Determine SNAP relationship output in taxonomy TEI and its associated column names #35
Comments
|
@wlpotter I think this issue is coming together with srophe issue #930. I think what we want for this is for column K to be a skos:closeMatch or skos:exactMatch on a That said, let me know what you think of this. I think all we want to assert for the crosswalk to LOC, for example, is a skos:closeMatch. In the case of SNAP we mostly want to assert skos:closeMatch [or maybe skos:exactMatch, I probably need to do a bit more work on this]. In the cases discussed in srophe issue #930, we would want to assert skos:broadMatch. What is your preference on the transform side of things:
Let's discuss this. Thanks Will. |
|
@dlschwartz We can discuss this, but my first instinct is to say we should have a separate column for each relation 'type'. I could also see an argument for keeping the columns as they are and just renaming. The main benefit is we wouldn't have to do any reorganizing. So, starting in column H you'd have (for LOC, DNB, ISO Lang Code, SNAP) The types of relations might change depending on what we decide they should be. You could keep a second row or a comment on these columns to remind encoders which URIs to put in which columns. The only other change here would be to start the enumeration of columns AF-AK at relation5. (These relations may also change type based on decisions in srophe issue #930) |
|
Ah, sorry, I missed the point about needing both skos:closeMatch and skos:broadMatch for SNAP relations. I think we should have a column for each. So instead of just |
|
@wlpotter I think this sounds good but let's chat about it. Thanks. |
|
@wlpotter I've had a chance to read up a bit more and now I'm following the W3C definitions and what you've written here a bit better. To summarize:
I don't think we should use skos:narrower because I think it is easier to list the "parent/s" of the concepts in each record rather than to list all of the "children" concepts in the parent record. Moreover, these are transitive: https://www.w3.org/TR/skos-primer/#secrel according to the SKOS model. Encoding them in a tei:relation with Unfortunately, the nesting into something resembling a tree is not automatic, see https://www.w3.org/TR/skos-primer/#sectransitivebroader. Notice there that a "grandparent/grandchild" relationship can be inferred as a skos:broaderTransitive. In an RDF environment I think this should mean that we can query for things like all the descendants of a concept or all the children of a parent concept. As we work on developing the ontology, we might need to tweak this. At the moment though, I think this is where we should start. Any thoughts? If we go with this approach, I believe that we would do the following in the spreadsheet:
Btw, a lot of this comes out of srophe/syriaca-data#930 but I think the discussion belongs here. |
|
@wlpotter I suppose this is the right place to deal with |
|
@dlschwartz This all sounds good. I think using skos:broader and sticking to it makes sense as it and skos:narrower are inverses. The lack of transitivity does pose some problems. We could use skos:broaderTransitive, and I think that means we would double up relations: This would allow the broader link between A and C. For the spreadsheet, we could implement some way to flag if we want to include a skos:broaderTransitive relation -- maybe a Maybe an alternative would be to explicitly declare skos:broader for each level of relationship, though depending on the depth of the tree this could be even more tedious. I think the column changes sound good. I will make the adjustments to how the script outputs the relation elements. For |
|
@dlschwartz changing the encoding of SNAP from Also, as we now have closeMatch and broadMatch, we may need two columns for this designation as "directed" or "mutual" |
|
