![]()
State-of-the-art, lightweight NLP tools for Turkish language.
Developed by VNGRS.
![]()
-
Sentence Splitter
-
Normalizer
- Spelling/Typo correction
- Convert numbers to word form
- Deasciification
-
Stopword Remover:
- Static
- Dynamic
-
Stemmer: Morphological Analyzer & Disambiguator
-
Named Entity Recognizer (NER)
-
Dependency Parser
-
Part of Speech (PoS) Tagger
-
Sentiment Analyzer
-
Turkish Word Embeddings
- FastText
- Word2Vec
- SentencePiece Unigram Tokenizer
-
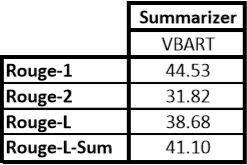
News Summarization
-
News Paraphrasing
-
Summarization and Paraphrasing models are available in the demo. Contact us at [email protected] for API.
- Try the Demo.
pip install vngrs-nlp
- See the Documentation for the details about usage, classes, functions, datasets and evaluation metrics.

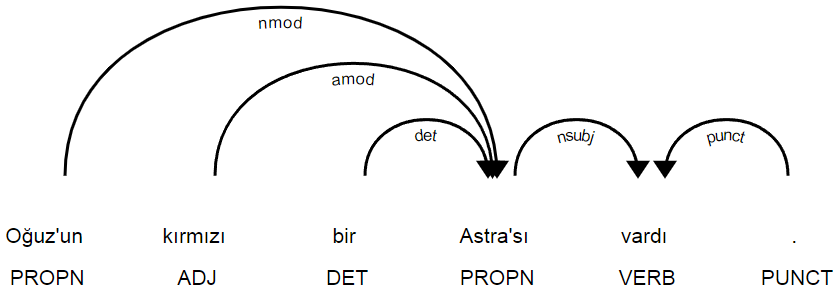
Dependency Parser
from vnlp import DependencyParser
dep_parser = DependencyParser()
dep_parser.predict("Oğuz'un kırmızı bir Astra'sı vardı.")
[("Oğuz'un", 'PROPN'),
('kırmızı', 'ADJ'),
('bir', 'DET'),
("Astra'sı", 'PROPN'),
('vardı', 'VERB'),
('.', 'PUNCT')]
# Spacy's submodule Displacy can be used to visualize DependencyParser result.
import spacy
from vnlp import DependencyParser
dependency_parser = DependencyParser()
result = dependency_parser.predict("Oğuz'un kırmızı bir Astra'sı vardı.", displacy_format = True)
spacy.displacy.render(result, style="dep", manual = True)
@article{turker2024vnlp,
title={VNLP: Turkish NLP Package},
author={Turker, Meliksah and Ari, Erdi and Han, Aydin},
journal={arXiv preprint arXiv:2403.01309},
year={2024}
}