🌐 English, 한국어.
`tomotopy`는 토픽 모델링 툴인 `tomoto`의 Python 확장 버전입니다. `tomoto`는 c++로 작성된 깁스 샘플링 기반의 토픽 모델링 라이브러리로, 최신 CPU의 벡터화 기술을 활용하여 처리 속도를 최대로 끌어올렸습니다. 현재 버전의 `tomoto`에서는 다음과 같은 주요 토픽 모델들을 지원하고 있습니다.
- Latent Dirichlet Allocation (tomotopy.LDAModel)
- Labeled LDA (tomotopy.LLDAModel)
- Partially Labeled LDA (tomotopy.PLDAModel)
- Supervised LDA (tomotopy.SLDAModel)
- Dirichlet Multinomial Regression (tomotopy.DMRModel)
- Generalized Dirichlet Multinomial Regression (tomotopy.GDMRModel)
- Hierarchical Dirichlet Process (tomotopy.HDPModel)
- Hierarchical LDA (tomotopy.HLDAModel)
- Multi Grain LDA (tomotopy.MGLDAModel)
- Pachinko Allocation (tomotopy.PAModel)
- Hierarchical PA (tomotopy.HPAModel)
- Correlated Topic Model (tomotopy.CTModel)
- Dynamic Topic Model (tomotopy.DTModel)
- Pseudo-document based Topic Model (tomotopy.PTModel)
더 자세한 정보는 https://bab2min.github.io/tomotopy/index.kr.html 에서 확인하시길 바랍니다.
다음과 같이 pip를 이용하면 tomotopy를 쉽게 설치할 수 있습니다.
$ pip install --upgrade pip $ pip install tomotopy
지원하는 운영체제 및 Python 버전은 다음과 같습니다:
- Python 3.6 이상이 설치된 Linux (x86-64)
- Python 3.6 이상이 설치된 macOS 10.13나 그 이후 버전
- Python 3.6 이상이 설치된 Windows 7이나 그 이후 버전 (x86, x86-64)
- Python 3.6 이상이 설치된 다른 운영체제: 이 경우는 c++14 호환 컴파일러를 통한 소스코드 컴파일이 필요합니다.
설치가 끝난 뒤에는 다음과 같이 Python3에서 바로 import하여 tomotopy를 사용할 수 있습니다.
import tomotopy as tp print(tp.isa) # 'avx2'나 'avx', 'sse2', 'none'를 출력합니다.
