A scalable and efficient data platform that processes and stores streaming data (e-commerce customer transactions).
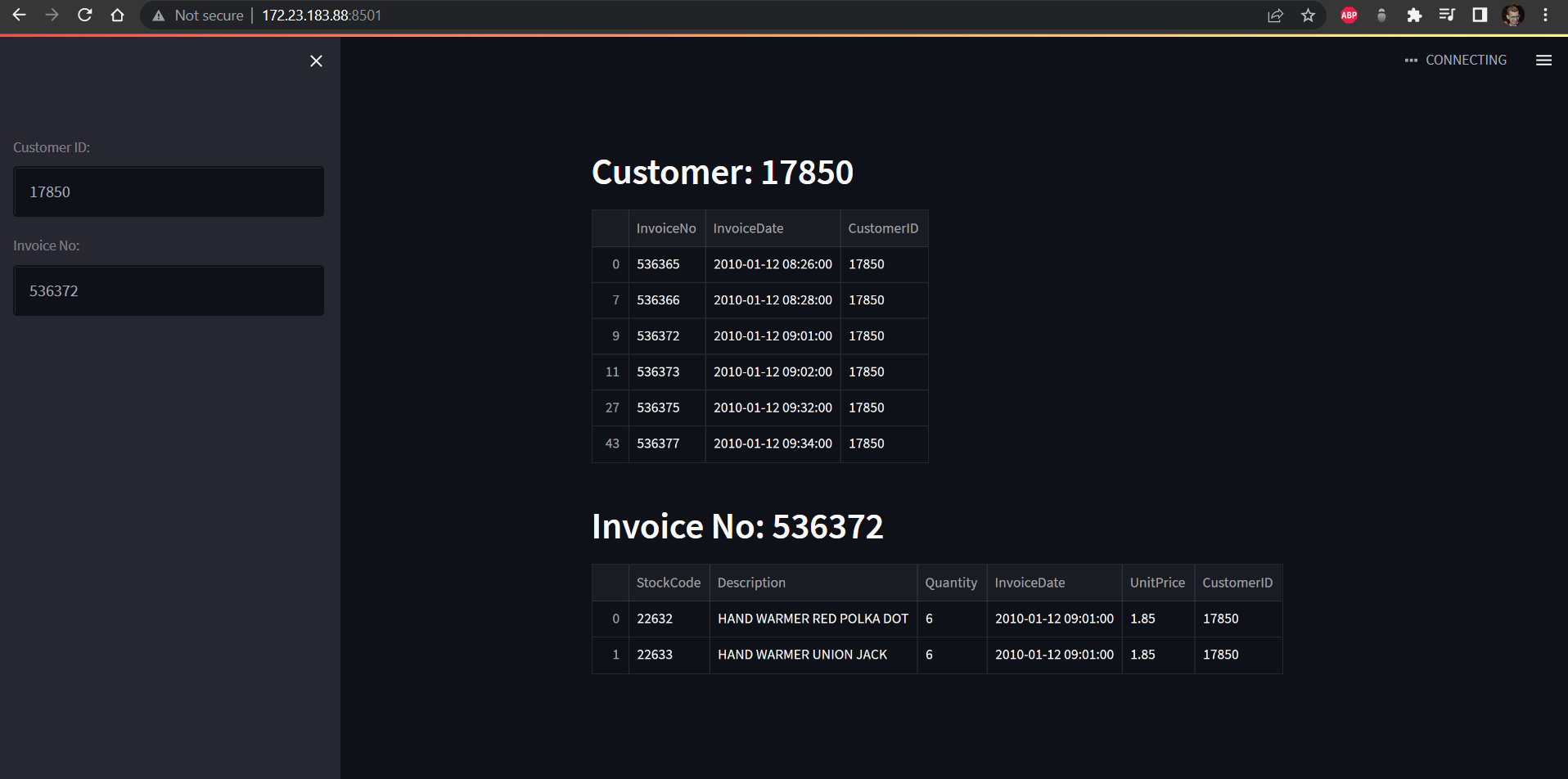
The main objective of the data platform is to enable customer service officers to query real-time transactional data to easily handle customer tickets and issues.
