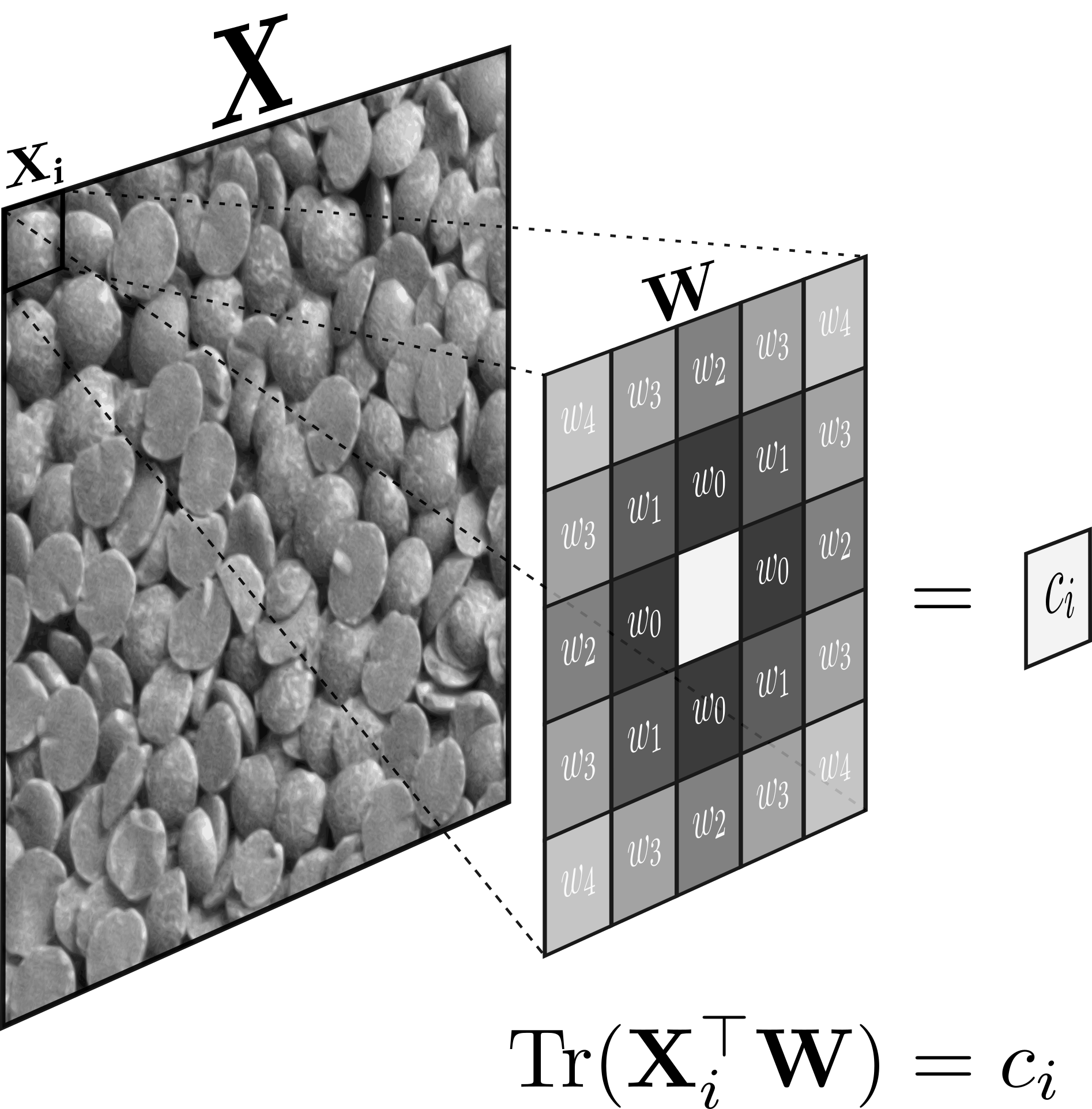
The weights of a convolution kernel are optimized to best predict the center pixel of each window,
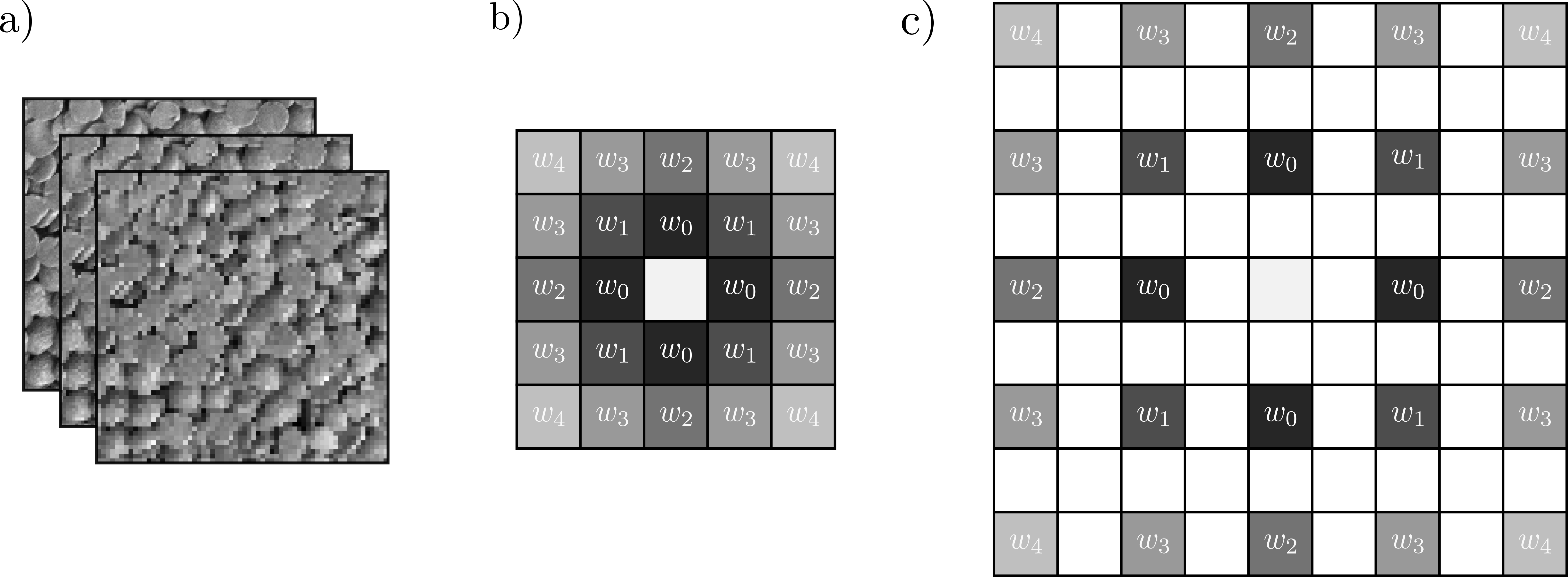
Multiple convolution kernels are learned to account for various spatial scales in image. This is performed by decimating the image by various factors using the same kernel size, resulting in the kernel expanding by the decimation factor. The above image demonstrates this. Decimating the image by a factor of two results in the kernel expanding as shown in c.
Kylberg textures. Examples of each class:

.
.
The top row is for the model here. The additional rows (CNNs with millions of parameters) were described in Andrearczyk & Whelan, 2016.
| Kylberg | CUReT | DTD | kth-tips-2b | ImNet-T | ImNet-S1 | ImNet-S2 | ImageNet | |
|---|---|---|---|---|---|---|---|---|
| ConvAR | 99.6 | 93.06 | 60.36 | |||||
| T-CNN-1 (20.8) | 89.5 ± 1.0 | 97.0 ± 1.0 | 20.6 ± 1.4 | 45.7 ± 1.2 | 42.7 | 34.9 | 42.1 | 13.2 |