현재 tomotopy는 가속을 위해 AVX2, AVX or SSE2 SIMD 명령어 세트를 활용할 수 있습니다. 패키지가 import될 때 현재 환경에서 활용할 수 있는 최선의 명령어 세트를 확인하여 최상의 모듈을 자동으로 가져옵니다. 만약 `tp.isa`가 `none`이라면 현재 환경에서 활용 가능한 SIMD 명령어 세트가 없는 것이므로 훈련에 오랜 시간이 걸릴 수 있습니다. 그러나 최근 대부분의 Intel 및 AMD CPU에서는 SIMD 명령어 세트를 지원하므로 SIMD 가속이 성능을 크게 향상시킬 수 있을 것입니다.
간단한 예제로 'sample.txt' 파일로 LDA 모델을 학습하는 코드는 다음과 같습니다.
import tomotopy as tp
mdl = tp.LDAModel(k=20)
for line in open('sample.txt'):
mdl.add_doc(line.strip().split())
for i in range(0, 100, 10):
mdl.train(10)
print('Iteration: {}\tLog-likelihood: {}'.format(i, mdl.ll_per_word))
for k in range(mdl.k):
print('Top 10 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=10))
mdl.summary()
`tomotopy`는 주제 분포와 단어 분포를 추론하기 위해 Collapsed Gibbs-Sampling(CGS) 기법을 사용합니다. 일반적으로 CGS는 `gensim의 LdaModel`_가 이용하는 Variational Bayes(VB) 보다 느리게 수렴하지만 각각의 반복은 빠르게 계산 가능합니다. 게다가 `tomotopy`는 멀티스레드를 지원하므로 SIMD 명령어 세트뿐만 아니라 다중 코어 CPU의 장점까지 활용할 수 있습니다. 이 덕분에 각각의 반복이 훨씬 빠르게 계산 가능합니다.
다음의 차트는 tomotopy`와 `gensim`의 LDA 모형 실행 시간을 비교하여 보여줍니다. 입력 문헌은 영어 위키백과에서 가져온 1000개의 임의 문서이며 전체 문헌 집합은 총 1,506,966개의 단어로 구성되어 있습니다. (약 10.1 MB). `tomotopy`는 200회를, `gensim 10회를 반복 학습하였습니다.
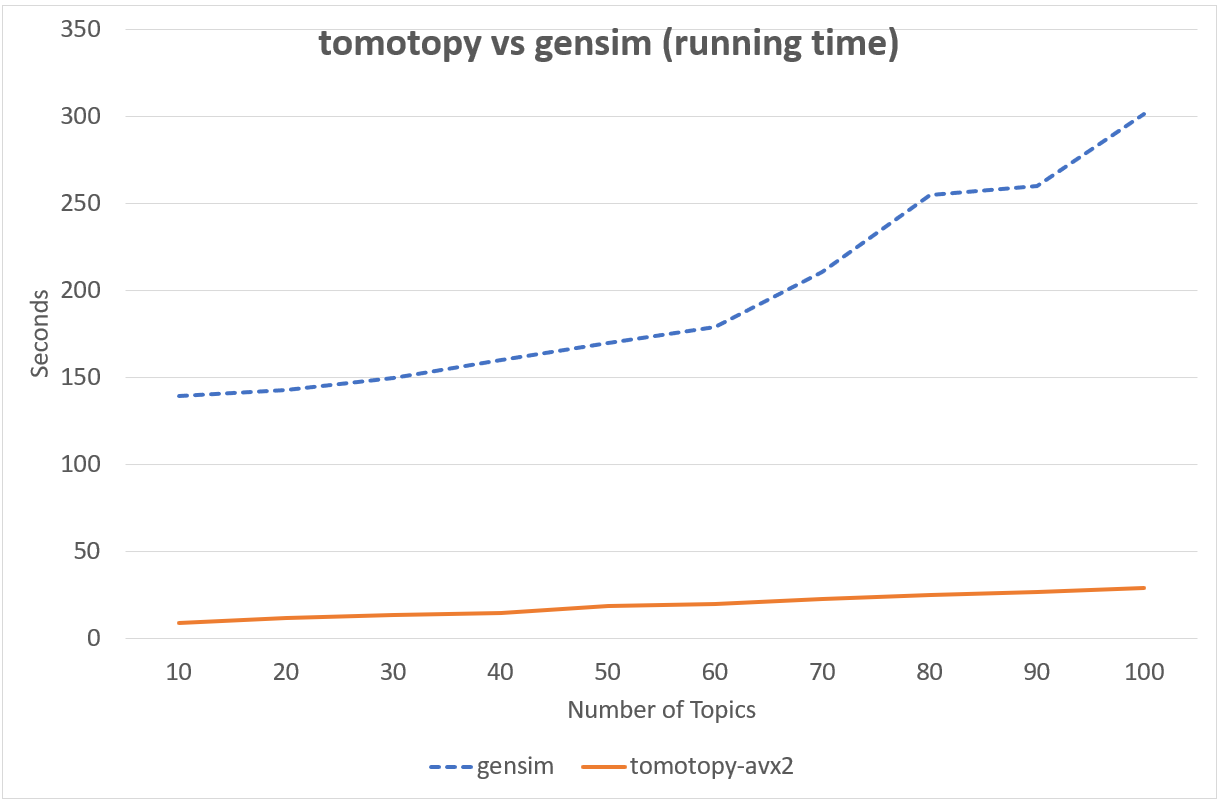
Intel i5-6600, x86-64 (4 cores)에서의 성능
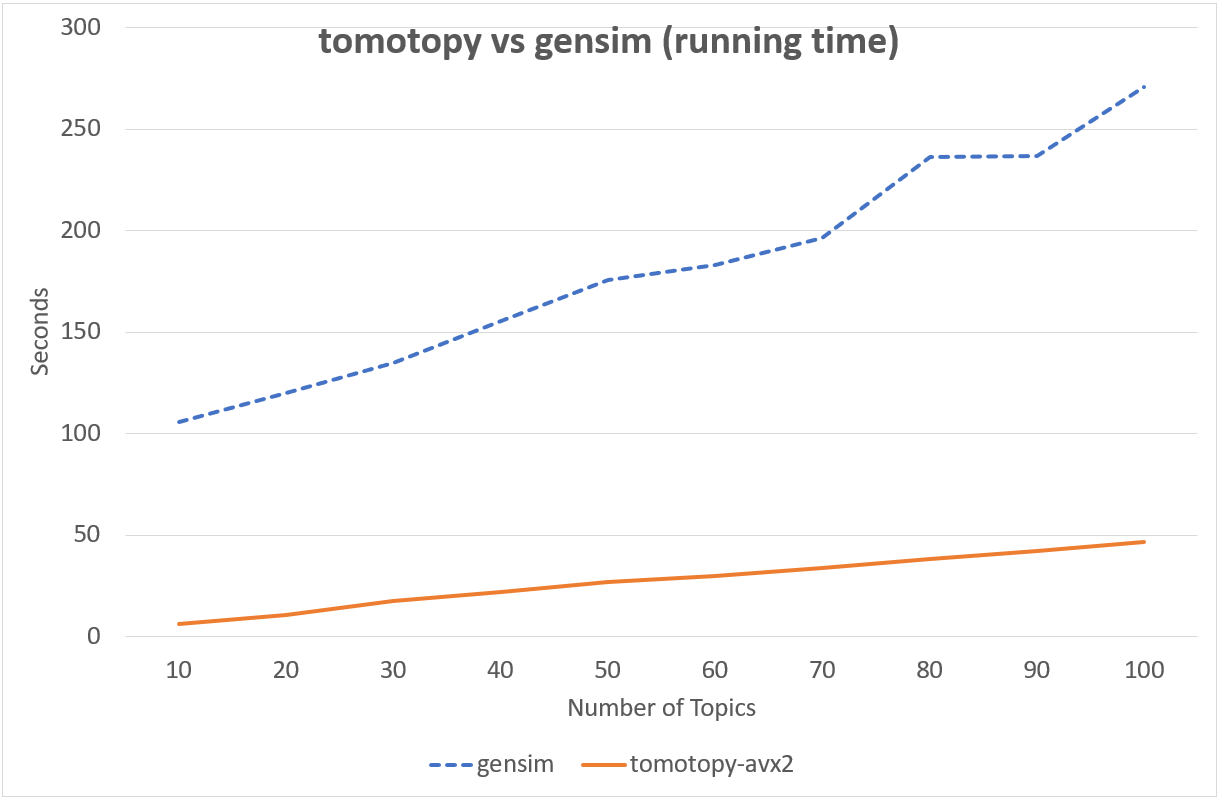
Intel Xeon E5-2620 v4, x86-64 (8 cores, 16 threads)에서의 성능
`tomotopy`가 20배 더 많이 반복하였지만 전체 실행시간은 `gensim`보다 5~10배 더 빨랐습니다. 또한 `tomotopy`는 전반적으로 안정적인 결과를 보여주고 있습니다.
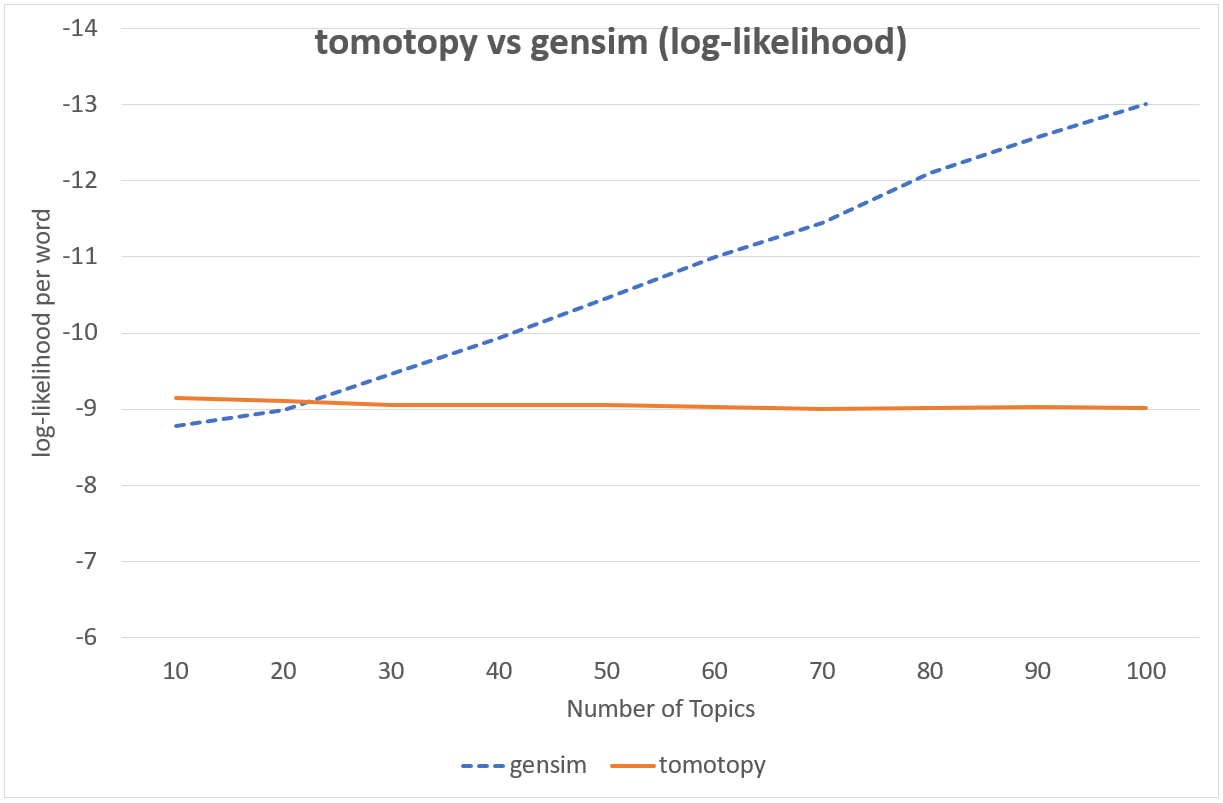
CGS와 VB는 서로 접근방법이 아예 다른 기법이기 때문에 둘을 직접적으로 비교하기는 어렵습니다만, 실용적인 관점에서 두 기법의 속도와 결과물을 비교해볼 수 있습니다. 다음의 차트에는 두 기법이 학습 후 보여준 단어당 로그 가능도 값이 표현되어 있습니다.
