🌐 English, 한국어.
tomotopy is a Python extension of tomoto (Topic Modeling Tool) which is a Gibbs-sampling based topic model library written in C++. It utilizes a vectorization of modern CPUs for maximizing speed. The current version of tomoto supports several major topic models including
- Latent Dirichlet Allocation (tomotopy.LDAModel)
- Labeled LDA (tomotopy.LLDAModel)
- Partially Labeled LDA (tomotopy.PLDAModel)
- Supervised LDA (tomotopy.SLDAModel)
- Dirichlet Multinomial Regression (tomotopy.DMRModel)
- Generalized Dirichlet Multinomial Regression (tomotopy.GDMRModel)
- Hierarchical Dirichlet Process (tomotopy.HDPModel)
- Hierarchical LDA (tomotopy.HLDAModel)
- Multi Grain LDA (tomotopy.MGLDAModel)
- Pachinko Allocation (tomotopy.PAModel)
- Hierarchical PA (tomotopy.HPAModel)
- Correlated Topic Model (tomotopy.CTModel)
- Dynamic Topic Model (tomotopy.DTModel)
- Pseudo-document based Topic Model (tomotopy.PTModel).
Please visit https://bab2min.github.io/tomotopy to see more information.
You can install tomotopy easily using pip. (https://pypi.org/project/tomotopy/)
$ pip install --upgrade pip $ pip install tomotopy
The supported OS and Python versions are:
- Linux (x86-64) with Python >= 3.6
- macOS >= 10.13 with Python >= 3.6
- Windows 7 or later (x86, x86-64) with Python >= 3.6
- Other OS with Python >= 3.6: Compilation from source code required (with c++14 compatible compiler)
After installing, you can start tomotopy by just importing.
import tomotopy as tp print(tp.isa) # prints 'avx2', 'avx', 'sse2' or 'none'
Currently, tomotopy can exploits AVX2, AVX or SSE2 SIMD instruction set for maximizing performance. When the package is imported, it will check available instruction sets and select the best option. If tp.isa tells none, iterations of training may take a long time. But, since most of modern Intel or AMD CPUs provide SIMD instruction set, the SIMD acceleration could show a big improvement.
