Ambari service for easily installing and managing Zeppelin on HDP cluster
Author: Ali Bajwa
Contents:
- Pre-requisites:Spark 1.2.1+ installed
- Setup Ambari service
- Install Ambari view
- Run demo zeppelin notebooks
- Remove zeppelin service
Testing:
- These steps were tested on HDP 2.2.4.2 cluster installed via Ambari 2.0 and latest HDP 2.2.4.2 sandbox
Videos:
- Download HDP 2.2.4.2 sandbox VM image (Sandbox_HDP_2.2.4.2_VMWare.ova) from Hortonworks website
- Import Sandbox_HDP_2.2.4.2_VMWare.ova into VMWare and set the VM memory size to 8GB
- Now start the VM
- After it boots up, find the IP address of the VM and add an entry into your machines hosts file e.g.
192.168.191.241 sandbox.hortonworks.com sandbox
- Connect to the VM via SSH (password hadoop) and start Ambari server
ssh [email protected]
/root/start_ambari.sh
-
(Optional) If you deployed in a VirtualBox Sandbox environment, enable port forwarding on ports 9995 and 9996. If you don't enable port 9996, the Zeppelin UI/Ambari View shows disconnected on the upper right and none of the default tutorials are visible.
-
Note that if you do not have Spark 1.2+ installed (e.g. if you are running HDP 2.2.0), you can use below commands to download and set it up
mkdir -p /usr/hdp/current/spark-client/