어떤 SIMD 명령어 세트를 사용하는지는 성능에 큰 영향을 미칩니다. 다음 차트는 SIMD 명령어 세트에 따른 성능 차이를 보여줍니다.
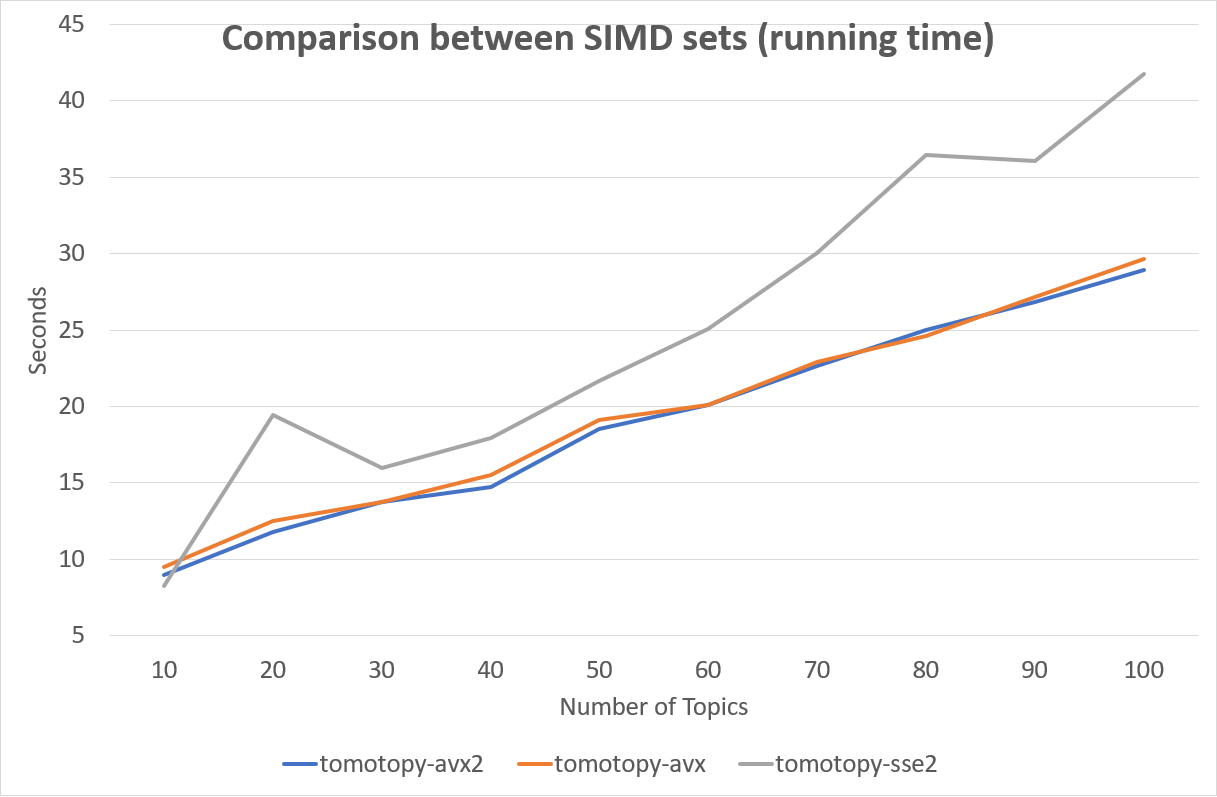
다행히도 최신 x86-64 CPU들은 대부분 AVX2 명령어 세트를 지원하기 때문에 대부분의 경우 AVX2의 높은 성능을 활용할 수 있을 것입니다.
tomotopy`는 각각의 토픽 모델 클래스에 대해 `save`와 `load 메소드를 제공합니다. 따라서 학습이 끝난 모델을 언제든지 파일에 저장하거나, 파일로부터 다시 읽어와서 다양한 작업을 수행할 수 있습니다.
import tomotopy as tp
mdl = tp.HDPModel()
for line in open('sample.txt'):
mdl.add_doc(line.strip().split())
for i in range(0, 100, 10):
mdl.train(10)
print('Iteration: {}\tLog-likelihood: {}'.format(i, mdl.ll_per_word))
# 파일에 저장
mdl.save('sample_hdp_model.bin')
# 파일로부터 불러오기
mdl = tp.HDPModel.load('sample_hdp_model.bin')
for k in range(mdl.k):
if not mdl.is_live_topic(k): continue
print('Top 10 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=10))
# 저장된 모델이 HDP 모델이었기 때문에,
# LDA 모델에서 이 파일을 읽어오려고 하면 예외가 발생합니다.
mdl = tp.LDAModel.load('sample_hdp_model.bin')
파일로부터 모델을 불러올 때는 반드시 저장된 모델의 타입과 읽어올 모델의 타입이 일치해야합니다.
이에 대해서는 `tomotopy.LDAModel.save`와 `tomotopy.LDAModel.load`에서 더 자세한 내용을 확인할 수 있습니다.
interactive_model_viewer_demo.mp4
v0.13.0부터는 토픽 모델링의 결과를 인터랙티브 뷰어를 통해 살펴보는 것도 가능합니다.
import tomotopy as tp model = tp.LDAModel(...) # ... some training codes ... tp.viewer.open_viewer(model, host="localhost", port=9999) # And open http://localhost:9999 in your web browser!
이미 저장된 모델 파일이 있다면 다음 명령행을 통해서도 간단히 뷰어를 구동할 수 있습니다.
python -m tomotopy.viewer a_trained_model.bin --host localhost --port 9999
자세한 내용은 `tomotopy.viewer`을 참조하세요.
토픽 모델은 크게 2가지 목적으로 사용할 수 있습니다. 기본적으로는 문헌 집합으로부터 모델을 학습하여 문헌 내의 주제들을 발견하기 위해 토픽 모델을 사용할 수 있으며, 더 나아가 학습된 모델을 활용하여 학습할 때는 주어지지 않았던 새로운 문헌에 대해 주제 분포를 추론하는 것도 가능합니다. 전자의 과정에서 사용되는 문헌(학습 과정에서 사용되는 문헌)을 모델 안의 문헌, 후자의 과정에서 주어지는 새로운 문헌(학습 과정에 포함되지 않았던 문헌)을 **모델 밖의 문헌**이라고 가리키도록 하겠습니다.