Here is a sample code for simple LDA training of texts from 'sample.txt' file.
import tomotopy as tp
mdl = tp.LDAModel(k=20)
for line in open('sample.txt'):
mdl.add_doc(line.strip().split())
for i in range(0, 100, 10):
mdl.train(10)
print('Iteration: {}\tLog-likelihood: {}'.format(i, mdl.ll_per_word))
for k in range(mdl.k):
print('Top 10 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=10))
mdl.summary()
tomotopy uses Collapsed Gibbs-Sampling(CGS) to infer the distribution of topics and the distribution of words. Generally CGS converges more slowly than Variational Bayes(VB) that gensim's LdaModel uses, but its iteration can be computed much faster. In addition, tomotopy can take advantage of multicore CPUs with a SIMD instruction set, which can result in faster iterations.
Following chart shows the comparison of LDA model's running time between tomotopy and gensim. The input data consists of 1000 random documents from English Wikipedia with 1,506,966 words (about 10.1 MB). tomotopy trains 200 iterations and gensim trains 10 iterations.
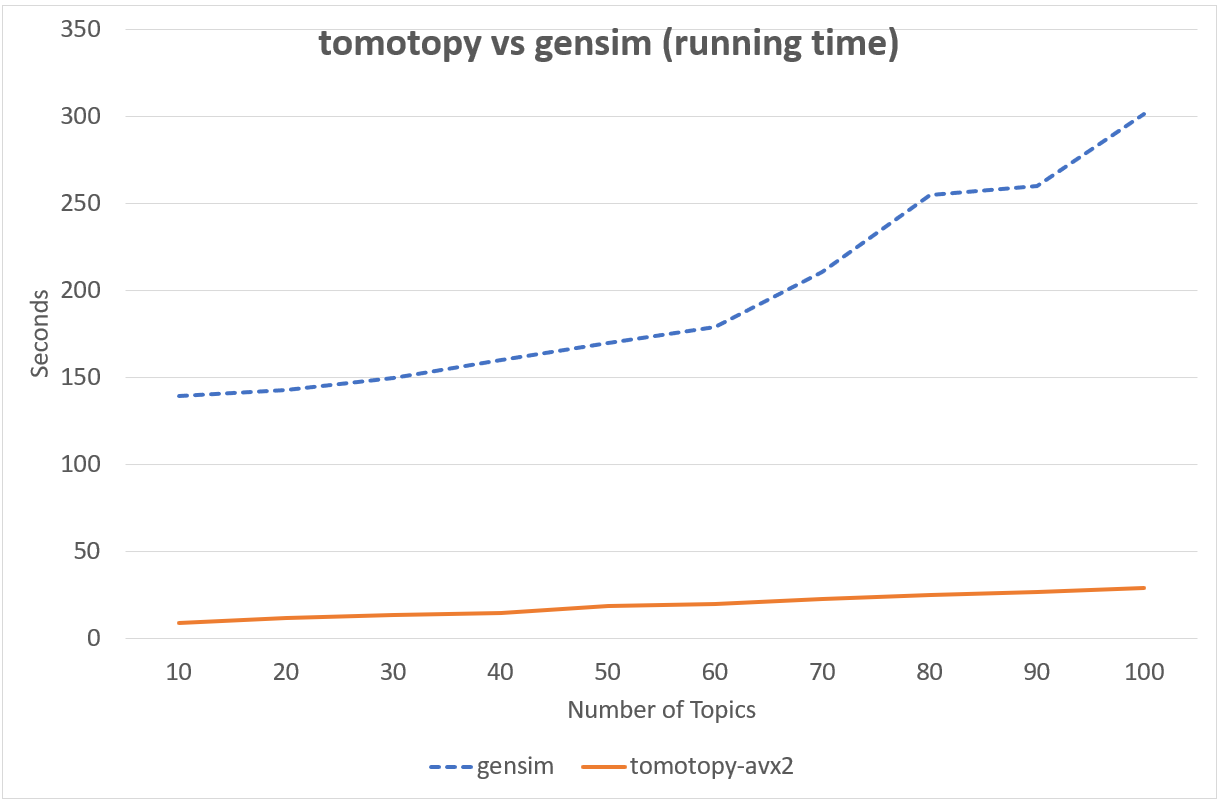
Performance in Intel i5-6600, x86-64 (4 cores)
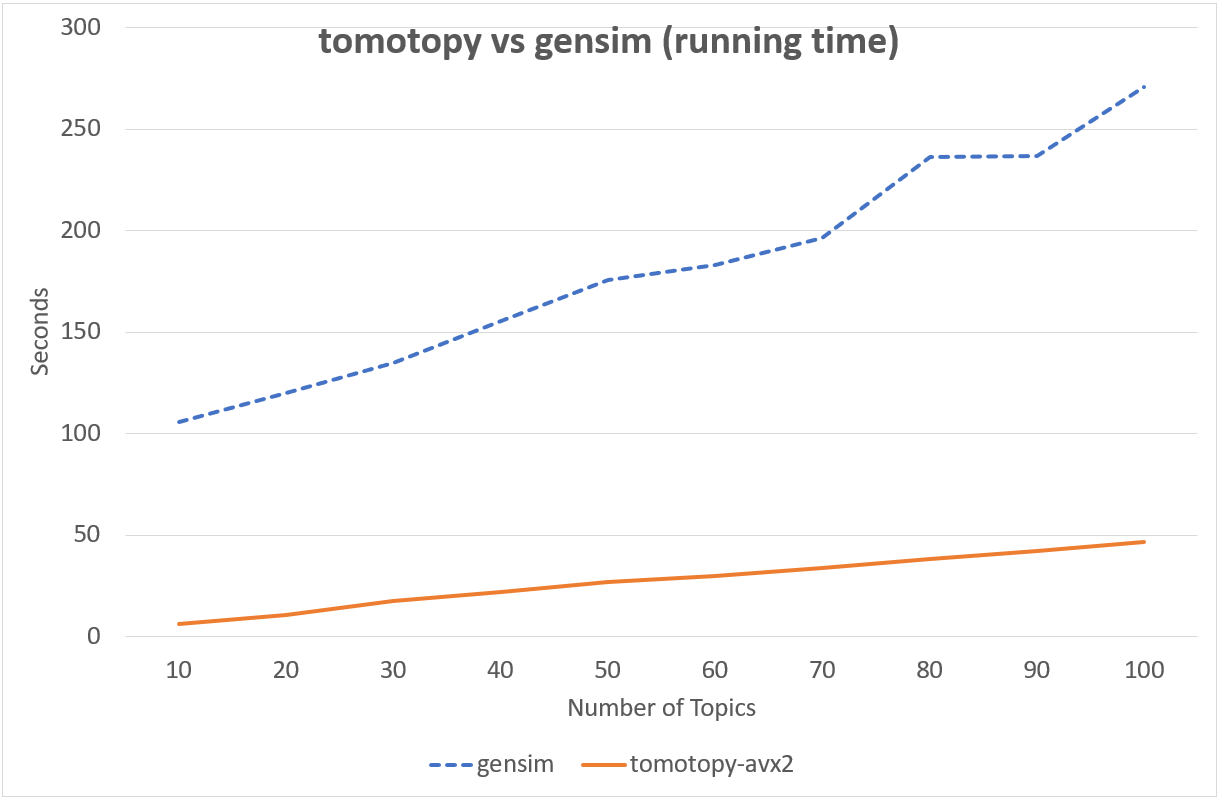
Performance in Intel Xeon E5-2620 v4, x86-64 (8 cores, 16 threads)
Although tomotopy iterated 20 times more, the overall running time was 5~10 times faster than gensim. And it yields a stable result.
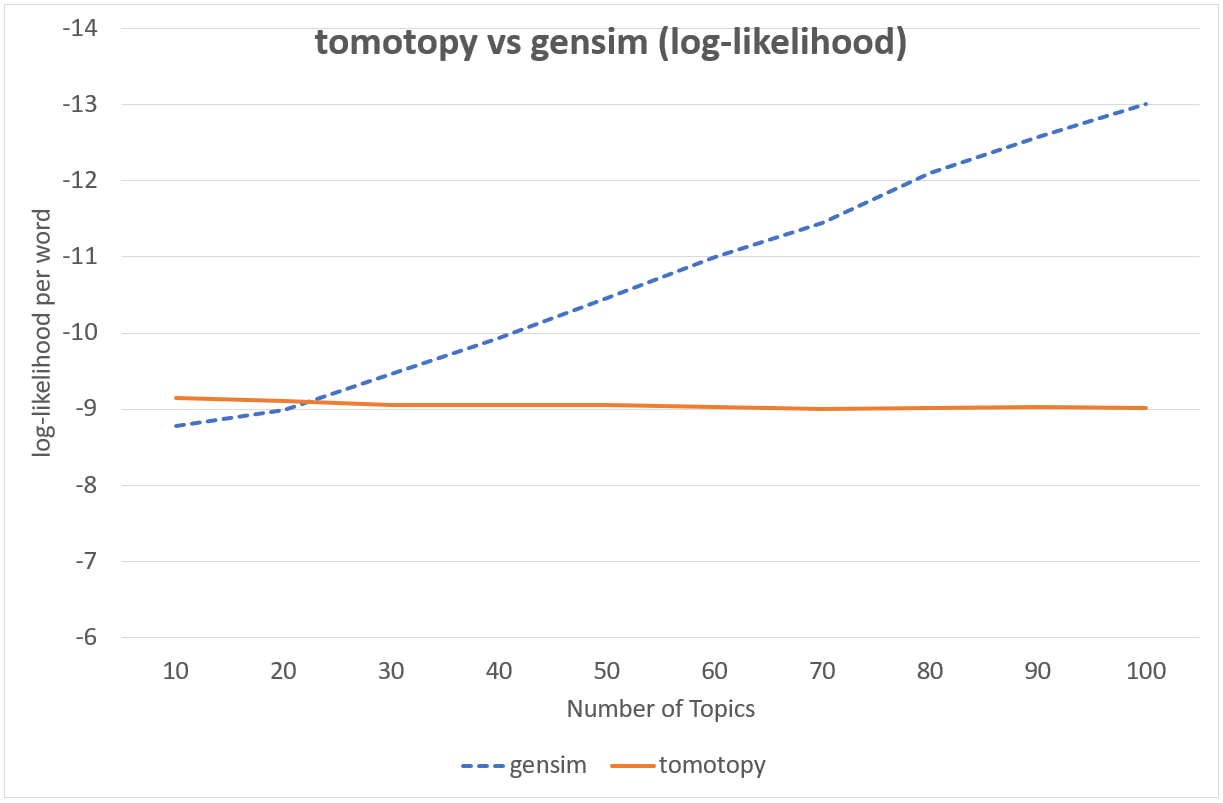
It is difficult to compare CGS and VB directly because they are totaly different techniques. But from a practical point of view, we can compare the speed and the result between them. The following chart shows the log-likelihood per word of two models' result.