cd /usr/hdp/current/spark-client/
#for spark 1.2
wget http://public-repo-1.hortonworks.com/HDP-LABS/Projects/spark/1.2.0/spark-1.2.0.2.2.0.0-82-bin-2.6.0.2.2.0.0-2041.tgz
#for spark 1.3
#wget http://d3kbcqa49mib13.cloudfront.net/spark-1.3.1-bin-hadoop2.6.tgz
tar --strip-components=1 -xzvf spark*.tgz
export HDP_VER=`hdp-select status hadoop-client | sed 's/hadoop-client - \(.*\)/\1/'`
echo "spark.driver.extraJavaOptions -Dhdp.version=$HDP_VER" >> conf/spark-defaults.conf
echo "spark.yarn.am.extraJavaOptions -Dhdp.version=$HDP_VER" >> conf/spark-defaults.conf
rm -f spark-*.tgz
- To deploy the Zeppelin service, run below on ambari server
VERSION=`hdp-select status hadoop-client | sed 's/hadoop-client - \([0-9]\.[0-9]\).*/\1/'`
git clone https://github.com/hortonworks-gallery/ambari-zeppelin-service.git /var/lib/ambari-server/resources/stacks/HDP/$VERSION/services/ZEPPELIN
- Restart Ambari
#on sandbox
service ambari restart
#on non-sandbox
sudo service ambari-server restart
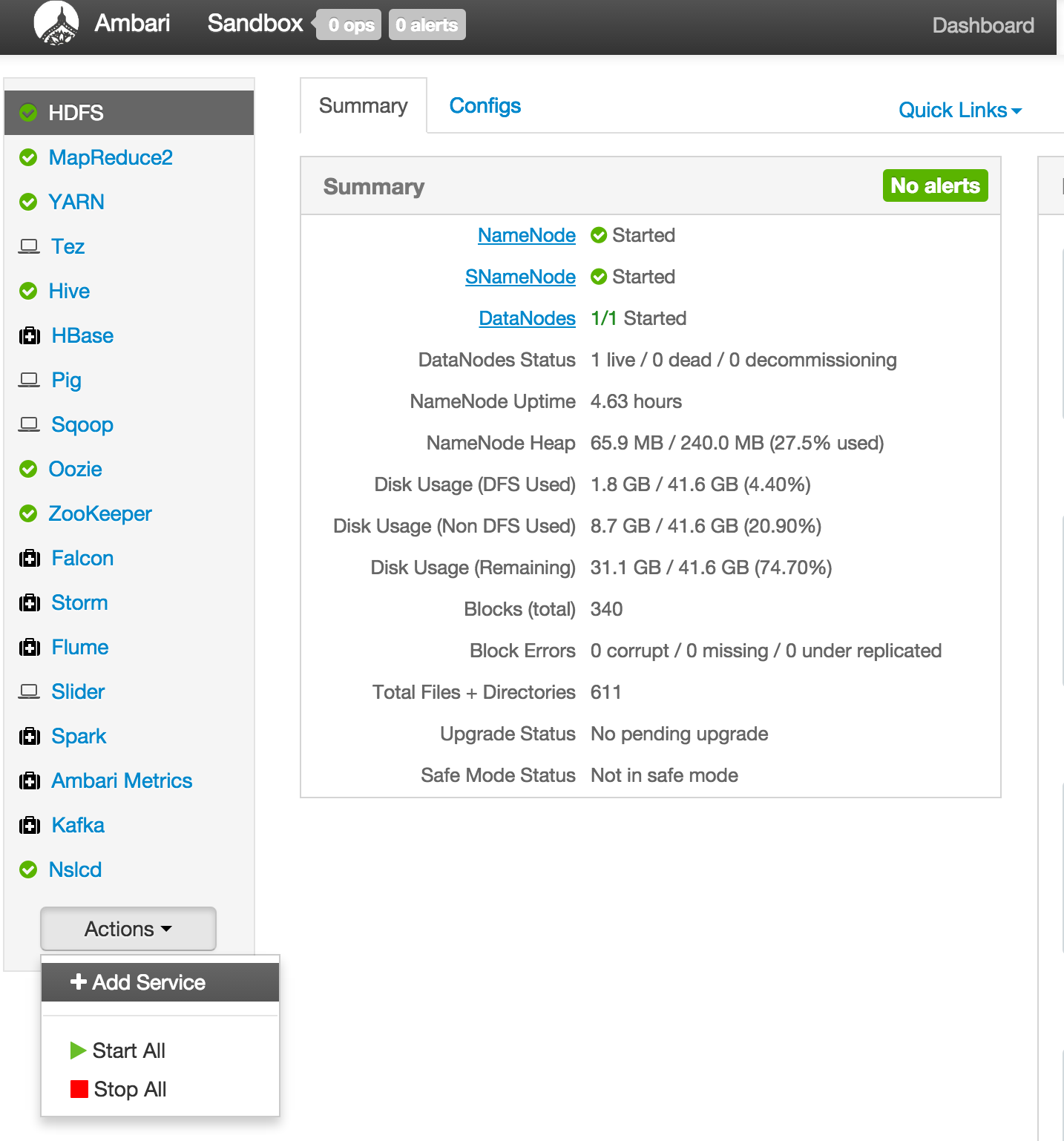
- Then you can click on 'Add Service' from the 'Actions' dropdown menu in the bottom left of the Ambari dashboard:
On bottom left -> Actions -> Add service -> check Zeppelin service -> Next -> Next -> Next -> Deploy.