`tomotopy`에서 이 두 종류의 문헌을 생성하는 방법은 다릅니다. **모델 안의 문헌**은 `tomotopy.LDAModel.add_doc`을 이용하여 생성합니다. add_doc은 `tomotopy.LDAModel.train`을 시작하기 전까지만 사용할 수 있습니다. 즉 train을 시작한 이후로는 학습 문헌 집합이 고정되기 때문에 add_doc을 이용하여 새로운 문헌을 모델 내에 추가할 수 없습니다.
또한 생성된 문헌의 인스턴스를 얻기 위해서는 다음과 같이 `tomotopy.LDAModel.docs`를 사용해야 합니다.
mdl = tp.LDAModel(k=20)
idx = mdl.add_doc(words)
if idx < 0: raise RuntimeError("Failed to add doc")
doc_inst = mdl.docs[idx]
# doc_inst is an instance of the added document
**모델 밖의 문헌**은 `tomotopy.LDAModel.make_doc`을 이용해 생성합니다. make_doc은 add_doc과 반대로 train을 시작한 이후에 사용할 수 있습니다. 만약 train을 시작하기 전에 make_doc을 사용할 경우 올바르지 않은 결과를 얻게 되니 이 점 유의하시길 바랍니다. make_doc은 바로 인스턴스를 반환하므로 반환값을 받아 바로 사용할 수 있습니다.
mdl = tp.LDAModel(k=20) # add_doc ... mdl.train(100) doc_inst = mdl.make_doc(unseen_doc) # doc_inst is an instance of the unseen document
`tomotopy.LDAModel.make_doc`을 이용해 새로운 문헌을 생성했다면 이를 모델에 입력해 주제 분포를 추론하도록 할 수 있습니다. 새로운 문헌에 대한 추론은 `tomotopy.LDAModel.infer`를 사용합니다.
mdl = tp.LDAModel(k=20)
# add_doc ...
mdl.train(100)
doc_inst = mdl.make_doc(unseen_doc)
topic_dist, ll = mdl.infer(doc_inst)
print("Topic Distribution for Unseen Docs: ", topic_dist)
print("Log-likelihood of inference: ", ll)
infer 메소드는 tomotopy.Document 인스턴스 하나를 추론하거나 tomotopy.Document 인스턴스의 `list`를 추론하는데 사용할 수 있습니다. 자세한 것은 `tomotopy.LDAModel.infer`을 참조하길 바랍니다.
tomotopy`의 모든 토픽 모델들은 각자 별도의 내부적인 문헌 타입을 가지고 있습니다. 그리고 이 문헌 타입들에 맞는 문헌들은 각 모델의 `add_doc 메소드를 통해 생성될 수 있습니다. 하지만 이 때문에 동일한 목록의 문헌들을 서로 다른 토픽 모델에 입력해야 하는 경우 매 모델에 각 문헌을 추가할때마다 add_doc`을 호출해야하기 때문에 비효율이 발생합니다. 따라서 `tomotopy`에서는 여러 문헌을 묶어서 관리해주는 `tomotopy.utils.Corpus 클래스를 제공합니다. 토픽 모델 객체를 생성할때 tomotopy.utils.Corpus`를 `__init__ 메소드의 corpus 인자로 넘겨줌으로써 어떤 모델에든 쉽게 문헌들을 삽입할 수 있게 해줍니다. `tomotopy.utils.Corpus`를 토픽 모델에 삽입하면 corpus 객체가 가지고 있는 문헌들 전부가 모델에 자동으로 삽입됩니다.
그런데 일부 토픽 모델의 경우 문헌을 생성하기 위해 서로 다른 데이터를 요구합니다. 예를 들어 tomotopy.DMRModel`는 `metadata`라는 `str 타입의 데이터를 요구하고, tomotopy.PLDAModel`는 `labels`라는 `List[str] 타입의 데이터를 요구합니다. 그러나 `tomotopy.utils.Corpus`는 토픽 모델에 종속되지 않은 독립적인 문헌 데이터를 보관하기 때문에, corpus가 가지고 있는 문헌 데이터가 실제 토픽 모델이 요구하는 데이터와 일치하지 않을 가능성이 있습니다. 이 경우 `transform`라는 인자를 통해 corpus 내의 데이터를 변형시켜 토픽 모델이 요구하는 실제 데이터와 일치시킬 수 있습니다. 자세한 내용은 아래의 코드를 확인해주세요:
from tomotopy import DMRModel
from tomotopy.utils import Corpus
corpus = Corpus()
corpus.add_doc("a b c d e".split(), a_data=1)
corpus.add_doc("e f g h i".split(), a_data=2)
corpus.add_doc("i j k l m".split(), a_data=3)
model = DMRModel(k=10)
model.add_corpus(corpus)
# `corpus`에 있던 `a_data`는 사라지고
# `DMRModel`이 요구하는 `metadata`에는 기본값인 빈 문자열이 채워집니다.
assert model.docs[0].metadata == ''
assert model.docs[1].metadata == ''
assert model.docs[2].metadata == ''
def transform_a_data_to_metadata(misc: dict):
return {'metadata': str(misc['a_data'])}
# 이 함수는 `a_data`를 `metadata`로 변환합니다.
model = DMRModel(k=10)
model.add_corpus(corpus, transform=transform_a_data_to_metadata)
# 이제 `model`에는 기본값이 아닌 `metadata`가 입력됩니다. 이들은 `transform`에 의해 `a_data`로부터 생성됩니다.
assert model.docs[0].metadata == '1'
assert model.docs[1].metadata == '2'
assert model.docs[2].metadata == '3'
`tomotopy`는 0.5.0버전부터 병렬 알고리즘을 고를 수 있는 선택지를 제공합니다. 0.4.2 이전버전까지 제공되던 알고리즘은 `COPY_MERGE`로 이 기법은 모든 토픽 모델에 사용 가능합니다. 새로운 알고리즘인 `PARTITION`은 0.5.0이후부터 사용가능하며, 이를 사용하면 더 빠르고 메모리 효율적으로 학습을 수행할 수 있습니다. 단 이 기법은 일부 토픽 모델에 대해서만 사용 가능합니다.
다음 차트는 토픽 개수와 코어 개수에 따라 두 기법의 속도 차이를 보여줍니다.
