
A deep learning (LSTM) sentiment analysis project to determine positive/negative sentiment in Arabic social media content. This project makes use of Arabic word embeddings (https://github.com/iamaziz/ar-embeddings) [1] and a dataset of 2000 Twitter posts (https://archive.ics.uci.edu/ml/datasets/Twitter+Data+set+for+Arabic+Sentiment+Analysis) [2].
-1. A. Altowayan and L. Tao "Word Embeddings for Arabic Sentiment Analysis", IEEE BigData 2016 Workshop -1. Abdulla N. A., Mahyoub N. A., Shehab M., Al-Ayyoub M.,Arabic Sentiment Analysis: Corpus-based and Lexicon-based,IEEE conference on Applied Electrical Engineering and Computing Technologies (AEECT 2013),December 3-12, 2013, Amman, Jordan. (Accepted for Publication)
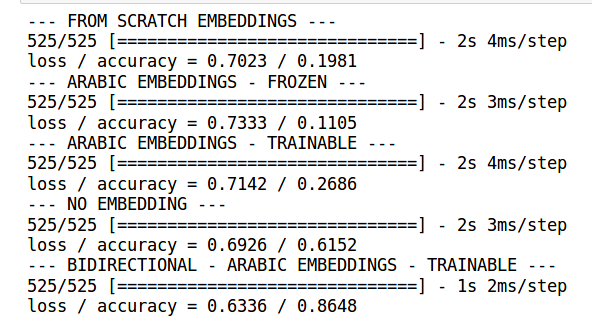
- Sentiment Analysis for Arabic Text (tweets, reviews, and standard Arabic) using word2vec
- https://github.com/iamaziz/ar-embeddings
- A. Altowayan and L. Tao "Word Embeddings for Arabic Sentiment Analysis", IEEE BigData 2016 Workshop
- Twitter Data set for Arabic Sentiment Analysis Data Set
- https://archive.ics.uci.edu/ml/datasets/Twitter+Data+set+for+Arabic+Sentiment+Analysis
- Abdulla N. A., Mahyoub N. A., Shehab M., Al-Ayyoub M.,Arabic Sentiment Analysis: Corpus-based and Lexicon-based,IEEE conference on Applied Electrical Engineering and Computing Technologies (AEECT 2013),December 3-12, 2013, Amman, Jordan. (Accepted for Publication).
- arabic-stop-words; 750 words in a text file