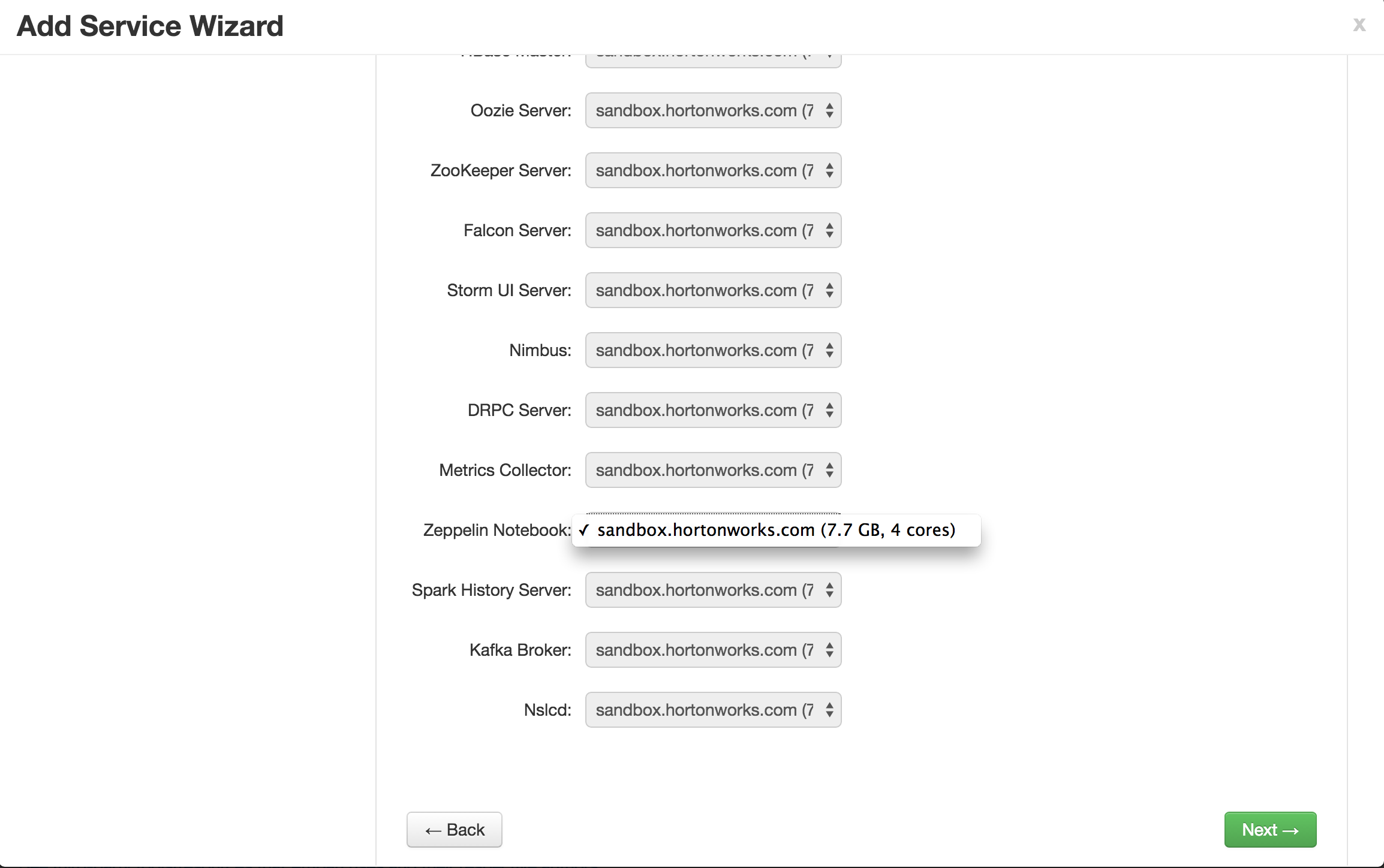 You should not need to change any default configs...
You should not need to change any default configs...
 ...but here are sample of configurations that you could modify if needed (e.g. executor memory, port etc)
...but here are sample of configurations that you could modify if needed (e.g. executor memory, port etc)
 Click Next to accept defaults...
Click Next to accept defaults...