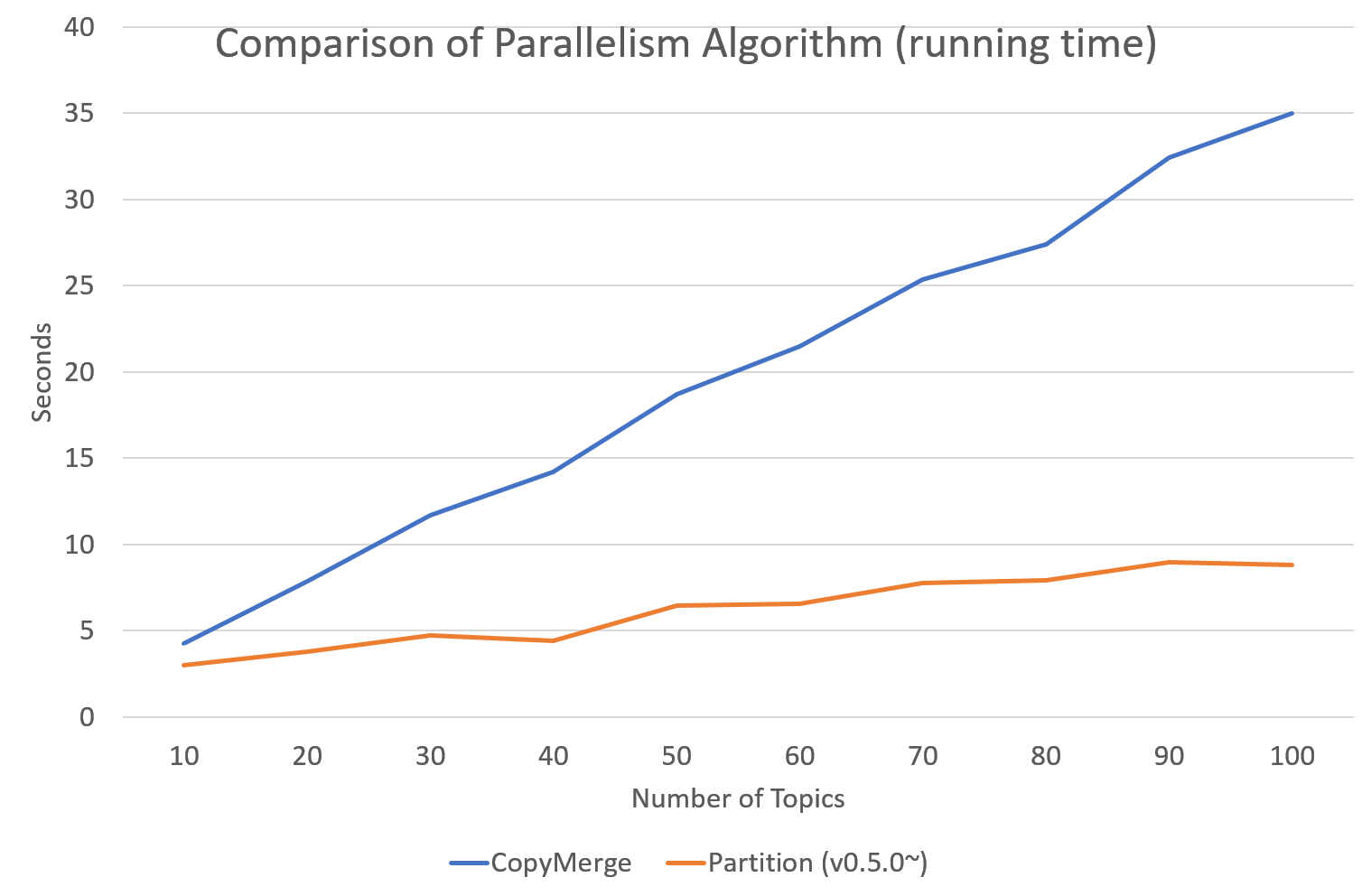
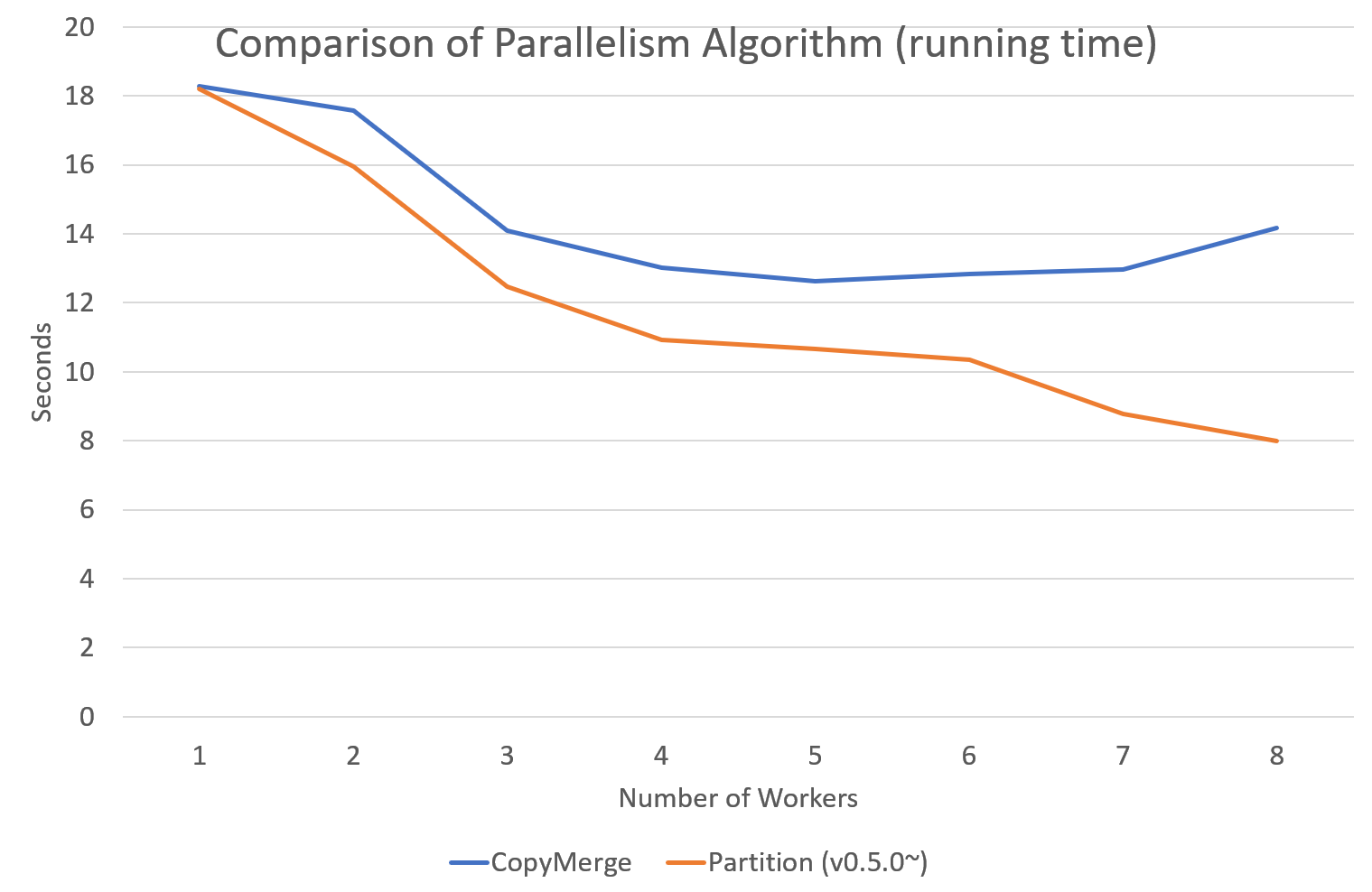
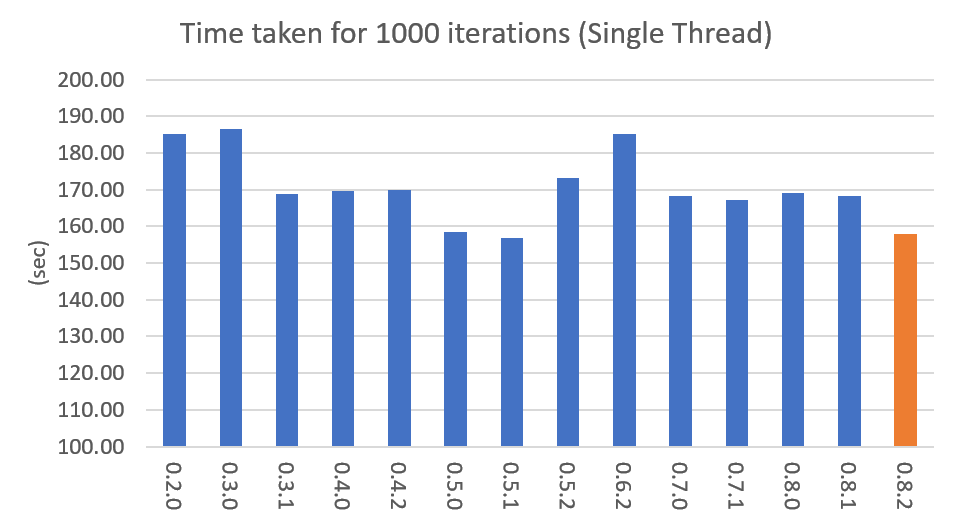
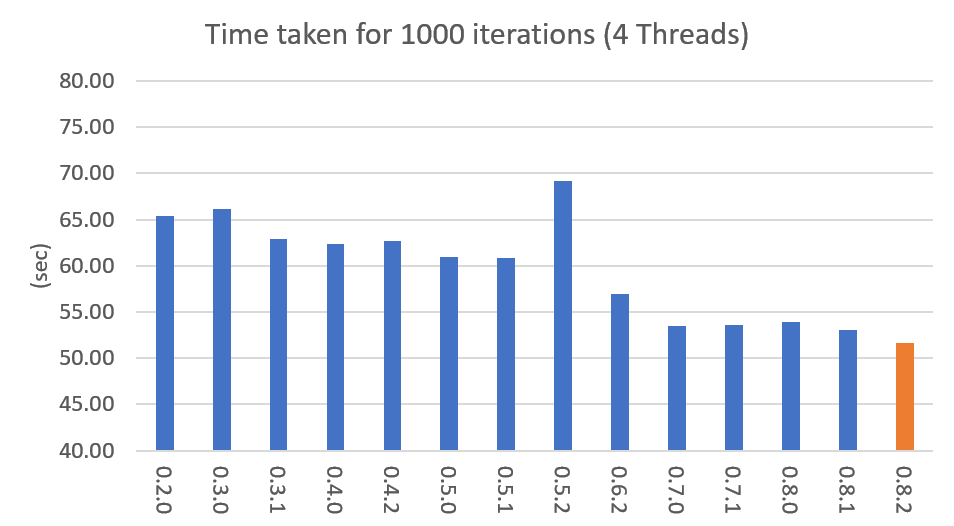
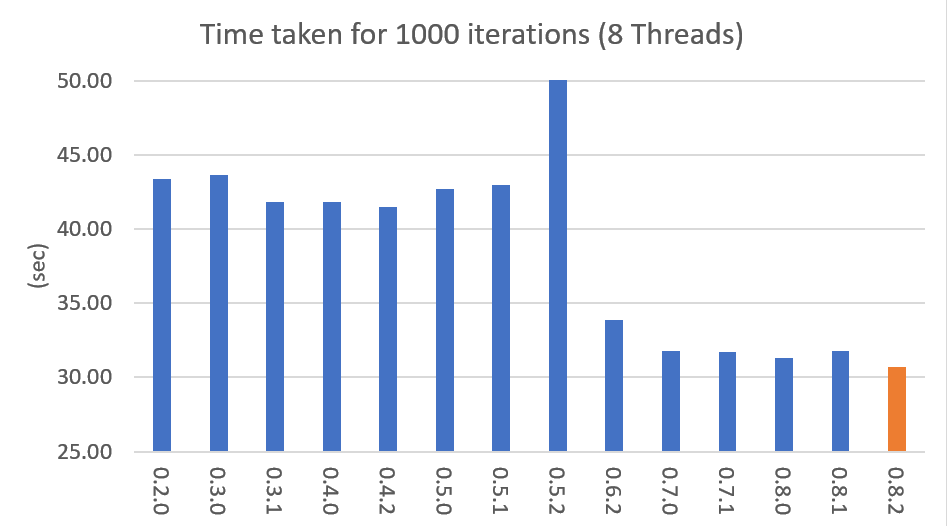
아래 그래프는 버전별 속도 차이를 표시한 것입니다. LDA모델로 1000회 iteration을 수행시 걸리는 시간을 초 단위로 표시하였습니다. (Docs: 11314, Vocab: 60382, Words: 2364724, Intel Xeon Gold 5120 @2.2GHz)
0.6.0 버전부터 `tomotopy.LDAModel.set_word_prior`라는 메소드가 추가되었습니다. 이 메소드로 특정 단어의 사전분포를 조절할 수 있습니다. 예를 들어 다음 코드처럼 단어 'church'의 가중치를 Topic 0에 대해서는 1.0, 나머지 Topic에 대해서는 0.1로 설정할 수 있습니다. 이는 단어 'church'가 Topic 0에 할당될 확률이 다른 Topic에 할당될 확률보다 10배 높다는 것을 의미하며, 따라서 대부분의 'church'는 Topic 0에 할당되게 됩니다. 그리고 학습을 거치며 'church'와 관련된 단어들 역시 Topic 0에 모이게 되므로, 최종적으로 Topic 0은 'church'와 관련된 주제가 될 것입니다. 이를 통해 특정 내용의 주제를 원하는 Topic 번호에 고정시킬 수 있습니다.
import tomotopy as tp
mdl = tp.LDAModel(k=20)
# add documents into `mdl`
# setting word prior
mdl.set_word_prior('church', [1.0 if k == 0 else 0.1 for k in range(20)])
자세한 내용은 example.py`의 `word_prior_example 함수를 참조하십시오.
tomotopy의 Python3 예제 코드는 https://github.com/bab2min/tomotopy/blob/main/examples/ 를 확인하시길 바랍니다.
예제 코드에서 사용했던 데이터 파일은 https://drive.google.com/file/d/18OpNijd4iwPyYZ2O7pQoPyeTAKEXa71J/view 에서 다운받을 수 있습니다.
`tomotopy`는 MIT License 하에 배포됩니다.