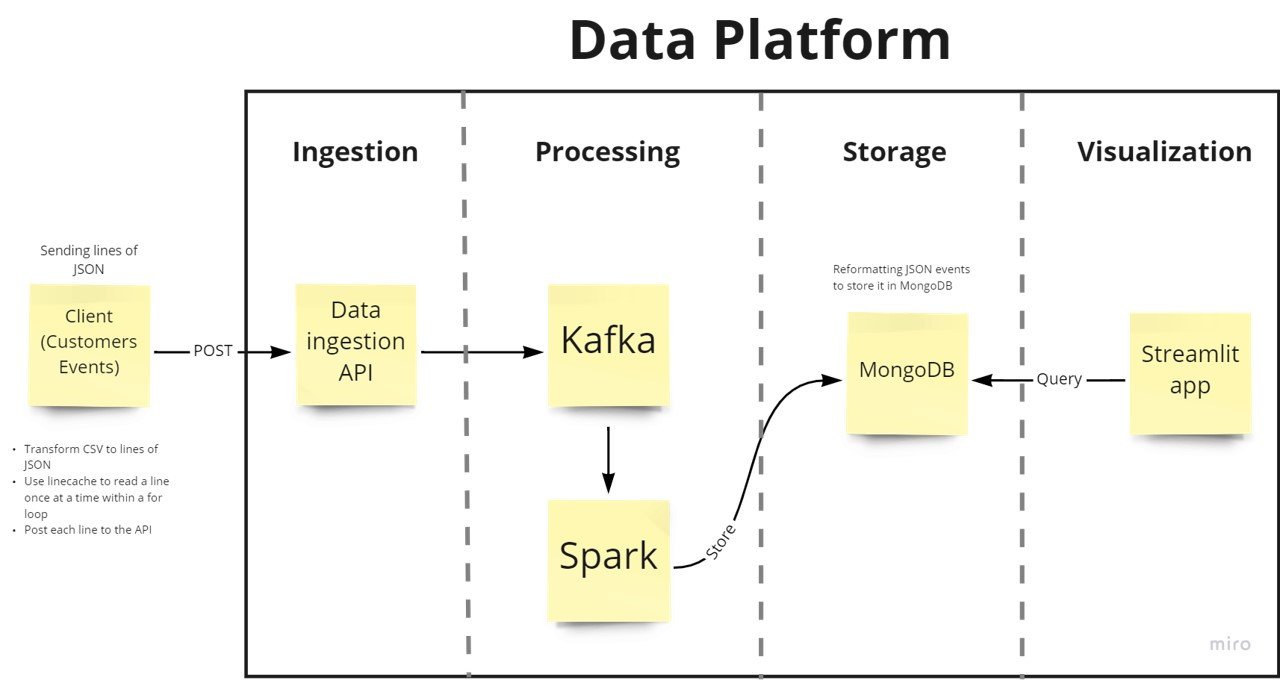
To ensure that customer service officers have access to real-time transactional data without any bottlenecks occuring resulting in delayed data and inaccuracte queries, Apache Kafka and PySpark were used for distributed processing and allowing for potential horizontal scaling as velocity increases.
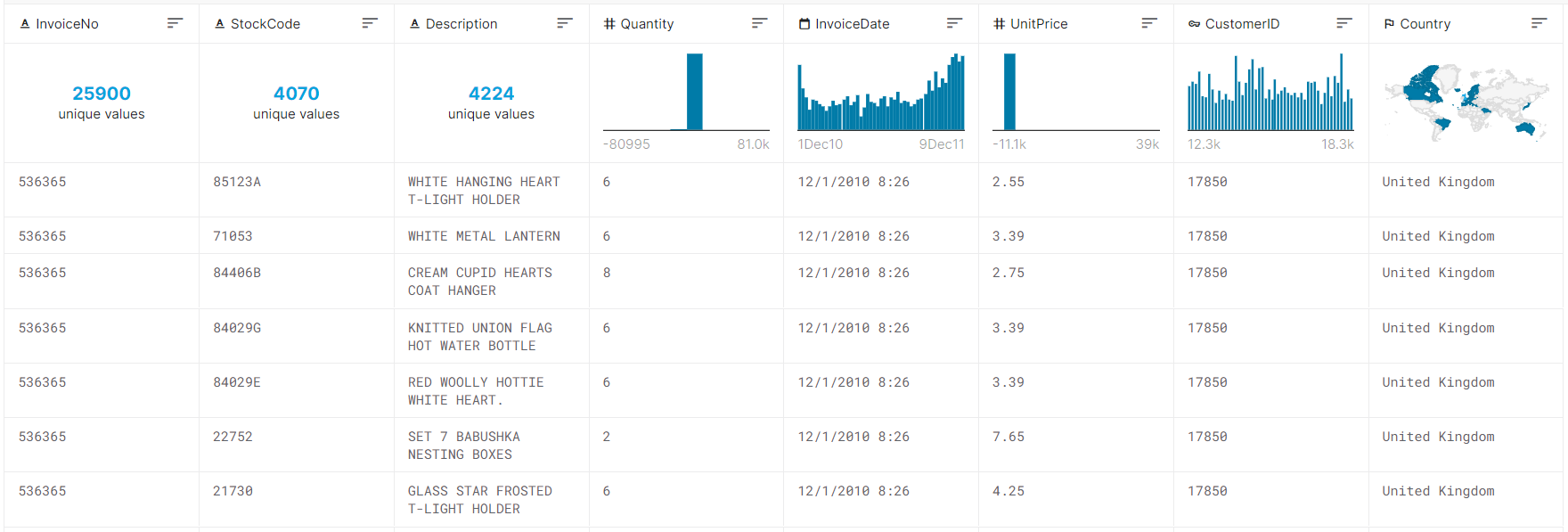
E-commerce dataset was used from kaggle link. The data is actual transactions from UK retailer
- FastAPI was used to build the API Gateway for the data platform and produce data to Apache Kafka
- Apache Kafka was used to decouple the API Gateway and processing framework (PySpark) and allow for horizontal scalability if data velocity increases
- PySpark was used for streaming data processing, the main goal is to reformat the data recieved by the client by removing critical attributes that are unnecessary for the end-user (customer service officer) and storing the data in mongodb.