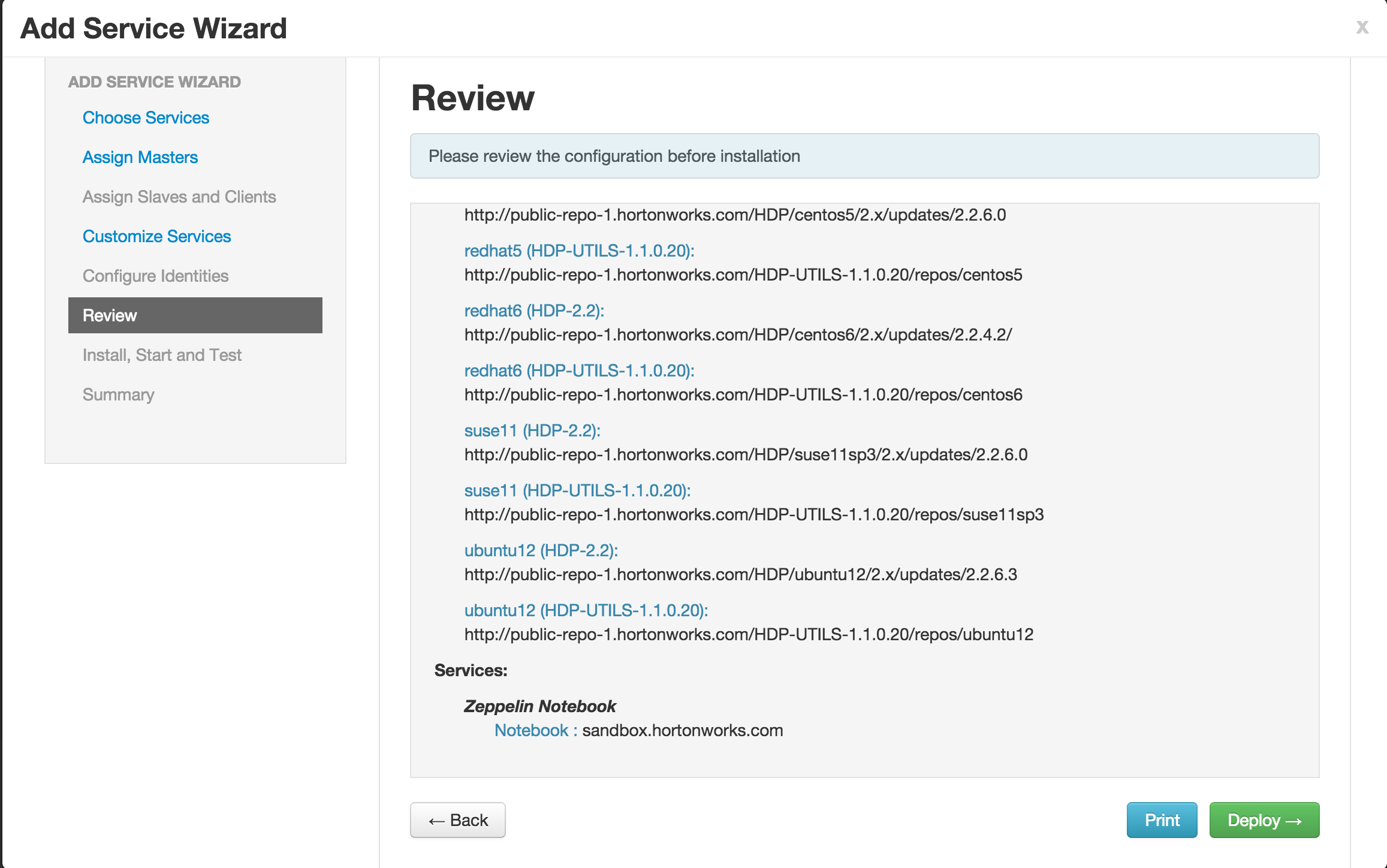 Click Deploy to start the installation
Click Deploy to start the installation
Note that:
-
The default mode of the service sets up Zeppelin in yarn-client mode by downloading a tarball of bits thats were precompiled against a version of spark containing fix for SPARK-4461 (ETA: < 5min)
-
(Optional) To instead pull/compile the latest Zeppelin code from the git page (ETA: < 40min depending on internet connection):
- While adding zeppelin service, in the configuration step of the wizard:
- set zeppelin.download.prebuilt to false
- Note that during install, the service will automatically intall maven and update its settings to point to hortonworks dev repo to get latest spark jars by adding this file under ~/.m2
- Mapreduce config changes in Ambari: change all references to ${hdp.version} or $HDP_VERSION to your HDP version (e.g. 2.2.4.2-2) and restart Mapreduce2 service. You can find your HDP version by running
hdp-select status hadoop-client- Why is this needed? See SPARK-4461 for details. This is fixed in Spark 1.3
- Without this, you will encounter the below error when running scala cells and RM log will show that ${hdp.version} did not get replaced.
