WIP augmented Lagrangian solver for adding equality constraints #457
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,2 @@ | ||
| # TODO: delete this with scratch | ||
| *.png |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,79 @@ | ||
| # Copyright (c) Meta Platforms, Inc. and affiliates. | ||
| # | ||
| # This source code is licensed under the MIT license found in the | ||
| # LICENSE file in the root directory of this source tree. | ||
| # | ||
| # Implements the augmented Lagrangian method for constrained | ||
| # nonlinear least squares as described on page 11.21 of | ||
| # http://www.seas.ucla.edu/~vandenbe/133B/lectures/nllseq.pdf | ||
|
|
||
| import copy | ||
| import torch | ||
| import theseus as th | ||
|
|
||
|
|
||
| def solve_augmented_lagrangian( | ||
| err_fn, | ||
| optim_vars, | ||
| aux_vars, | ||
| dim, | ||
| equality_constraint_fn, | ||
| optimizer_cls, | ||
| optimizer_kwargs, | ||
| verbose, | ||
| initial_state_dict, | ||
| num_augmented_lagrangian_iterations=10, | ||
| callback=None, | ||
| ): | ||
| def err_fn_augmented(optim_vars, aux_vars): | ||
| # TODO: Dangerous to override optim_vars,aux_vars here | ||
| original_aux_vars = aux_vars[:-2] | ||
| original_err = err_fn(optim_vars, original_aux_vars) | ||
| g = equality_constraint_fn(optim_vars, original_aux_vars) | ||
|
|
||
| mu, z = aux_vars[-2:] | ||
| sqrt_mu = torch.sqrt(mu.tensor) | ||
| err_augmented = sqrt_mu * g + z.tensor / (2.0 * sqrt_mu) | ||
| combined_err = torch.cat([original_err, err_augmented], axis=-1) | ||
| return combined_err | ||
|
|
||
| g = equality_constraint_fn(optim_vars, aux_vars) | ||
|
There was a problem hiding this comment. For this, I like the equality_constraint = th.EqualityConstraint(th.AutoDiffCostFunction(...))Following on the other comment above, a class like |
||
| dim_constraints = g.shape[-1] | ||
| dim_augmented = dim + dim_constraints | ||
|
|
||
| num_batch = 1 # TODO: Infer this from somewhere else? | ||
| mu = th.Variable(torch.ones(num_batch, 1), name="mu") | ||
| z = th.Variable(torch.zeros(num_batch, dim_constraints), name="z") | ||
| aux_vars_augmented = aux_vars + [mu, z] | ||
|
|
||
| cost_fn_augmented = th.AutoDiffCostFunction( | ||
| optim_vars=optim_vars, | ||
| err_fn=err_fn_augmented, | ||
| dim=dim_augmented, | ||
| aux_vars=aux_vars_augmented, | ||
| name="cost_fn_augmented", | ||
| ) | ||
|
|
||
| objective = th.Objective() | ||
| objective.add(cost_fn_augmented) | ||
|
|
||
| optimizer = optimizer_cls(objective, **optimizer_kwargs) | ||
| theseus_optim = th.TheseusLayer(optimizer) | ||
| state_dict = copy.copy(initial_state_dict) | ||
|
|
||
| prev_g_norm = 0 | ||
| for i in range(num_augmented_lagrangian_iterations): | ||
| state_dict, info = theseus_optim.forward(state_dict) | ||
| g_x = equality_constraint_fn(optim_vars, aux_vars) | ||
| g_norm = g_x.norm() | ||
| if verbose: | ||
| print(f"=== [{i}] mu: {mu.tensor.item():.2e}, ||g||: {g_norm:.2e}") | ||