The SIMD instruction set has a great effect on performance. Following is a comparison between SIMD instruction sets.
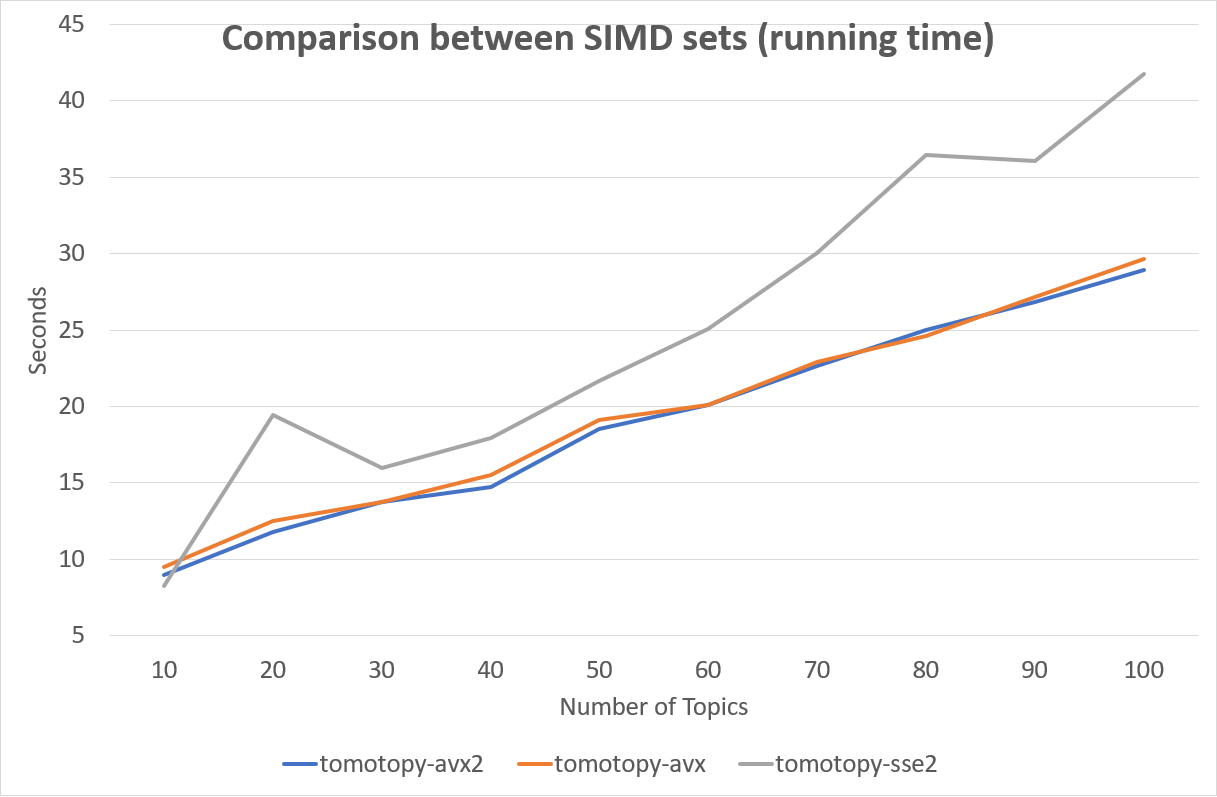
Fortunately, most of recent x86-64 CPUs provide AVX2 instruction set, so we can enjoy the performance of AVX2.
tomotopy provides save and load method for each topic model class, so you can save the model into the file whenever you want, and re-load it from the file.
import tomotopy as tp
mdl = tp.HDPModel()
for line in open('sample.txt'):
mdl.add_doc(line.strip().split())
for i in range(0, 100, 10):
mdl.train(10)
print('Iteration: {}\tLog-likelihood: {}'.format(i, mdl.ll_per_word))
# save into file
mdl.save('sample_hdp_model.bin')
# load from file
mdl = tp.HDPModel.load('sample_hdp_model.bin')
for k in range(mdl.k):
if not mdl.is_live_topic(k): continue
print('Top 10 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=10))
# the saved model is HDP model,
# so when you load it by LDA model, it will raise an exception
mdl = tp.LDAModel.load('sample_hdp_model.bin')
When you load the model from a file, a model type in the file should match the class of methods.
See more at tomotopy.LDAModel.save and tomotopy.LDAModel.load methods.
interactive_model_viewer_demo.mp4
You can see the result of modeling using the interactive viewer since v0.13.0.
import tomotopy as tp model = tp.LDAModel(...) # ... some training codes ... tp.viewer.open_viewer(model, host="localhost", port=9999) # And open http://localhost:9999 in your web browser!
If you have a saved model file, you can also use the following command line.
python -m tomotopy.viewer a_trained_model.bin --host localhost --port 9999
See more at tomotopy.viewer module.
We can use Topic Model for two major purposes. The basic one is to discover topics from a set of documents as a result of trained model, and the more advanced one is to infer topic distributions for unseen documents by using trained model.
We named the document in the former purpose (used for model training) as document in the model, and the document in the later purpose (unseen document during training) as document out of the model.
In tomotopy, these two different kinds of document are generated differently. A document in the model can be created by tomotopy.LDAModel.add_doc method. add_doc can be called before tomotopy.LDAModel.train starts. In other words, after train called, add_doc cannot add a document into the model because the set of document used for training has become fixed.