org.apache.spark.SparkException: Job cancelled because SparkContext was shut down - To automate this you can run the below commands only needed with Spark 1.2.1
- While adding zeppelin service, in the configuration step of the wizard:
#Run from ambari server host. Replace the values for "cluster" and "password" with the values for your own cluster
export password=admin
export cluster=Sandbox
export HDP_VER=hdp-select status hadoop-client | sed 's/hadoop-client - \(.*\)/\1/'
cd /var/lib/ambari-server/resources/scripts
./configs.sh -u admin -p $password set localhost $cluster mapred-site yarn.app.mapreduce.am.admin-command-opts -Dhdp.version=$HDP_VER
./configs.sh -u admin -p $password set localhost $cluster mapred-site mapreduce.application.framework.path /hdp/apps/$HDP_VER/mapreduce/mapreduce.tar.gz#mr-framework
./configs.sh -u admin -p $password set localhost $cluster mapred-site mapreduce.admin.map.child.java.opts "-server -XX:NewRatio=8 -Djava.net.preferIPv4Stack=true -Dhdp.version=$HDP_VER"
./configs.sh -u admin -p $password set localhost $cluster mapred-site mapreduce.admin.reduce.child.java.opts "-server -XX:NewRatio=8 -Djava.net.preferIPv4Stack=true -Dhdp.version=$HDP_VER"
./configs.sh -u admin -p $password set localhost $cluster mapred-site mapreduce.admin.user.env "LD_LIBRARY_PATH=/usr/hdp/$HDP_VER/hadoop/lib/native:/usr/hdp/$HDP_VER/hadoop/lib/native/Linux-amd64-64"
./configs.sh -u admin -p $password set localhost $cluster mapred-site mapreduce.application.classpath "$PWD/mr-framework/hadoop/share/hadoop/mapreduce/:$PWD/mr-framework/hadoop/share/hadoop/mapreduce/lib/:$PWD/mr-framework/hadoop/share/hadoop/common/:$PWD/mr-framework/hadoop/share/hadoop/common/lib/:$PWD/mr-framework/hadoop/share/hadoop/yarn/:$PWD/mr-framework/hadoop/share/hadoop/yarn/lib/:$PWD/mr-framework/hadoop/share/hadoop/hdfs/:$PWD/mr-framework/hadoop/share/hadoop/hdfs/lib/:/usr/hdp/$HDP_VER/hadoop/lib/hadoop-lzo-0.6.0.$HDP_VER.jar:/etc/hadoop/conf/secure"
curl --user admin:$password -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context": "Stop MAPREDUCE2"}, "ServiceInfo": {"state": "INSTALLED"}}' http://localhost:8080/api/v1/clusters/$cluster/services/MAPREDUCE2