- 0.13.0 (2024-08-05)
- 0.12.5 (2023-08-03)
- 신규 기능
- Linux ARM64 아키텍처에 대한 지원을 추가했습니다.
- 0.12.4 (2023-01-22)
- New features
- macOS ARM64 아키텍처에 대한 지원을 추가했습니다.
- Bug fixes
- `tomotopy.Document.get_sub_topic_dist()`가 bad argument 예외를 발생시키는 문제를 해결했습니다.
- 예외 발생이 종종 크래시를 발생시키는 문제를 해결했습니다.
- 0.12.3 (2022-07-19)
- 버그 수정
- tomotopy.SLDAModel`에서 `nuSq 값을 지정할 때 발생하는 문제를 해결했습니다. (by @jucendrero)
- `tomotopy.utils.Coherence`가 `tomotopy.DTModel`에 대해서 작동하지 않는 문제를 해결했습니다.
- train() 호출 전에 `make_dic()`을 호출할 때 종종 크래시가 발생하는 문제를 해결했습니다.
- seed가 고정된 상태에서도 tomotopy.DMRModel, `tomotopy.GDMRModel`의 결과가 다르게 나오는 문제를 해결했습니다.
- tomotopy.DMRModel, `tomotopy.GDMRModel`의 파라미터 최적화 과정이 부정확하던 문제를 해결했습니다.
- tomotopy.PTModel.copy() 호출 시 종종 크래시가 발생하는 문제를 해결했습니다.
- 싱글스레드에서의 작동 효율을 개선했습니다.
- 0.12.2 (2021-09-06)
- min_cf > 0, `min_df > 0`나 `rm_top > 0`로 설정된 `tomotopy.HDPModel`에서 `convert_to_lda`를 호출할때 크래시가 발생하는 문제를 해결했습니다.
- tomotopy.Document.get_topics`와 `tomotopy.Document.get_topic_dist`에 `from_pseudo_doc 인자가 추가되었습니다. 이 인자는 `PTModel`에 대해서만 유효하며, 이를 통해 토픽 분포를 구할 때 가상 문헌을 사용할지 여부를 선택할 수 있습니다.
- tomotopy.PTModel 생성시 기본 인자값이 변경되었습니다. `p`를 생략시 `k * 10`으로 설정됩니다.
- make_doc`으로 생성한 문헌을 `infer 없이 사용할 경우 발생하는 크래시를 해결하고 경고 메세지를 추가했습니다.
- 내부 C++코드가 clang c++17 환경에서 컴파일에 실패하는 문제를 해결했습니다.
- 0.12.1 (2021-06-20)
- `tomotopy.LDAModel.set_word_prior()`가 크래시를 발생시키던 문제를 해결했습니다.
- 이제 `tomotopy.LDAModel.perplexity`와 `tomotopy.LDAModel.ll_per_word`가 TermWeight가 ONE이 아닌 경우에도 정확한 값을 반환합니다.
- 용어가중치가 적용된 빈도수를 반환하는 `tomotopy.LDAModel.used_vocab_weighted_freq`가 추가되었습니다.
- 이제 `tomotopy.LDAModel.summary()`가 단어의 엔트로피뿐만 아니라, 용어 가중치가 적용된 단어의 엔트로피도 함께 보여줍니다.
- 0.12.0 (2021-04-26)
- 이제 `tomotopy.DMRModel`와 `tomotopy.GDMRModel`가 다중 메타데이터를 지원합니다. (https://github.com/bab2min/tomotopy/blob/main/examples/dmr_multi_label.py 참조)
- `tomotopy.GDMRModel`의 성능이 개선되었습니다.
- 깊은 복사를 수행하는 copy() 메소드가 모든 토픽 모델 클래스에 추가되었습니다.
- min_cf, min_df 등에 의해 학습에서 제외된 단어가 잘못된 토픽id값을 가지는 문제가 해결되었습니다. 이제 제외단 단어들은 토픽id로 모두 -1 값을 가집니다.
- 이제 `tomotopy`에 의해 생성되는 예외 및 경고가 모두 Python 표준 타입을 따릅니다.
- 컴파일러 요구사항이 C++14로 상향되었습니다.
- 0.11.1 (2021-03-28)
- 비대칭 alpha와 관련된 치명적인 버그가 수정되었습니다. 이 버그로 인해 0.11.0 버전은 릴리즈에서 삭제되었습니다.
- 0.11.0 (2021-03-26)
- 짧은 텍스트를 위한 토픽 모델인 `tomotopy.PTModel`가 추가되었습니다.
- `tomotopy.HDPModel.infer`가 종종 segmentation fault를 발생시키는 문제가 해결되었습니다.
- numpy API 버전 충돌이 해결되었습니다.
- 이제 비대칭 문헌-토픽 사전 분포가 지원됩니다.
- 토픽 모델 객체를 메모리 상의 `bytes`로 직렬화하는 기능이 지원됩니다.
- get_topic_dist(), get_topic_word_dist(), get_sub_topic_dist()`에 결과의 정규화 여부를 조절하는 `normalize 인자가 추가되었습니다.
- `tomotopy.DMRModel.lambdas`와 `tomotopy.DMRModel.alpha`가 잘못된 값을 제공하던 문제가 해결되었습니다.
- `tomotopy.GDMRModel`에 범주형 메타데이터 지원이 추가되었습니다. (https://github.com/bab2min/tomotopy/blob/main/examples/gdmr_both_categorical_and_numerical.py 참조)
- Python3.5 지원이 종료되었습니다.
- 0.10.1 (2021-02-14)
- 0.10.0 (2020-12-19)
- tomotopy.utils.Corpus`와 `tomotopy.LDAModel.docs 간의 인터페이스가 통일되었습니다. 이제 동일한 방법으로 코퍼스 내의 문헌들에 접근할 수 있습니다.
- `tomotopy.utils.Corpus`의 __getitem__이 개선되었습니다. int 타입 인덱싱뿐만 아니라 Iterable[int]나 slicing를 이용한 다중 인덱싱, uid를 이용한 인덱싱 등이 제공됩니다.
- `tomotopy.utils.Corpus.extract_ngrams`와 `tomotopy.utils.Corpus.concat_ngrams`이 추가되었습니다. PMI를 이용해 코퍼스 내에서 자동으로 n-gram collocation을 발견해 한 단어로 합치는 기능을 수행합니다.
- `tomotopy.LDAModel.add_corpus`가 추가되었고, `tomotopy.LDAModel.infer`가 Raw 코퍼스를 입력으로 받을 수 있게 되었습니다.
- tomotopy.coherence 모듈이 추가되었습니다. 생성된 토픽 모델의 coherence를 계산하는 기능을 담당합니다.
- `tomotopy.label.FoRelevance`에 window_size 파라미터가 추가되었습니다.
- tomotopy.HDPModel 학습 시 종종 NaN이 발생하는 문제를 해결했습니다.
- 이제 Python3.9를 지원합니다.
- py-cpuinfo에 대한 의존성이 제거되고, 모듈 로딩속도가 개선되었습니다.