To acquire the instance of the created document, you should use tomotopy.LDAModel.docs like:
mdl = tp.LDAModel(k=20)
idx = mdl.add_doc(words)
if idx < 0: raise RuntimeError("Failed to add doc")
doc_inst = mdl.docs[idx]
# doc_inst is an instance of the added document
A document out of the model is generated by tomotopy.LDAModel.make_doc method. make_doc can be called only after train starts. If you use make_doc before the set of document used for training has become fixed, you may get wrong results. Since make_doc returns the instance directly, you can use its return value for other manipulations.
mdl = tp.LDAModel(k=20) # add_doc ... mdl.train(100) doc_inst = mdl.make_doc(unseen_doc) # doc_inst is an instance of the unseen document
If a new document is created by tomotopy.LDAModel.make_doc, its topic distribution can be inferred by the model. Inference for unseen document should be performed using tomotopy.LDAModel.infer method.
mdl = tp.LDAModel(k=20)
# add_doc ...
mdl.train(100)
doc_inst = mdl.make_doc(unseen_doc)
topic_dist, ll = mdl.infer(doc_inst)
print("Topic Distribution for Unseen Docs: ", topic_dist)
print("Log-likelihood of inference: ", ll)
The infer method can infer only one instance of tomotopy.Document or a list of instances of tomotopy.Document. See more at tomotopy.LDAModel.infer.
Every topic model in tomotopy has its own internal document type. A document can be created and added into suitable for each model through each model's add_doc method. However, trying to add the same list of documents to different models becomes quite inconvenient, because add_doc should be called for the same list of documents to each different model. Thus, tomotopy provides tomotopy.utils.Corpus class that holds a list of documents. tomotopy.utils.Corpus can be inserted into any model by passing as argument corpus to __init__ or add_corpus method of each model. So, inserting tomotopy.utils.Corpus just has the same effect to inserting documents the corpus holds.
Some topic models requires different data for its documents. For example, tomotopy.DMRModel requires argument metadata in str type, but tomotopy.PLDAModel requires argument labels in List[str] type. Since tomotopy.utils.Corpus holds an independent set of documents rather than being tied to a specific topic model, data types required by a topic model may be inconsistent when a corpus is added into that topic model. In this case, miscellaneous data can be transformed to be fitted target topic model using argument transform. See more details in the following code:
from tomotopy import DMRModel
from tomotopy.utils import Corpus
corpus = Corpus()
corpus.add_doc("a b c d e".split(), a_data=1)
corpus.add_doc("e f g h i".split(), a_data=2)
corpus.add_doc("i j k l m".split(), a_data=3)
model = DMRModel(k=10)
model.add_corpus(corpus)
# You lose `a_data` field in `corpus`,
# and `metadata` that `DMRModel` requires is filled with the default value, empty str.
assert model.docs[0].metadata == ''
assert model.docs[1].metadata == ''
assert model.docs[2].metadata == ''
def transform_a_data_to_metadata(misc: dict):
return {'metadata': str(misc['a_data'])}
# this function transforms `a_data` to `metadata`
model = DMRModel(k=10)
model.add_corpus(corpus, transform=transform_a_data_to_metadata)
# Now docs in `model` has non-default `metadata`, that generated from `a_data` field.
assert model.docs[0].metadata == '1'
assert model.docs[1].metadata == '2'
assert model.docs[2].metadata == '3'
Since version 0.5.0, tomotopy allows you to choose a parallelism algorithm. The algorithm provided in versions prior to 0.4.2 is COPY_MERGE, which is provided for all topic models. The new algorithm PARTITION, available since 0.5.0, makes training generally faster and more memory-efficient, but it is available at not all topic models.
The following chart shows the speed difference between the two algorithms based on the number of topics and the number of workers.
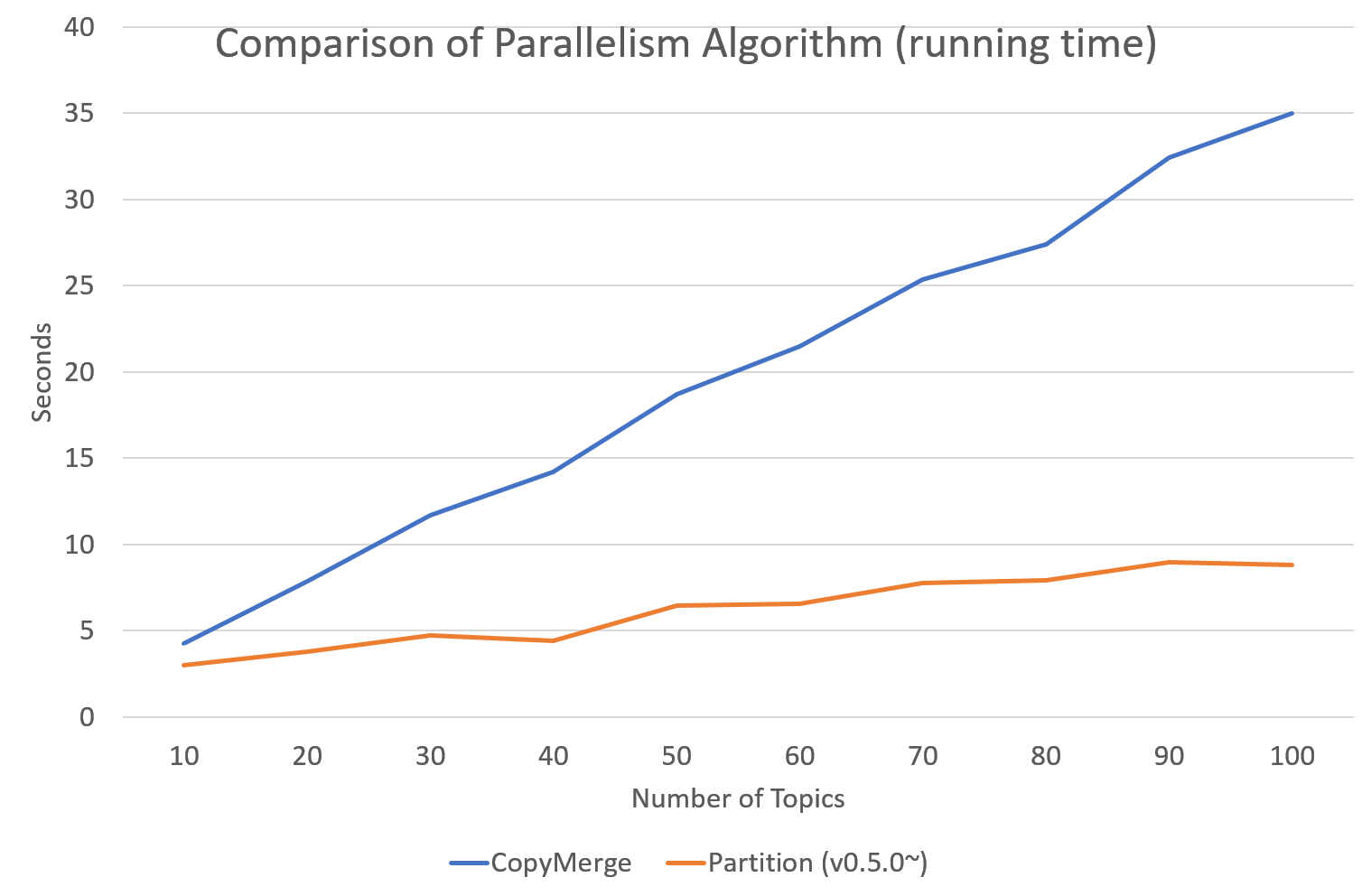
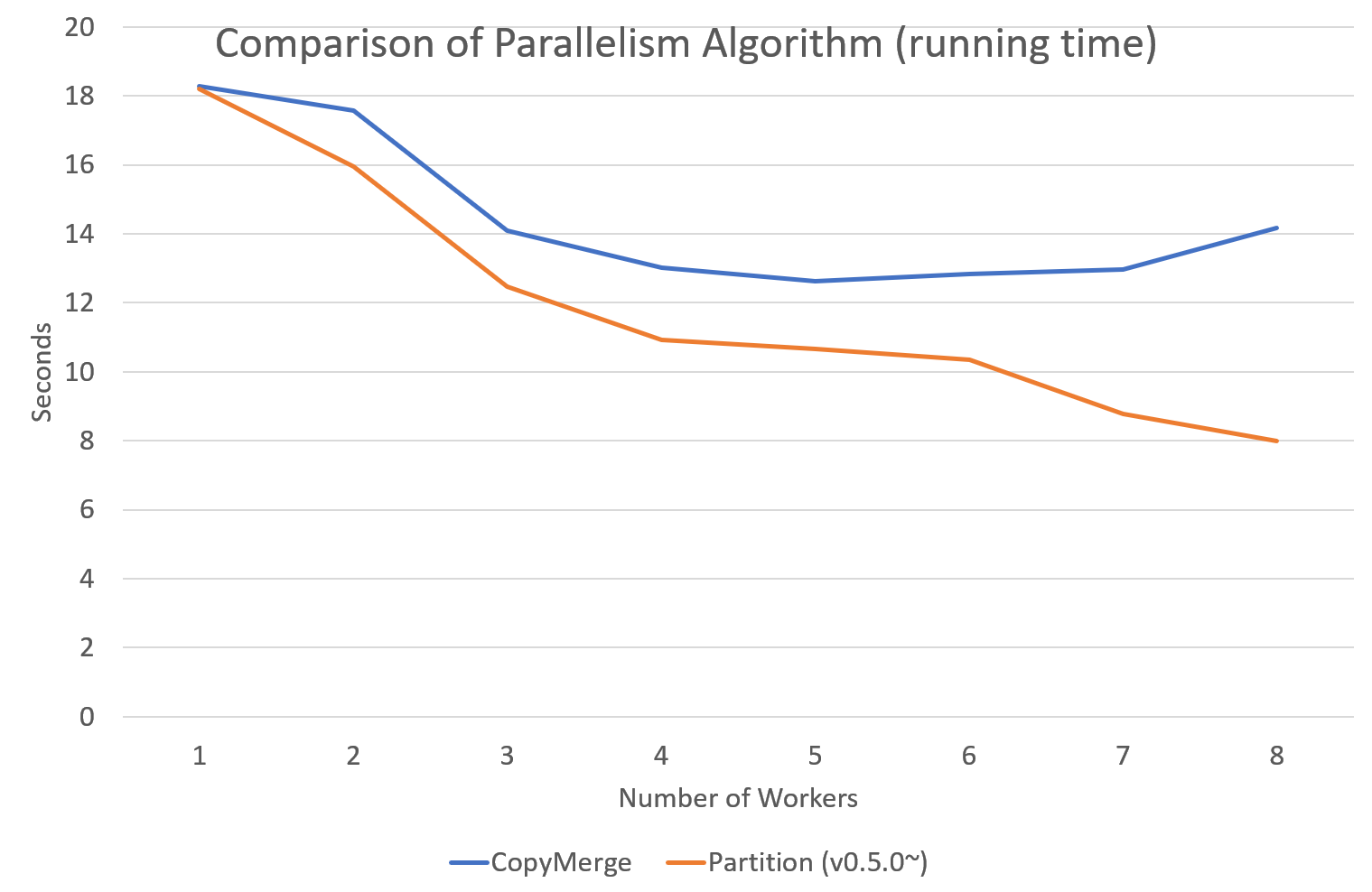
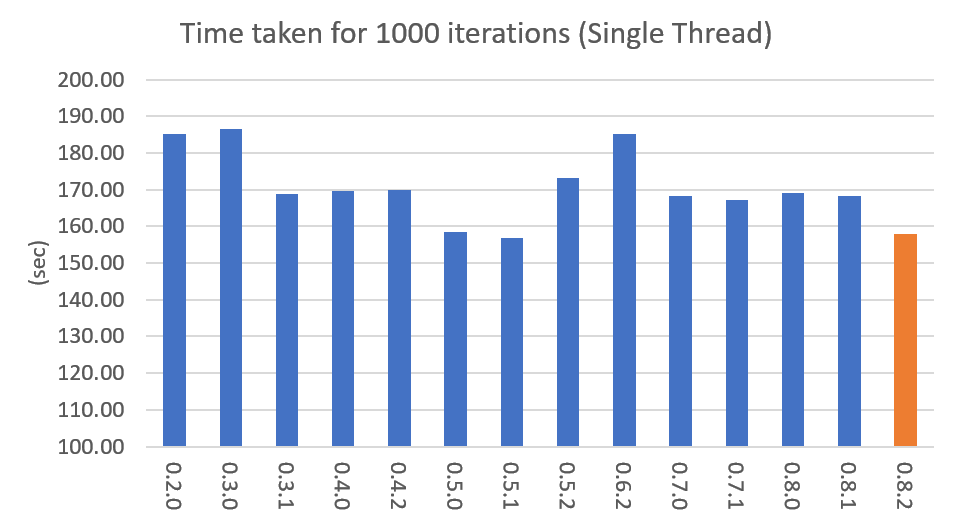
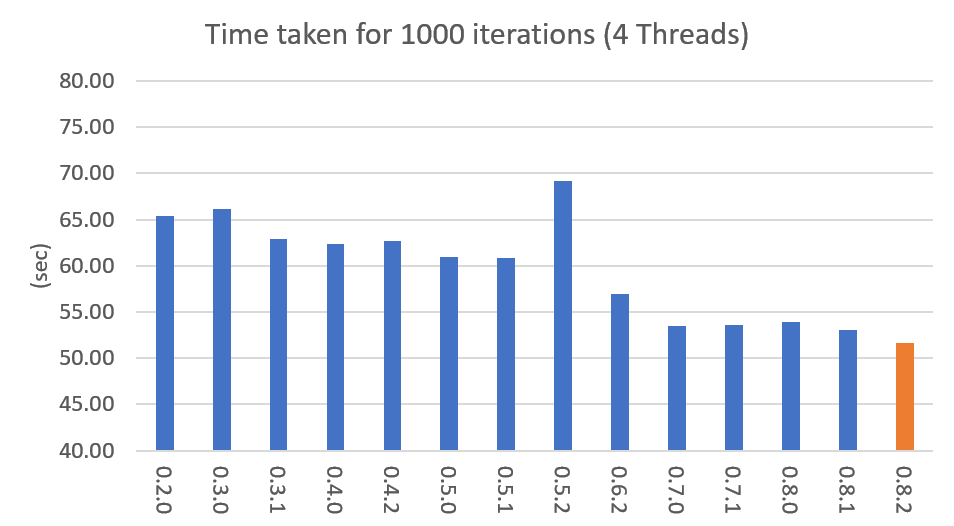
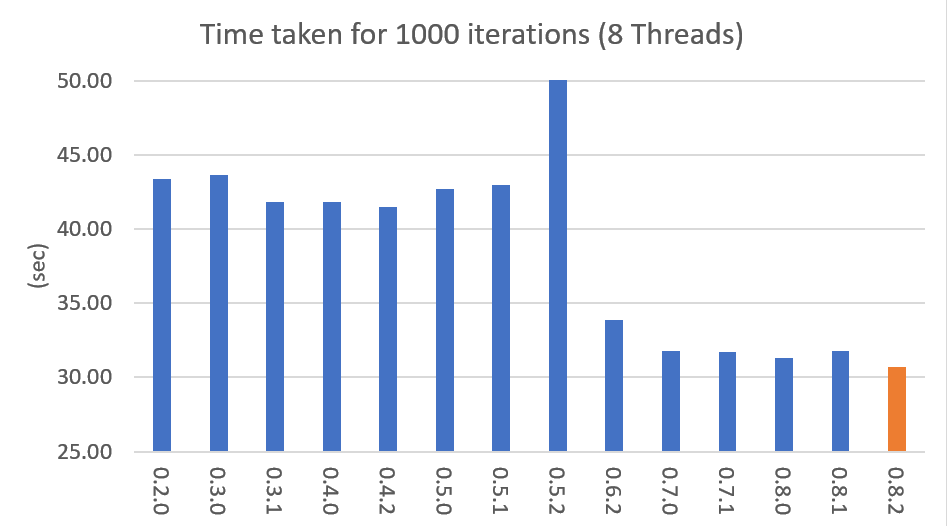
Performance changes by version are shown in the following graph. The time it takes to run the LDA model train with 1000 iteration was measured. (Docs: 11314, Vocab: 60382, Words: 2364724, Intel Xeon Gold 5120 @2.2GHz)
Since version 0.6.0, a new method tomotopy.LDAModel.set_word_prior has been added. It allows you to control word prior for each topic. For example, we can set the weight of the word 'church' to 1.0 in topic 0, and the weight to 0.1 in the rest of the topics by following codes. This means that the probability that the word 'church' is assigned to topic 0 is 10 times higher than the probability of being assigned to another topic. Therefore, most of 'church' is assigned to topic 0, so topic 0 contains many words related to 'church'. This allows to manipulate some topics to be placed at a specific topic number.