| print(state_dict) | ||
| if callback is not None: | ||
| callback(state_dict) | ||
| z.tensor = z.tensor + 2 * mu.tensor * g_x | ||
| if i > 0 and g_norm > 0.25 * prev_g_norm: | ||
| mu.tensor = 2 * mu.tensor | ||
| prev_g_norm = g_norm | ||
|
|
||
| return state_dict | ||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,182 @@ | ||
| #!/usr/bin/env python3 | ||
| # Copyright (c) Meta Platforms, Inc. and affiliates. | ||
| # | ||
| # This source code is licensed under the MIT license found in the | ||
| # LICENSE file in the root directory of this source tree. | ||
| # | ||
| # This is the car example starting on page 23 of: | ||
| # http://www.seas.ucla.edu/~vandenbe/133B/lectures/nllseq.pdf | ||
|
|
||
| import numpy as np | ||
| import torch | ||
| import copy | ||
|
|
||
| import matplotlib as mpl | ||
| import matplotlib.pyplot as plt | ||
| import matplotlib.patches as patches | ||
|
|
||
| import theseus as th | ||
| from augmented_lagrangian import solve_augmented_lagrangian | ||
|
|
||
| plt.style.use("bmh") | ||
|
|
||
| N = 20 # Number of timesteps | ||
| L = 0.1 # Length of car | ||
| h = 0.05 # Discretization interval | ||
| squared_cost_weight = 1e-2 # Weight for the controls | ||
| slew_cost_weight = 1.0 # Weight for the slew rate | ||
|
|
||
| x_init = torch.zeros(3) # Initial state | ||
| x_final = torch.tensor([0.5, 0.3, np.pi / 2.0]) # Final state | ||
|
|
||
| # Can try these other final states, but isn't very stable. | ||
| # x_final = torch.tensor([0, 0.5, 0]) | ||
| # x_final = torch.tensor([0, 1., 0]) | ||
| # x_final = torch.tensor([0.5, 0.3, 0]) | ||
| # x_final = torch.tensor([0, 1., 0.5*np.pi]) | ||
| # x_final = torch.tensor([0.5, 0.5, 0.]) | ||
|
|
||
|
|
||
| # Given a state x and action u, return the | ||
| # next state following the discretized dynamics. | ||
| def car_dynamics(x, u): | ||
| new_x = [ | ||
| x[0] + h * u[0] * torch.cos(x[2]), | ||
| x[1] + h * u[0] * torch.sin(x[2]), | ||
| x[2] + h * u[0] * torch.tan(u[1] / L), | ||
| ] | ||
| return torch.stack(new_x) | ||
|
|
||
|
|
||
| def plot_car_trajectory(xs, us): | ||
| # The optimization formulation leaves out these known values from the states | ||
| xs = [x_init] + xs + [x_final] | ||
| us = us + [torch.zeros(2)] | ||
|
|
||
| fig, ax = plt.subplots(figsize=(6, 6)) | ||
| for x, u in zip(xs, us): | ||
| x = x.squeeze() | ||
| u = u.squeeze() | ||
|
|
||
| p = x[:2] | ||
| theta = x[2] | ||
|
|
||
| width = 0.5 * L | ||
| alpha = 0.5 | ||
| rect = patches.Rectangle( | ||
| (0, -0.5 * width), | ||
| L, | ||
| width, | ||
| linewidth=1, | ||
| edgecolor="black", | ||
| facecolor="#DCDCDC", | ||
| alpha=alpha, | ||
| ) | ||
| t = mpl.transforms.Affine2D().rotate(theta).translate(*p) + ax.transData | ||
| rect.set_transform(t) | ||
| ax.add_patch(rect) | ||
|
|
||
| wheel_length = width / 2.0 | ||
| wheel = patches.Rectangle( | ||