- 0.9.1 (2020-08-08)
- 0.9.0 버전의 메모리 누수 문제가 해결되었습니다.
- `tomotopy.CTModel.summary()`가 잘못된 결과를 출력하는 문제가 해결되었습니다.
- 0.9.0 (2020-08-04)
- 모델의 상태를 알아보기 쉽게 출력해주는 tomotopy.LDAModel.summary() 메소드가 추가되었습니다.
- 난수 생성기를 `EigenRand`_로 대체하여 생성 속도를 높이고 플랫폼 간의 결과 차이를 해소하였습니다.
- 이로 인해 `seed`가 동일해도 모델 학습 결과가 0.9.0 이전 버전과 달라질 수 있습니다.
- `tomotopy.HDPModel`에서 간헐적으로 발생하는 학습 오류를 수정했습니다.
- 이제 `tomotopy.DMRModel.alpha`가 메타데이터별 토픽 분포의 사전 파라미터를 보여줍니다.
- `tomotopy.DTModel.get_count_by_topics()`가 2차원 `ndarray`를 반환하도록 수정되었습니다.
- `tomotopy.DTModel.alpha`가 `tomotopy.DTModel.get_alpha()`와 동일한 값을 반환하도록 수정되었습니다.
- tomotopy.GDMRModel`의 document에 대해 `metadata 값을 얻어올 수 없던 문제가 해결되었습니다.
- 이제 `tomotopy.HLDAModel.alpha`가 문헌별 계층 분포의 사전 파라미터를 보여줍니다.
- `tomotopy.LDAModel.global_step`이 추가되었습니다.
- 이제 `tomotopy.MGLDAModel.get_count_by_topics()`가 전역 토픽과 지역 토픽 모두의 단어 개수를 보여줍니다.
- tomotopy.PAModel.alpha, tomotopy.PAModel.subalpha, `tomotopy.PAModel.get_count_by_super_topic()`이 추가되었습니다.
- 0.8.2 (2020-07-14)
- tomotopy.DTModel.num_timepoints`와 `tomotopy.DTModel.num_docs_by_timepoint 프로퍼티가 추가되었습니다.
- `seed`가 동일해도 플랫폼이 다르면 다른 결과를 내던 문제가 일부 해결되었습니다. 이로 인해 32bit 버전의 모델 학습 결과가 이전 버전과는 달라졌습니다.
- 0.8.1 (2020-06-08)
- `tomotopy.LDAModel.used_vocabs`가 잘못된 값을 반환하는 버그가 수정되었습니다.
- 이제 tomotopy.CTModel.prior_cov`가 `[k, k] 모양의 공분산 행렬을 반환합니다.
- 이제 인자 없이 tomotopy.CTModel.get_correlations`를 호출하면 `[k, k] 모양의 상관관계 행렬을 반환합니다.
- 0.8.0 (2020-06-06)
- NumPy가 tomotopy에 도입됨에 따라 많은 메소드와 프로퍼티들이 `list`가 아니라 `numpy.ndarray`를 반환하도록 변경되었습니다.
- Tomotopy에 새 의존관계 `NumPy >= 1.10.0`가 추가되었습니다..
- `tomotopy.HDPModel.infer`가 잘못된 추론을 하던 문제가 수정되었습니다.
- HDP 모델을 LDA 모델로 변환하는 메소드가 추가되었습니다.
- tomotopy.LDAModel.used_vocabs, tomotopy.LDAModel.used_vocab_freq, tomotopy.LDAModel.used_vocab_df 등의 새로운 프로퍼티가 모델에 추가되었습니다.
- 새로운 토픽 모델인 g-DMR(tomotopy.GDMRModel)가 추가되었습니다.
- macOS에서 `tomotopy.label.FoRelevance`를 생성할 때 발생하던 문제가 해결되었습니다.
- `tomotopy.utils.Corpus.add_doc`로 `raw`가 없는 문헌을 생성한 뒤 토픽 모델에 입력할 시 발생하는 오류를 수정했습니다.
- 0.6.1 (2020-03-22) (삭제됨)
- 모듈 로딩과 관련된 버그가 수정되었습니다.
- 0.5.2 (2020-03-01)
- tomotopy.LLDAModel.add_doc 실행시 segmentation fault가 발생하는 문제를 해결했습니다.
- tomotopy.HDPModel`에서 `infer 실행시 종종 프로그램이 종료되는 문제를 해결했습니다.
- `tomotopy.LDAModel.infer`에서 ps=tomotopy.ParallelScheme.PARTITION, together=True로 실행시 발생하는 오류를 해결했습니다.
- 0.5.0 (2019-12-30)
- `tomotopy.PAModel.infer`가 topic distribution과 sub-topic distribution을 동시에 반환합니다.
- `tomotopy.Document`에 get_sub_topics, get_sub_topic_dist 메소드가 추가되었습니다. (PAModel 전용)
- tomotopy.LDAModel.train 및 tomotopy.LDAModel.infer 메소드에 parallel 옵션이 추가되었습니다. 이를 통해 학습 및 추론시 사용할 병렬화 알고리즘을 선택할 수 있습니다.
- tomotopy.ParallelScheme.PARTITION 알고리즘이 추가되었습니다. 이 알고리즘은 작업자 수가 많거나 토픽의 개수나 어휘 크기가 클 때도 효율적으로 작동합니다.
- 모델 생성시 min_cf < 2일때 rm_top 옵션이 적용되지 않는 문제를 수정하였습니다.
- 0.4.2 (2019-11-30)
- tomotopy.LLDAModel`와 `tomotopy.PLDAModel 모델에서 토픽 할당이 잘못 일어나던 문제를 해결했습니다.
- tomotopy.Document 및 tomotopy.Dictionary 클래스에 가독성이 좋은 __repr__가 추가되었습니다.
- 0.4.1 (2019-11-27)
- tomotopy.PLDAModel 생성자의 버그를 수정했습니다.
- 0.4.0 (2019-11-18)
- tomotopy.PLDAModel`와 `tomotopy.HLDAModel 토픽 모델이 새로 추가되었습니다.
- 0.1.6 (2019-08-09)
- macOS와 clang에서 제대로 컴파일되지 않는 문제를 해결했습니다.
- 0.1.4 (2019-08-05)
- add_doc 메소드가 빈 리스트를 받았을 때 발생하는 문제를 해결하였습니다.
- `tomotopy.PAModel.get_topic_words`가 하위토픽의 단어 분포를 제대로 반환하지 못하는 문제를 해결하였습니다.
- 0.1.3 (2019-05-19)
- min_cf 파라미터와 불용어 제거 기능이 모든 토픽 모델에 추가되었습니다.
- 0.1.0 (2019-05-12)
- **tomotopy**의 최초 버전
- Eigen: This application uses the MPL2-licensed features of Eigen, a C++ template library for linear algebra. A copy of the MPL2 license is available at https://www.mozilla.org/en-US/MPL/2.0/. The source code of the Eigen library can be obtained at http://eigen.tuxfamily.org/.
- EigenRand: MIT License
- Mapbox Variant: BSD License