import tomotopy as tp
mdl = tp.LDAModel(k=20)
# add documents into `mdl`
# setting word prior
mdl.set_word_prior('church', [1.0 if k == 0 else 0.1 for k in range(20)])
See word_prior_example in example.py for more details.
You can find an example python code of tomotopy at https://github.com/bab2min/tomotopy/blob/main/examples/ .
You can also get the data file used in the example code at https://drive.google.com/file/d/18OpNijd4iwPyYZ2O7pQoPyeTAKEXa71J/view .
tomotopy is licensed under the terms of MIT License, meaning you can use it for any reasonable purpose and remain in complete ownership of all the documentation you produce.
- 0.13.0 (2024-08-05)
- New features
- Major features of Topic Model Viewer tomotopy.viewer.open_viewer() are ready now.
- tomotopy.LDAModel.get_hash() is added. You can get 128bit hash value of the model.
- Add an argument ngram_list to tomotopy.utils.SimpleTokenizer.
- Bug fixes
- Fixed inconsistent spans bug after Corpus.concat_ngrams is called.
- Optimized the bottleneck of tomotopy.LDAModel.load() and tomotopy.LDAModel.save() and improved its speed more than 10 times.
- 0.12.7 (2023-12-19)
- New features
- Added Topic Model Viewer tomotopy.viewer.open_viewer()
- Optimized the performance of tomotopy.utils.Corpus.process()
- Bug fixes
- Document.span now returns the ranges in character unit, not in byte unit.
- 0.12.6 (2023-12-11)
- New features
- Added some convenience features to tomotopy.LDAModel.train and tomotopy.LDAModel.set_word_prior.
- LDAModel.train now has new arguments callback, callback_interval and show_progres to monitor the training progress.
- LDAModel.set_word_prior now can accept Dict[int, float] type as its argument prior.
- 0.12.5 (2023-08-03)
- New features
- Added support for Linux ARM64 architecture.
- 0.12.4 (2023-01-22)
- New features
- Added support for macOS ARM64 architecture.
- Bug fixes
- Fixed an issue where tomotopy.Document.get_sub_topic_dist() raises a bad argument exception.
- Fixed an issue where exception raising sometimes causes crashes.
- 0.12.3 (2022-07-19)
- New features
- Now, inserting an empty document using tomotopy.LDAModel.add_doc() just ignores it instead of raising an exception. If the newly added argument ignore_empty_words is set to False, an exception is raised as before.
- tomotopy.HDPModel.purge_dead_topics() method is added to remove non-live topics from the model.