| T-CNN-2 (22.1) | 99.2 ± 0.3 | 98.2 ± 0.6 | 24.6 ± 1.0 | 47.3 ± 2.0 | 62.9 | 59.6 | 70.2 | 39.7 |
| T-CNN-3 (23.4) | 99.2 ± 0.2 | 98.1 ± 1.0 | 27.8 ± 1.2 | 48.7 ± 1.3 | 71.1 | 69.4 | 78.6 | 51.2 |
| T-CNN-4 (24.7) | 98.8 ± 0.2 | 97.8 ± 0.9 | 25.4 ± 1.3 | 47.2 ± 1.4 | 71.1 | 69.4 | 76.9 | 28.6 |
| T-CNN-5 (25.1) | 98.1 ± 0.4 | 97.1 ± 1.2 | 19.1 ± 1.8 | 45.9 ± 1.5 | 65.8 | 54.7 | 72.1 | 24.6 |
| AlexNet (60.9) | 98.9 ± 0.3 | 98.7 ± 0.6 | 22.7 ± 1.3 | 47.6 ± 1.4 | 66.3 | 65.7 | 73.1 | 57.1 |
Mao, J., & Jain, A. K. (1992). Texture classification and segmentation using multiresolution simultaneous autoregressive models. Pattern recognition, 25(2), 173-188.
Kylberg, G. (2011). Kylberg texture dataset v. 1.0. Centre for Image Analysis, Swedish University of Agricultural Sciences and Uppsala University.
Andrearczyk, V., & Whelan, P. F. (2016). Using filter banks in Convolutional Neural Networks for texture classification. Pattern Recognition Letters, 84, 63–69. https://doi.org/10.1016/j.patrec.2016.08.016