| (L - 0.5 * wheel_length, -0.5 * width), | ||
| wheel_length, | ||
| 0, | ||
| linewidth=1, | ||
| edgecolor="black", | ||
| alpha=alpha, | ||
| ) | ||
| t = ( | ||
| mpl.transforms.Affine2D() | ||
| .rotate_around(L, -0.5 * width, u[1]) | ||
| .rotate(theta) | ||
| .translate(*p) | ||
| + ax.transData | ||
| ) | ||
| wheel.set_transform(t) | ||
| ax.add_patch(wheel) | ||
|
|
||
| wheel = patches.Rectangle( | ||
| (L - 0.5 * wheel_length, +0.5 * width), | ||
| wheel_length, | ||
| 0, | ||
| linewidth=1, | ||
| edgecolor="black", | ||
| alpha=alpha, | ||
| ) | ||
| t = ( | ||
| mpl.transforms.Affine2D() | ||
| .rotate_around(L, +0.5 * width, u[1]) | ||
| .rotate(theta) | ||
| .translate(*p) | ||
| + ax.transData | ||
| ) | ||
| wheel.set_transform(t) | ||
| ax.add_patch(wheel) | ||
|
|
||
| ax.axis("equal") | ||
| fig.savefig("trajectory.png") | ||
| plt.close(fig) | ||
|
|
||
|
|
||
| def plot_action_sequence(us): | ||
| us = torch.stack(us).squeeze() | ||
| fig, ax = plt.subplots(figsize=(6, 4)) | ||
| ax.plot(us[:, 0], label="speed") | ||
| ax.plot(us[:, 1], label="steering angle") | ||
| fig.legend(ncol=2, loc="upper center") | ||
| fig.savefig("actions.png") | ||
| plt.close(fig) | ||
|
|
||
|
|
||
| # Ensure the trajectory satisfies the dynamics and reaches the goal state | ||
| def equality_constraint_fn(optim_vars, aux_vars): | ||
| xs, us = optim_vars[: N - 1], optim_vars[N - 1 :] | ||
| us = [u.tensor for u in us] | ||
| xs = [x.tensor for x in xs] | ||
| assert len(us) == N | ||
| constraints = [car_dynamics(x_init, us[0][0]) - xs[0]] | ||
| for idx in range(N - 2): | ||
| constraints.append(car_dynamics(xs[idx][0], us[idx + 1][0]) - xs[idx + 1]) | ||
| constraints.append((car_dynamics(xs[-1][0], us[-1][0]) - x_final).unsqueeze(0)) | ||
| constraints = torch.cat(constraints).ravel() | ||
| return constraints | ||
|
|
||
|
|
||
| # Make the controls and rate of change of controls minimal. | ||
| def err_fn(optim_vars, aux_vars): | ||
| xs, us = optim_vars[: N - 1], optim_vars[N - 1 :] | ||
| us = [u.tensor for u in us] | ||
| xs = [x.tensor for x in xs] | ||
| err_list = copy.copy([u * squared_cost_weight for u in us]) | ||
| for idx in range(len(us) - 1): | ||
| err_list.append(slew_cost_weight * (us[idx + 1] - us[idx])) | ||
|
|
||
| err = torch.cat(err_list, axis=-1) | ||
| return err | ||
|
|
||
|
|
||
| u = [th.Vector(2, name="u" + str(idx + 1)) for idx in range(N)] | ||
| x = [th.Vector(3, name="x" + str(idx + 1)) for idx in range(1, N)] | ||
| optim_vars = x + u | ||
| dim = 2 * (N + N - 1) | ||
|
|
||
|
|
||
| def plot_callback(state_dict): | ||
| xs = [state_dict["x" + str(idx + 1)] for idx in range(1, N)] | ||
| us = [state_dict["u" + str(idx + 1)] for idx in range(N)] | ||
| plot_car_trajectory(xs, us) | ||
| plot_action_sequence(us) | ||
|
|
||
|
|
||
| solve_augmented_lagrangian( | ||
| err_fn=err_fn, | ||
| optim_vars=optim_vars, | ||
| aux_vars=[], | ||
| dim=dim, | ||