@wlpotter actually, I'm not sure we need this at all. I think it's enough that we have a relationship between our concept and the SNAP concept. But maybe we should discuss this further. From the perspective of a triple store and of an API sharing data with SNAP, maybe it's best to clearly mark when our concept relates to a SNAP concept. Let's discuss this when we meet this afternoon. |
|
@dlschwartz sounds good, let's discuss just this issue to make sure we're on the same page. I believe it may be related to #37 as you mentioned in this comment that
|
|
@wlpotter alright, I'm seeing now that I've got myself in a bind between "browse by" categories and the structured hierarchy of an ontology. I need to re-think some things. It might be easiest just to discuss this afternoon in our meeting. |
|
It might be as simple as putting "browse by" categories as a |
|
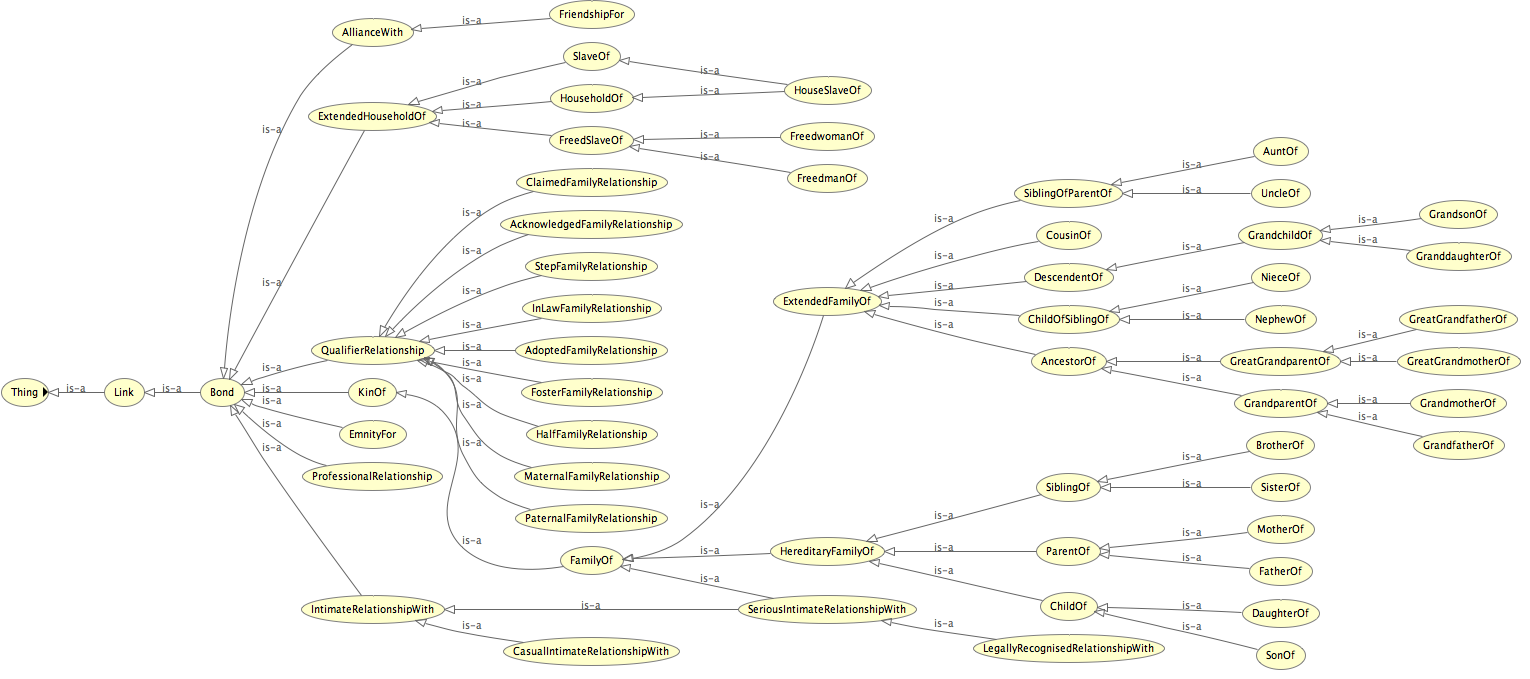
@wlpotter I've been working on the taxonomy relationships. I've grouped them in rows 1049-1132 in the spreadsheet. Columns K and L should not contain an accurate crosswalk with SNAP. Column K is used only for skos:closeMatch and column L contains skos:broadMatch when there is no skos:closeMatch, i.e. it indicates the narrowest concept in SNAP under which our concept falls. This should allow us to share data with SNAP even when we have relationships they don't have. Columns AG and AH contain one or more parent concepts for each relationship. They should accurately reflect this SNAP graph minus concepts for which we haven't created a keyword and with our concept keywords added in. I have a question about the difference between "Link" and "Bond" which leaves me less than clear about where to put things like relationships between events or between persons and objects. I think these are a "Link" while relationships between persons are a "Bond" but I'm not sure about that. Let's not close this issue until I figure that out. |
{kind=link}
|
Correction: Columns K and L should NOW contain an accurate crosswalk with SNAP. |
|
@dlschwartz these look great! I will have the script output them as follows: or This raises one question: the (Note that we run into a similar issue with |
|
@wlpotter, thanks for the question. I think there are two separate issues here.
Does this all make sense? |
|
@dlschwartz yes, I think you're right that the two issues are separate, and I was mostly thinking about the second, LOD issue even though I was perhaps putting it in terms of namespaces. My concern with only declaring the human-readable is that without some external reference table, these attribute values aren't really machine readable (or at the very least wouldn't be useful as machine-actionable data). Perhaps that's not probable enough to warrant concern though? From a technical standpoint it would be simple to implement the conversion from snap:x to full URI at the transform level using a simple replace function. |
|
@wlpotter Let's talk through what makes most sense tomorrow. Thanks. |
|
We will leave the "snap:" in the Change "skos:concept" to the full URI (maybe open separate issue?) |
|
For column G, add to TEI like this: FYI, #42 is the issue for changing skos:Concept to the full URI |
|
I have updated the tei:relation generation to match the comment above. I have also added the note for relationship types to the transform. I will run a new test output to double check, but then I believe this issue can be closed. |
|
@dlschwartz when you get a chance, could you take a look at the files from this commit, especially the ones that are relationships with snap close/broad matches? They should be ready to go except for the schemas (on which see #44). The files are also here |
@dlschwartz Could you let me know how you want the SNAP relationships to appear in the TEI along with their crosswalk to Syriaca URIs?
Here is what you said about these columns in #6, for reference:
The text was updated successfully, but these errors were encountered: