Architectural Overview
- A server component built to address the need for high scale data workloads
- That is workloads which could exceed the storage account limits (20,000 IOPS & 500 TB limit, 20 Gbps throughput).
- Implements a scale out storage of blobs across multiple storage accounts by implementing the Azure Blob Storage REST API
- In short, it enables you to shard storage across multiple storage accounts without having to build the sharding logic
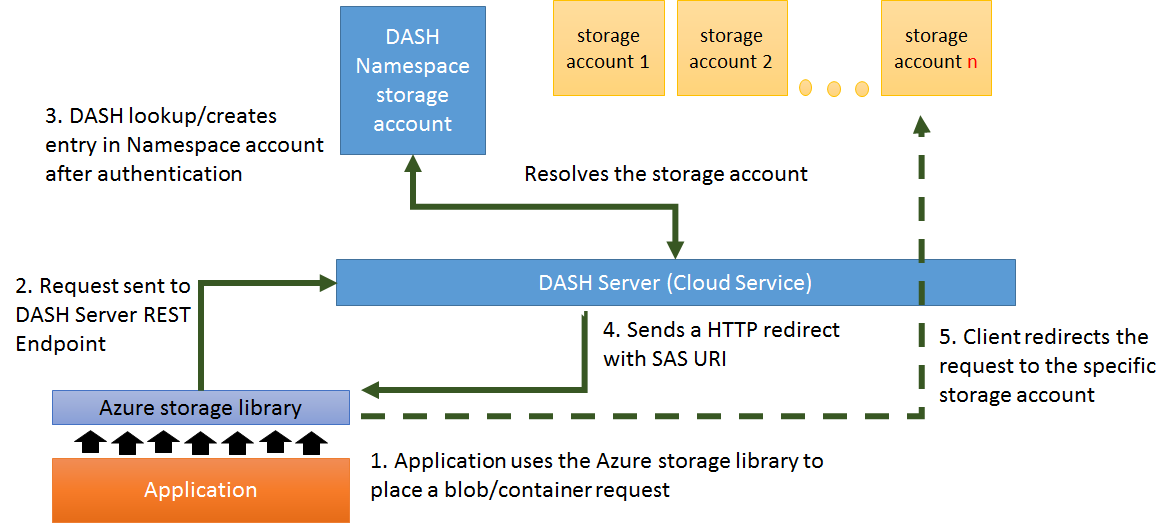
- The Dash endpoint fully implements the Azure Storage REST API and so all existing storage libraries can connect to Dash. The only modification is to explicitly set the BlobEndpoint DNS name to point to the Dash service's URL.
- The REST request is sent via HTTP/HTTPS as per a normal storage request.
- The Dash server parses the request. For operations with a subject blob, the blob is looked up or created in the 'Namespace' account. The Namespace account is a dedicated storage account that contains zero-length blobs for every blob in the virtual account. Each namespace blob contains metadata specifying the location of the real data blob.
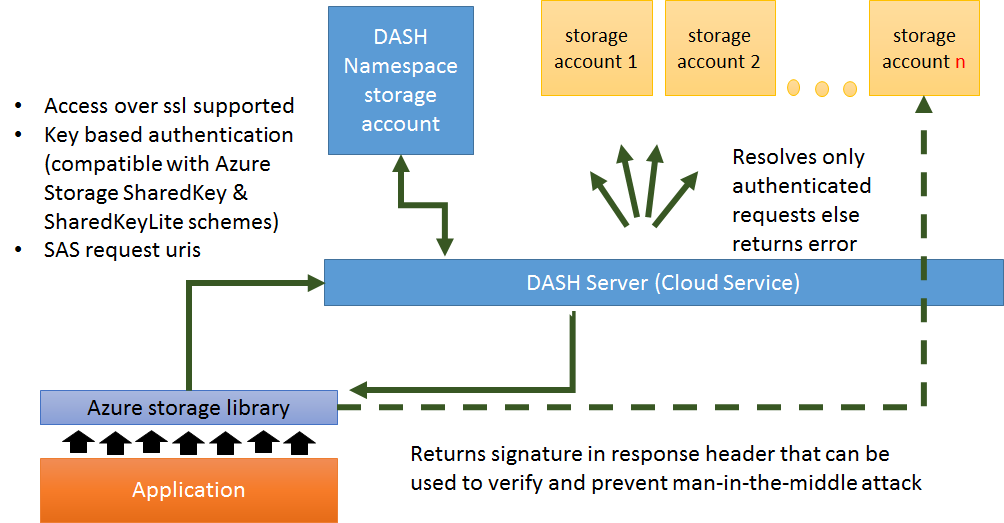
- Once the namespace blob identifies the account containing the data blob, a Shared Access Signature (SAS) URI is generated for the data blob. This URI is sent as the
Locationheader as a302 - Object Moved Temporarilyredirection response. Using redirections is this manner results in the Dash server not needing to process any of the data payload. - The client follows normal HTTP/REST practice of automatically following the redirection to the real data blob. Because the redirection URI is a SAS the client does not need the credentials to the data account.
Note for operations that create a new blob step 3 involves the selection of a data account to locate the data blob and the creation of a namespace entry with that information. Data account selection is based on a name hashing scheme which yields uniform distribution.
Requests that are not associated with individual blobs (ie. Account or Container operations) are 'proxied' by Dash to ALL data accounts + the namespace account. This ensures that the entire set of accounts remain consistent.
Certain client libraries are unable or unwilling to automatically follow redirections (including the removal of the Authorization request header when redirecting to a different host). In those cases, Dash will act as a full proxy and forward the requests directly to the appropriate data account(s). While this 'proxy mode' is not as efficient as 'redirection mode' (ie. the Dash server must process the full data payload), it does mean that a Dash virtual account can interoperate with ALL clients.

- Very high throughput
- (read & write) Exceed 20/30 Gbps limitation across large number of blobs (eg. MapReduce)
- (read) Concentrated read throughput (> 60 MBps per blob) on small number of blobs (eg. HPC)
- Very large storage volume
- Storage volume exceeding 500 TB
- Very high request rate
- Workloads requiring > 20,000 IOPS (eg. K/V stores – HBase, Spark)
- (WIP) Very large single blobs
- Single blobs greater than 200 GB in size or 50,000 blocks (eg. Media files, Genomics …)