- Bug fixes
- Fixed an issue that prevents setting user defined values for nuSq in tomotopy.SLDAModel (by @jucendrero).
- Fixed an issue where tomotopy.utils.Coherence did not work for tomotopy.DTModel.
- Fixed an issue that often crashed when calling make_dic() before calling train().
- Resolved the problem that the results of tomotopy.DMRModel and tomotopy.GDMRModel are different even when the seed is fixed.
- The parameter optimization process of tomotopy.DMRModel and tomotopy.GDMRModel has been improved.
- Fixed an issue that sometimes crashed when calling tomotopy.PTModel.copy().
- 0.12.2 (2021-09-06)
- An issue where calling convert_to_lda of tomotopy.HDPModel with min_cf > 0, min_df > 0 or rm_top > 0 causes a crash has been fixed.
- A new argument from_pseudo_doc is added to tomotopy.Document.get_topics and tomotopy.Document.get_topic_dist. This argument is only valid for documents of PTModel, it enables to control a source for computing topic distribution.
- A default value for argument p of tomotopy.PTModel has been changed. The new default value is k * 10.
- Using documents generated by make_doc without calling infer doesn't cause a crash anymore, but just print warning messages.
- An issue where the internal C++ code isn't compiled at clang c++17 environment has been fixed.
- 0.12.1 (2021-06-20)
- An issue where tomotopy.LDAModel.set_word_prior() causes a crash has been fixed.
- Now tomotopy.LDAModel.perplexity and tomotopy.LDAModel.ll_per_word return the accurate value when TermWeight is not ONE.
- tomotopy.LDAModel.used_vocab_weighted_freq was added, which returns term-weighted frequencies of words.
- Now tomotopy.LDAModel.summary() shows not only the entropy of words, but also the entropy of term-weighted words.
- 0.12.0 (2021-04-26)
- Now tomotopy.DMRModel and tomotopy.GDMRModel support multiple values of metadata (see https://github.com/bab2min/tomotopy/blob/main/examples/dmr_multi_label.py )
- The performance of tomotopy.GDMRModel was improved.
- A copy() method has been added for all topic models to do a deep copy.
- An issue was fixed where words that are excluded from training (by min_cf, min_df) have incorrect topic id. Now all excluded words have -1 as topic id.
- Now all exceptions and warnings that generated by tomotopy follow standard Python types.
- Compiler requirements have been raised to C++14.
- 0.11.1 (2021-03-28)
- A critical bug of asymmetric alphas was fixed. Due to this bug, version 0.11.0 has been removed from releases.
- 0.11.0 (2021-03-26) (removed)
- A new topic model tomotopy.PTModel for short texts was added into the package.
- An issue was fixed where tomotopy.HDPModel.infer causes a segmentation fault sometimes.
- A mismatch of numpy API version was fixed.
- Now asymmetric document-topic priors are supported.
- Serializing topic models to bytes in memory is supported.
- An argument normalize was added to get_topic_dist(), get_topic_word_dist() and get_sub_topic_dist() for controlling normalization of results.
- Now tomotopy.DMRModel.lambdas and tomotopy.DMRModel.alpha give correct values.
- Categorical metadata supports for tomotopy.GDMRModel were added (see https://github.com/bab2min/tomotopy/blob/main/examples/gdmr_both_categorical_and_numerical.py ).
- Python3.5 support was dropped.
- 0.10.2 (2021-02-16)
- An issue was fixed where tomotopy.CTModel.train fails with large K.
- An issue was fixed where tomotopy.utils.Corpus loses their uid values.
- 0.10.1 (2021-02-14)
- An issue was fixed where tomotopy.utils.Corpus.extract_ngrams craches with empty input.
- An issue was fixed where tomotopy.LDAModel.infer raises exception with valid input.
- An issue was fixed where tomotopy.HLDAModel.infer generates wrong tomotopy.Document.path.
- Since a new parameter freeze_topics for tomotopy.HLDAModel.train was added, you can control whether to create a new topic or not when training.
- 0.10.0 (2020-12-19)
- The interface of tomotopy.utils.Corpus and of tomotopy.LDAModel.docs were unified. Now you can access the document in corpus with the same manner.
- __getitem__ of tomotopy.utils.Corpus was improved. Not only indexing by int, but also by Iterable[int], slicing are supported. Also indexing by uid is supported.
- New methods tomotopy.utils.Corpus.extract_ngrams and tomotopy.utils.Corpus.concat_ngrams were added. They extracts n-gram collocations using PMI and concatenates them into a single words.
- A new method tomotopy.LDAModel.add_corpus was added, and tomotopy.LDAModel.infer can receive corpus as input.
- A new module tomotopy.coherence was added. It provides the way to calculate coherence of the model.
- A paramter window_size was added to tomotopy.label.FoRelevance.
- An issue was fixed where NaN often occurs when training tomotopy.HDPModel.
- Now Python3.9 is supported.
- A dependency to py-cpuinfo was removed and the initializing of the module was improved.
- 0.9.1 (2020-08-08)
- Memory leaks of version 0.9.0 was fixed.
- tomotopy.CTModel.summary() was fixed.
- 0.9.0 (2020-08-04)
- The tomotopy.LDAModel.summary() method, which prints human-readable summary of the model, has been added.
- The random number generator of package has been replaced with EigenRand. It speeds up the random number generation and solves the result difference between platforms.
- Due to above, even if seed is the same, the model training result may be different from the version before 0.9.0.
- Fixed a training error in tomotopy.HDPModel.
- tomotopy.DMRModel.alpha now shows Dirichlet prior of per-document topic distribution by metadata.
- tomotopy.DTModel.get_count_by_topics() has been modified to return a 2-dimensional ndarray.
- tomotopy.DTModel.alpha has been modified to return the same value as tomotopy.DTModel.get_alpha().
- Fixed an issue where the metadata value could not be obtained for the document of tomotopy.GDMRModel.
- tomotopy.HLDAModel.alpha now shows Dirichlet prior of per-document depth distribution.
- tomotopy.LDAModel.global_step has been added.
- tomotopy.MGLDAModel.get_count_by_topics() now returns the word count for both global and local topics.
- tomotopy.PAModel.alpha, tomotopy.PAModel.subalpha, and tomotopy.PAModel.get_count_by_super_topic() have been added.
- 0.8.2 (2020-07-14)
- New properties tomotopy.DTModel.num_timepoints and tomotopy.DTModel.num_docs_by_timepoint have been added.