| equality_constraint_fn=equality_constraint_fn, | ||
| optimizer_cls=th.LevenbergMarquardt, | ||
| optimizer_kwargs=dict(max_iterations=100, step_size=1.0), | ||
| verbose=True, | ||
| initial_state_dict={}, | ||
| callback=plot_callback, | ||
| ) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,47 @@ | ||
| #!/usr/bin/env python3 | ||
| # Copyright (c) Meta Platforms, Inc. and affiliates. | ||
| # | ||
| # This source code is licensed under the MIT license found in the | ||
| # LICENSE file in the root directory of this source tree. | ||
| # | ||
| # This is a small test of the augmented Lagrangian solver for the | ||
| # optimization problem: | ||
| # minimize ||x||^2 subject to x_0 = 1, | ||
| # which has the analytic solution [1, 0]. | ||
|
|
||
| import torch | ||
| import theseus as th | ||
| from augmented_lagrangian import solve_augmented_lagrangian | ||
|
|
||
|
|
||
| def err_fn(optim_vars, aux_vars): | ||
| (x,) = optim_vars | ||
| cost = x.tensor | ||
| return cost | ||
|
|
||
|
|
||
| def equality_constraint_fn(optim_vars, aux_vars): | ||
| (x,) = optim_vars | ||
| x = x.tensor | ||
| return x[..., 0] - 1 | ||
|
|
||
|
|
||
| dim = 2 | ||
| x = th.Vector(dim, name="x") | ||
| optim_vars = [x] | ||
|
|
||
| state_dict = solve_augmented_lagrangian( | ||
| err_fn=err_fn, | ||
| optim_vars=optim_vars, | ||
| aux_vars=[], | ||
| dim=dim, | ||
| equality_constraint_fn=equality_constraint_fn, | ||
| optimizer_cls=th.LevenbergMarquardt, | ||
| optimizer_kwargs=dict(max_iterations=100, step_size=1.0), | ||
| verbose=True, | ||
| initial_state_dict={}, | ||
| ) | ||
|
|
||
| true_solution = torch.tensor([1.0, 0.0]) | ||
| threshold = 1e-5 | ||
| assert (state_dict["x"].squeeze() - true_solution).norm() <= threshold |
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I'm thinking it might be better (cleaner and more efficient) to introduce extra cost function terms for the constraints terms in the augmented Lagrangian, rather than extend to a new function with a larger error dimension. That is, the second row here would have its own cost function terms:
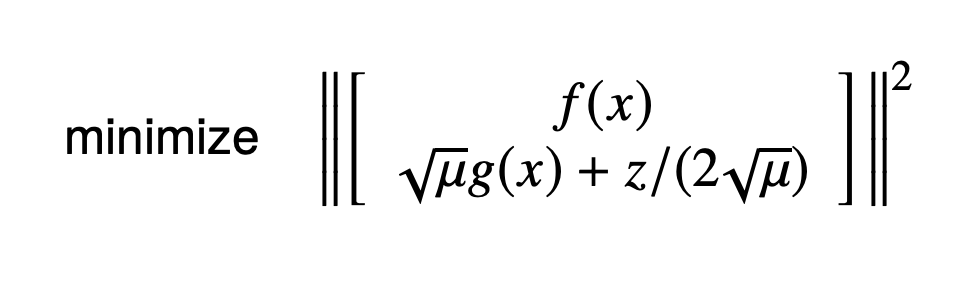
and Theseus already minimizes for the sum of squares internally. In terms of code, I think this should just involve moving the
err_augmentedterm to its ownCostFunctionobject. I see the following advantages:dg(x)/dx, it should be easier to manually compute the jacobians of the augmented Lagrangian terms compared to the current approach.One disadvantage of this approach is that we don't allow objectives from being modified (costs added/deleted) after the optimizer is created, but we should be able to get around this with an
AugmentedLagrangianclass in a number of ways. I think for now, we can proof of concept things by manually adding the extra costs at the beginning of the example, just to get a feel for how things would look like. We can then figure out how to automate this process later.