本库目前实现以下内容:
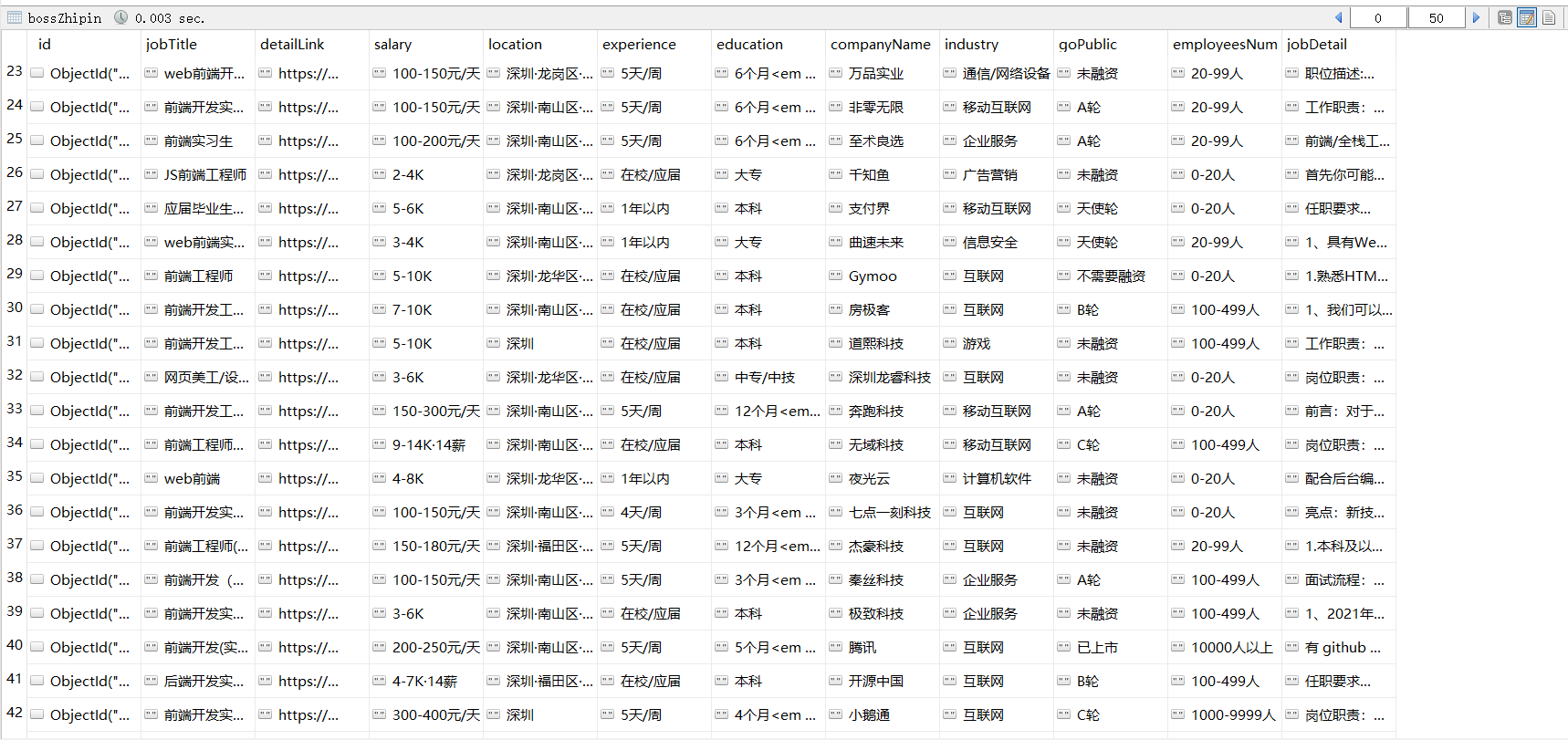
- 使用selenium对Boss直聘进行爬虫,将工作信息(岗位头衔、薪资、地点、经验要求、学历要求、公司名称、所属行业、融资情况、人员规模、岗位详情)使用MongoDB存储到本地数据库中
- 筛选符合要求的工作,保存对应的岗位要求
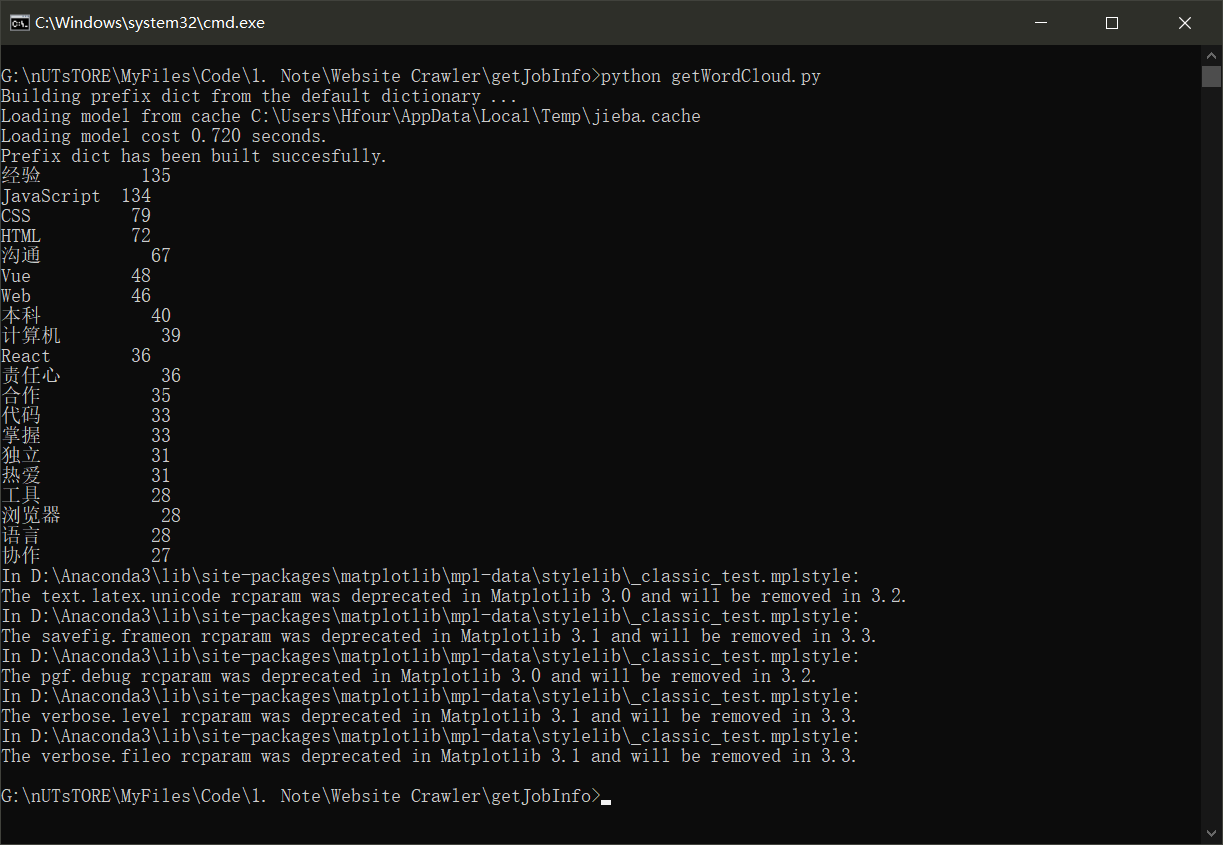
- 对所有岗位要求分词,并生成词云
2019年底在GitHub没找到未过期的Boss直聘爬虫,写了这个。
2021年初运行代码已过期,修改了部分代码,截止2021-03-01可用。
- 安装python或Anaconda3镜像(推荐阅读:Anaconda下载换源)
- 安装MongoDB
- 安装Robo3T
- 安装python库requests、pymongo、selenium、pyquery、imageio、pymongo、jieba、wordcloud
- 安装Chrome
- 安装与Chrome版本号一致的ChromeDriver镜像,放到chrome.exe文件目录下
eg.
python:
pip install requests
Anaconda3:
conda install requests
conda install -c conda-forge jieba
conda install -c conda-forge wordcloud
可执行文件
BossZhipin/main.py:爬取工作基本信息存储到数据库BossZhipin/getJobDetails.py:爬取工作详情页信息存储到数据库BossZhipin/getJobRequests.py:筛选符合要求的工作,汇总岗位信息保存到Output/jobRequests.txtBossZhipin/getWordCloud.py:读取岗位信息,生成词云,并根据词频输出关键词
其他文件
BossZhipin/config.py:配置文件Output/chinamap.jpg:词云的形状Output/jobRequests.txt:汇总的岗位信息,可根据需要修改内容Output/jobRequests.png:生成的词云
MONGO_URL、MONGO_DB、MONGO_TABLE:本地数据库配置url:Boss直聘首页链接keyWord:搜索岗位关键词excludes:统计词频时的排除单词num:输出词频排名前几位
- 注册Boss直聘,在Chrome上登录并记住账号
- 当运行
main.py在首页不断刷新,关闭爬虫,重新打开Chrome,进入Boss直聘首页,通过安全验证,再关闭Chrome执行代码

MIT © Buccal