- A bug which causes different results with the different platform even if seeds were the same was partially fixed. As a result of this fix, now tomotopy in 32 bit yields different training results from earlier version.
- 0.8.1 (2020-06-08)
- A bug where tomotopy.LDAModel.used_vocabs returned an incorrect value was fixed.
- Now tomotopy.CTModel.prior_cov returns a covariance matrix with shape [k, k].
- Now tomotopy.CTModel.get_correlations with empty arguments returns a correlation matrix with shape [k, k].
- 0.8.0 (2020-06-06)
- Since NumPy was introduced in tomotopy, many methods and properties of tomotopy return not just list, but numpy.ndarray now.
- Tomotopy has a new dependency NumPy >= 1.10.0.
- A wrong estimation of tomotopy.HDPModel.infer was fixed.
- A new method about converting HDPModel to LDAModel was added.
- New properties including tomotopy.LDAModel.used_vocabs, tomotopy.LDAModel.used_vocab_freq and tomotopy.LDAModel.used_vocab_df were added into topic models.
- A new g-DMR topic model(tomotopy.GDMRModel) was added.
- An error at initializing tomotopy.label.FoRelevance in macOS was fixed.
- An error that occured when using tomotopy.utils.Corpus created without raw parameters was fixed.
- 0.7.1 (2020-05-08)
- tomotopy.Document.path was added for tomotopy.HLDAModel.
- A memory corruption bug in tomotopy.label.PMIExtractor was fixed.
- A compile error in gcc 7 was fixed.
- 0.7.0 (2020-04-18)
- tomotopy.DTModel was added into the package.
- A bug in tomotopy.utils.Corpus.save was fixed.
- A new method tomotopy.Document.get_count_vector was added into Document class.
- Now linux distributions use manylinux2010 and an additional optimization is applied.
- 0.6.2 (2020-03-28)
- A critical bug related to save and load was fixed. Version 0.6.0 and 0.6.1 have been removed from releases.
- 0.6.1 (2020-03-22) (removed)
- A bug related to module loading was fixed.
- 0.6.0 (2020-03-22) (removed)
- tomotopy.utils.Corpus class that manages multiple documents easily was added.
- tomotopy.LDAModel.set_word_prior method that controls word-topic priors of topic models was added.
- A new argument min_df that filters words based on document frequency was added into every topic model's __init__.
- tomotopy.label, the submodule about topic labeling was added. Currently, only tomotopy.label.FoRelevance is provided.
- 0.5.2 (2020-03-01)
- A segmentation fault problem was fixed in tomotopy.LLDAModel.add_doc.
- A bug was fixed that infer of tomotopy.HDPModel sometimes crashes the program.
- A crash issue was fixed of tomotopy.LDAModel.infer with ps=tomotopy.ParallelScheme.PARTITION, together=True.
- 0.5.1 (2020-01-11)
- A bug was fixed that tomotopy.SLDAModel.make_doc doesn't support missing values for y.
- Now tomotopy.SLDAModel fully supports missing values for response variables y. Documents with missing values (NaN) are included in modeling topic, but excluded from regression of response variables.
- 0.5.0 (2019-12-30)
- Now tomotopy.PAModel.infer returns both topic distribution nd sub-topic distribution.
- New methods get_sub_topics and get_sub_topic_dist were added into tomotopy.Document. (for PAModel)
- New parameter parallel was added for tomotopy.LDAModel.train and tomotopy.LDAModel.infer method. You can select parallelism algorithm by changing this parameter.
- tomotopy.ParallelScheme.PARTITION, a new algorithm, was added. It works efficiently when the number of workers is large, the number of topics or the size of vocabulary is big.
- A bug where rm_top didn't work at min_cf < 2 was fixed.
- 0.4.2 (2019-11-30)
- Wrong topic assignments of tomotopy.LLDAModel and tomotopy.PLDAModel were fixed.
- Readable __repr__ of tomotopy.Document and tomotopy.Dictionary was implemented.
- 0.4.1 (2019-11-27)
- A bug at init function of tomotopy.PLDAModel was fixed.
- 0.4.0 (2019-11-18)
- New models including tomotopy.PLDAModel and tomotopy.HLDAModel were added into the package.
- 0.3.1 (2019-11-05)
- An issue where get_topic_dist() returns incorrect value when min_cf or rm_top is set was fixed.
- The return value of get_topic_dist() of tomotopy.MGLDAModel document was fixed to include local topics.
- The estimation speed with tw=ONE was improved.
- 0.3.0 (2019-10-06)
- A new model, tomotopy.LLDAModel was added into the package.
- A crashing issue of HDPModel was fixed.
- Since hyperparameter estimation for HDPModel was implemented, the result of HDPModel may differ from previous versions.
- If you want to turn off hyperparameter estimation of HDPModel, set optim_interval to zero.
- 0.2.0 (2019-08-18)
- New models including tomotopy.CTModel and tomotopy.SLDAModel were added into the package.
- A new parameter option rm_top was added for all topic models.
- The problems in save and load method for PAModel and HPAModel were fixed.
- An occassional crash in loading HDPModel was fixed.
- The problem that ll_per_word was calculated incorrectly when min_cf > 0 was fixed.
- 0.1.6 (2019-08-09)
- Compiling errors at clang with macOS environment were fixed.
- 0.1.4 (2019-08-05)
- The issue when add_doc receives an empty list as input was fixed.
- The issue that tomotopy.PAModel.get_topic_words doesn't extract the word distribution of subtopic was fixed.
- 0.1.3 (2019-05-19)
- The parameter min_cf and its stopword-removing function were added for all topic models.
- 0.1.0 (2019-05-12)
- First version of tomotopy
- Eigen: This application uses the MPL2-licensed features of Eigen, a C++ template library for linear algebra. A copy of the MPL2 license is available at https://www.mozilla.org/en-US/MPL/2.0/. The source code of the Eigen library can be obtained at http://eigen.tuxfamily.org/.
- EigenRand: MIT License
- Mapbox Variant: BSD License
@software{minchul_lee_2022_6868418,
author = {Minchul Lee},
title = {bab2min/tomotopy: 0.12.3},
month = jul,
year = 2022,
publisher = {Zenodo},
version = {v0.12.3},
doi = {10.5281/zenodo.6868418},
url = {https://doi.org/10.5281/zenodo.6868418}
}