curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context" :"Start $SERVICE via REST"}, "Body": {"ServiceInfo": {"state": "STARTED"}}}' http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER/services/$SERVICE
#stop service
curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context" :"Stop $SERVICE via REST"}, "Body": {"ServiceInfo": {"state": "INSTALLED"}}}' http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER/services/$SERVICE
Even if you do not have internet connection, you can installed HDP using a local repo Once this is setup, you should already have access to zeppelin rpm. You can check this by running:
yum search zeppelin
Once this is confirmed, you can follow the below steps to:
- Download the Ambari service definition for Zeppelin from https://github.com/hortonworks-gallery/ambari-zeppelin-service/archive/master.zip
- Manually copy to the Ambari node and unzip under /var/lib/ambari-server/resources/stacks/HDP/2.4/services/ZEPPELIN (you will have to create this dir).
- Confirm you now see 'configuration' and 'package' subdirs under /var/lib/ambari-server/resources/stacks/HDP/2.4/services/ZEPPELIN
- Restart ambari-server
- Install Zeppelin via Ambari as you would install any other service (via the ‘Add service wizard')
See here for more info: https://community.hortonworks.com/questions/26215/zeppelin-offline-installation.html
-
In case you need to remove the Zeppelin service:
- Stop the service and delete it. Then restart Ambari
export SERVICE=ZEPPELIN
export PASSWORD=admin
export AMBARI_HOST=localhost
#detect name of cluster
output=`curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' http://$AMBARI_HOST:8080/api/v1/clusters`
CLUSTER=`echo $output | sed -n 's/.*"cluster_name" : "\([^\"]*\)".*/\1/p'`
#unregister the service from ambari
curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' -X DELETE http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER/services/$SERVICE
#if above errors out, run below first to fully stop the service
#curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context" :"Stop $SERVICE via REST"}, "Body": {"ServiceInfo": {"state": "INSTALLED"}}}' http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER/services/$SERVICE
service ambari-server restart
- Remove artifacts
rm -rf /opt/incubator-zeppelin
rm -rf /var/log/zeppelin*
rm -rf /var/run/zeppelin*
sudo -u hdfs hadoop fs -rmr /apps/zeppelin
rm -rf /var/lib/ambari-server/resources/views/zeppelin-view-1.0-SNAPSHOT.jar
userdel -r zeppelin
VERSION=`hdp-select status hadoop-client | sed 's/hadoop-client - \([0-9]\.[0-9]\).*/\1/'`
rm -rf /var/lib/ambari-server/resources/stacks/HDP/$VERSION/services/ZEPPELIN
rm -f /tmp/zeppelin.tar.gz
service ambari-server restart