sleep 20
curl --user admin:$password -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context": "Start MAPREDUCE2"}, "ServiceInfo": {"state": "STARTED"}}' http://localhost:8080/api/v1/clusters/$cluster/services/MAPREDUCE2
```
- To track the progress of the install you can run the below:
tail -f /var/log/zeppelin/zeppelin-setup.log
-
On successful deployment you will see the Zeppelin service as part of Ambari stack and will be able to start/stop the service from here:

-
You can see the parameters you configured under 'Configs' tab



- You can launch Zeppelin from Ambari via iFrame view using steps below:
export ZEPPELIN_HOST=sandbox.hortonworks.com
export ZEPPELIN_PORT=9995
cd /tmp
git clone https://github.com/abajwa-hw/iframe-view.git
sed -i "s/iFrame View/Zeppelin/g" iframe-view/src/main/resources/view.xml
sed -i "s/IFRAME_VIEW/ZEPPELIN/g" iframe-view/src/main/resources/view.xml
sed -i "s/sandbox.hortonworks.com:6080/$ZEPPELIN_HOST:$ZEPPELIN_PORT/g" iframe-view/src/main/resources/index.html
sed -i "s/iframe-view/zeppelin-view/g" iframe-view/pom.xml
sed -i "s/Ambari iFrame View/Zeppelin View/g" iframe-view/pom.xml
mv iframe-view zeppelin-view
cd zeppelin-view
mvn clean package
/bin/cp -f /tmp/zeppelin-view/target/*.jar /var/lib/ambari-server/resources/views
service ambari-server restart
#may not be needed but good to check
service ambari-agent start
-
Lauch the notebook either via navigating to http://sandbox.hortonworks.com:9995 or via the view by opening http://sandbox.hortonworks.com:8080/#/main/views/ZEPPELIN/1.0.0/INSTANCE_1 should show Zeppelin as Ambari view

-
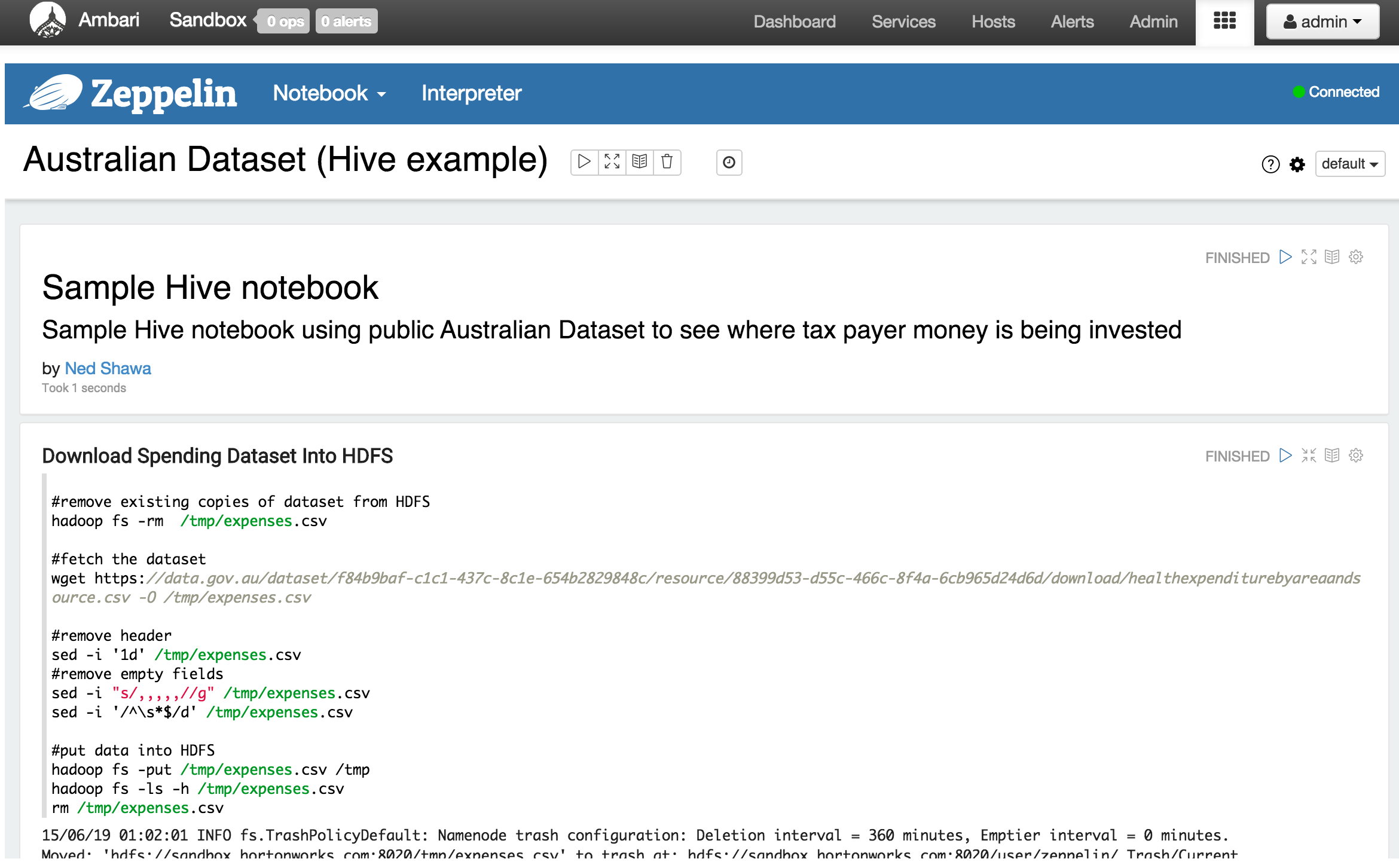
There should be a few sample notebooks created. Started by running through the Hive one (highlight a cell then press Shift-Enter):

-
Next try the same demo using the Spark/SparkSQL notebook (highlight a cell then press Shift-Enter):

- The first invocation takes some time as the Spark context is launched. You can tail the interpreter log file to see the details.