- MongoDB was used for storing transaction data
- Streamlit was used as a user interface for the customer service officer
- client.py is a script that POST's transactional data to the data platform's API Gateway docker container
## client.py script
import linecache
import requests
import json
i = 1
end = 100
ENDPOINT = 'http://localhost:80'
while i <= end:
line = linecache.getline('data/json-lines.txt', i)
data_line = json.loads(line)
print(data_line)
response = requests.post(f'{ENDPOINT}/invoices', data = line)
i += 1
print(response)- API Gateway was built using FastAPI and containerized using Docker to allow for deployment, it allows a POST request to /invoices this enables
client.pyto send data. - Error Logging was automated using logging package and logs get stored in
api/api-ingestion.log
# API-Gateway script
from fastapi import FastAPI
from pydantic import BaseModel
from fastapi.responses import JSONResponse
from fastapi.encoders import jsonable_encoder
from kafka import KafkaProducer
from datetime import datetime
import json
import logging
'''
API Gateway and Kafka Producer module
Objective 1: Collect customer transactions
Objective 2: Produce customer transactions to Kafka
'''
# For logging
logging.basicConfig(
filename = "api-ingestion.log",
level = logging.DEBUG,
format = "%(asctime)s - %(levelname)s - %(message)s"
)
KAFKA_PRODUCER = KafkaProducer(bootstrap_servers = 'kafka:9092')
def produce_to_kafka(producer, topic, json_event):
"""function that produces events to kafka topic
Args:
producer (KafkaProducer): producer object
topic (str): name of the topic
json_event (json): json event recieved by the API gateway
"""
def success(metadata):
print(metadata.topic)
def error(exception):
print(exception)
# kafka reads objects of the type "byte"
bytes_event = bytes(json_event, 'utf-8')
producer.send(topic, bytes_event).add_callback(success).add_errback(error)
producer.flush()
class InvoiceItem(BaseModel):
'''
API messages JSON Schema
'''
InvoiceNo: str
StockCode: str
Description: str
Quantity: int
InvoiceDate: str
UnitPrice: float
CustomerID: int
Country: str
app = FastAPI()
@app.get('/')
async def root():
return {'Hello World'}
@app.post('/invoices')
async def post_invoice(item: InvoiceItem):
try:
# date format modification to meet ANSI standard
old_date = datetime.strptime(item.InvoiceDate, "%d/%m/%Y %H:%M")
item.InvoiceDate = datetime.strftime(old_date, "%Y-%m-%d %H:%M:%S")
# json_item -> to be returned as a API response
# str_item -> to be produced to Kafka
json_item = jsonable_encoder(item)
str_item = json.dumps(json_item)
produce_to_kafka(KAFKA_PRODUCER, 'customer-event-api', str_item)
logging.info(f"{str_item} event successfully produced")
return JSONResponse(json_item, status_code=201)
except Exception as err:
logging.error(f"{err.__class__}\t{err}")- PySpark jupyter notebook was used for consuming Kafka events and processing it.
from pyspark.sql import SparkSession
# for the transformation of json strings to datafarmes
from pyspark.sql.types import MapType, StringType
from pyspark.sql.functions import from_json
spark = (SparkSession
.builder
.master('local')
.appName('kafka-mongo-streaming')
.config("spark.jars.packages", "org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.5,org.mongodb.spark:mongo-spark-connector_2.11:2.4.0")
.config("spark.mongodb.input.uri","mongodb://root:example@mongo:27017/customer-events.invoice-items?authSource=admin")
.config("spark.mongodb.output.uri","mongodb://root:example@mongo:27017/customer-events.invoice-items?authSource=admin")
.getOrCreate())
# listening to kafka events
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "kafka:9092") \
.option("subscribe", "customer-event-api") \
.load()
df1 = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")- Currently MongoDB does not allow PySpark to stream data to it, so foreach_batch_function was used to transform each batch of data and finally store it in MongoDB
def foreach_batch_function(df, epoch_id):
df2 = df.withColumn("value", from_json(df.value,MapType(StringType(),StringType())))
df3 = df2.select(["value.InvoiceNo", "value.StockCode", "value.Description", "value.Quantity", "value.InvoiceDate", "value.UnitPrice", "value.CustomerID", "value.Country"])
df3.write.format("com.mongodb.spark.sql.DefaultSource").mode("append").save()
df1.writeStream.foreachBatch(foreach_batch_function).start().awaitTermination()The project turned out successful, a docker-compose file was created to containerize all components in the data-platform and allow for deployment in the cloud or kubernetes.
- Logging and debugging errors using the logging python package
- Configuring Apache Kafka
- Configuring Docker containers network to allow for communication between the docker containers
- Using PySpark as a Kafka consumer and for storing data in MongoDB