tail -f /var/log/zeppelin/zeppelin-interpreter-spark--*.log
- Other things to try
- Test by creating a new note and enter some arithmetic in the first cell and press Shift-Enter to execute.
2+2
- Test pyspark by entering some python commands in the second cell and press Shift-Enter to execute.
%pyspark
a=(1,2,3,4,5,6)
print a
- Test scala by pasting the below in the third cell to read/parse a log file from sandbox local disk
val words = sc.textFile("file:///var/log/ambari-agent/ambari-agent.log").flatMap(line => line.toLowerCase().split(" ")).map(word => (word, 1))
words.take(5)
- You can also add a cell as below to read a file from HDFS instead. Prior to running the below cell, you should copy the log file to HDFS by running
hadoop fs -put /var/log/ambari-agent/ambari-agent.log /tmpfrom your SSH terminal window
val words = sc.textFile("hdfs:///tmp/ambari-agent.log").flatMap(line => line.toLowerCase().split(" ")).map(word => (word, 1))
words.take(5)

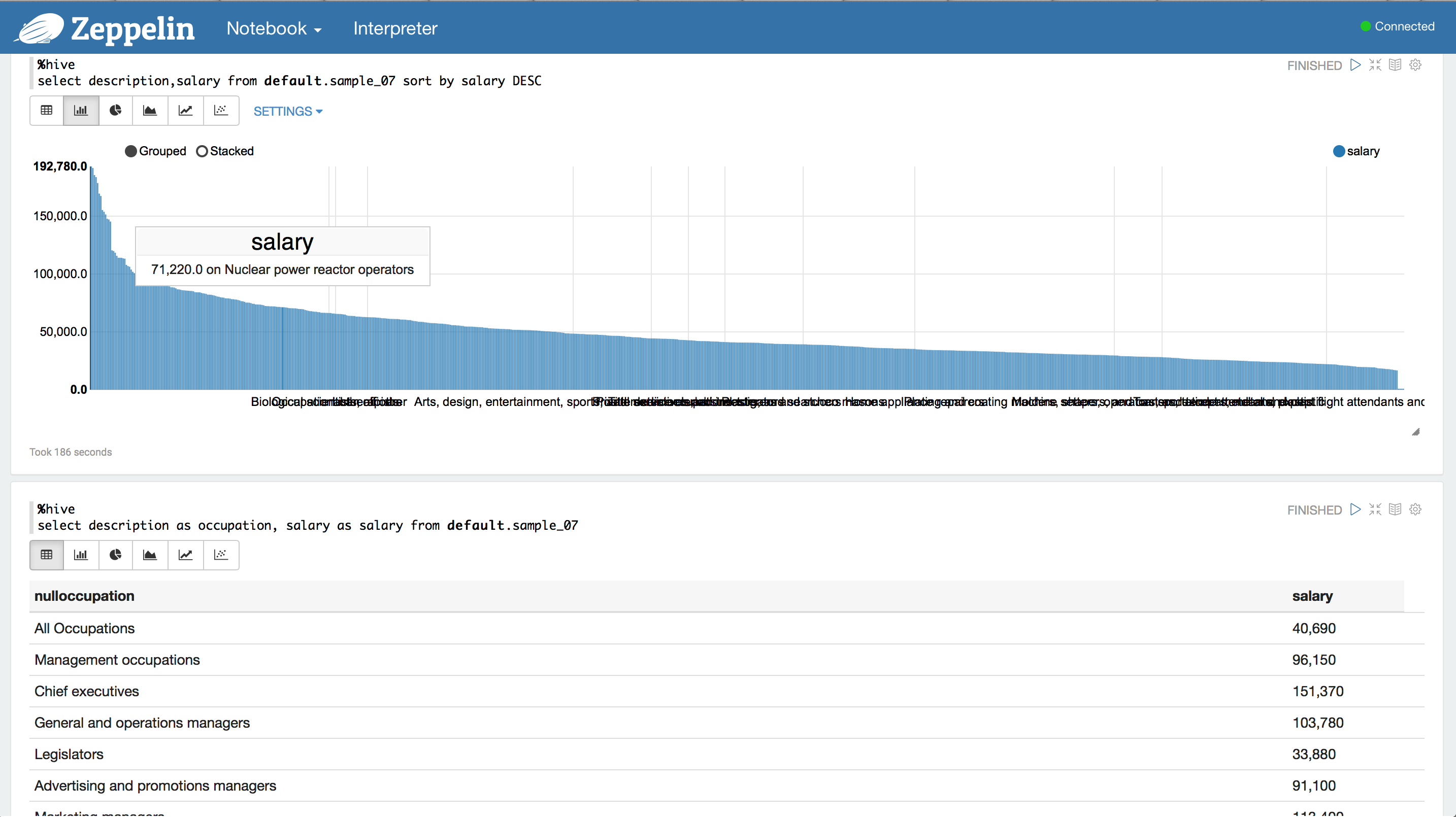
- Now try a hive query and notice how you can view the results as a table and as different charts
%hive
select description, salary from default.sample_07
- Open the ResourceManager UI and notice Spark is running on YARN: http://sandbox.hortonworks.com:8088/cluster


You can also use this UI for troubleshooting hanging jobs
- Click on the ApplicationMaster link to access the Spark UI:

- One benefit to wrapping the component in Ambari service is that you can now monitor/manage this service remotely via REST API
export SERVICE=ZEPPELIN
export PASSWORD=admin
export AMBARI_HOST=sandbox.hortonworks.com
export CLUSTER=Sandbox
#get service status
curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' -X GET http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER/services/$SERVICE
#start service
curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context" :"Start $SERVICE via REST"}, "Body": {"ServiceInfo": {"state": "STARTED"}}}' http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER/services/$SERVICE
#stop service
curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context" :"Stop $SERVICE via REST"}, "Body": {"ServiceInfo": {"state": "INSTALLED"}}}' http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER/services/$SERVICE
-
To remove the Zeppelin service:
- Stop the service and delete it. Then restart Ambari
export SERVICE=ZEPPELIN
export PASSWORD=admin
export AMBARI_HOST=sandbox.hortonworks.com
export CLUSTER=Sandbox
curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' -X DELETE http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER/services/$SERVICE
#if above errors out, run below first
#curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo": {"context" :"Stop $SERVICE via REST"}, "Body": {"ServiceInfo": {"state": "INSTALLED"}}}' http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER/services/$SERVICE
service ambari-server restart
- Remove artifacts
rm -rf /opt/incubator-zeppelin
rm -rf /var/log/zeppelin*
rm -rf /var/run/zeppelin*
sudo -u hdfs hadoop fs -rmr /apps/zeppelin
rm -rf /var/lib/ambari-server/resources/stacks/HDP/2.2/services/zeppelin-stack
service ambari-server restart