Parallel benchmarks
@section Parallel Parallel Frameworks Benchmarks
Lib_VTK_IO can handle multiple concurrent files and it is \b thread/processor-safe, meaning that it can be safely used into parallel architectures using OpenMP and/or MPI paradigms. In order to assess its scalability two procedures have been implemented into Test_Driver program:
-
test_mpi; -
test_openmp.
To use these two procedures two bash scripts are provided within Lib_VTK_IO.
The Test_Driver program contains a procedure, test_mpi, for assessing the scalability of Lib_VTK_IO into MPI parallel framework. The bash script mpi_benchmark.sh can be used to repeat the benchmark many times varying the number of MPI processes in order to asses the speedup of the library (the Test_Driver program must be compiled with MPI=yes option):
./mpi_benchmark.sh -ni 10 -nf 32 -np 32This will test the saving of a PStructuredGrid file partitioned into (-nf) 32 blocks/files, varying the number of MPI processes from 1 to 32 with a step of 2 and each benchmark is repeated 10 times and the averaged results are saved. The results are echoed to stdout and also into mpi_speedup.dat file, where also the normalized (with respect the serial performance) results are saved. The figure below reports the normalized elapsed time as the number of MPI processes varies. Both x and y are log scaled in order to emphasizes the linearity of the speedup up to 12 MPI processes.
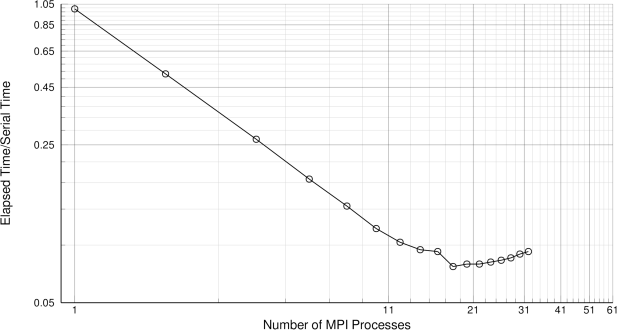
The library scales linearly as expected. As a matter of facts, each MPI process saves its own file(s) thus the speedup is maximum. The linearity is lost when then number of MPI processes becomes higher than 12 being the number of cores available for this benchmark (12 Cores Intel(R) Xeon(R) CPU X5650 @ 2.67GHz). The compiling options are not relevant, these results have been obtained in DEBUG mode with OpenMPI 1.6 + Intel Fortran 13.0.0.
This result is interesting for all the applications where "1 file for 1 MPI process" is reasonable because it optimizes the IO performance. Obviously, for high number of MPI processes (order of thousands) this is not a good strategy (it produces thousands of files) whereas a MPI2 IO strategy should be preferable.
The Test_Driver program contains a procedure, test_openmp, for assessing the scalability of Lib_VTK_IO into OpenMP parallel framework. The bash script openmp_benchmark.sh can be used to repeat the benchmark many with varying the number of OpenMP threads in order to asses the speedup of the library (the Test_Driver program must be compiled with OPENMP=yes option):
./mpi_benchmark.sh -ni 10 -nf 32 -nt 32This will test the saving of a PStructuredGrid file partitioned into (-nf) 32 blocks/files, varying the number of OpenMP threads from 1 to 32 with a step of 2 and each benchmark is repeated 10 times and the averaged results are saved. The results are echoed to stdout and also into openmp_speedup.dat file, where also the normalized (with respect the serial performance) results are saved. The figure below reports the normalized elapsed time as the number of OpenMP threads varies. Both x and y are log scaled in order to emphasizes the linearity of the speedup up to 12 OpenMP threads.
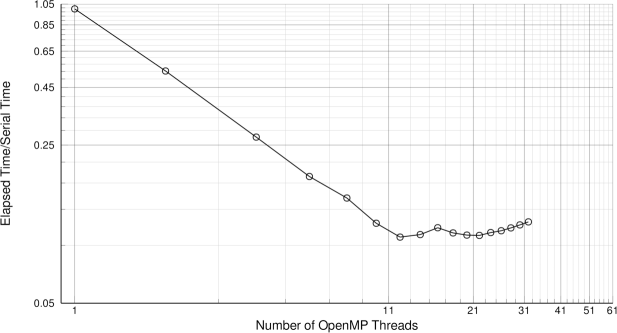
The library scales linearly as expected. As a matter of facts, each OpenMP threads saves its own file(s) thus the speedup is maximum. The linearity is lost when then number of OpenMP threads becomes higher than 12 being the number of cores available for this benchmark (12 Cores Intel(R) Xeon(R) CPU X5650 @ 2.67GHz). The compiling options are not relevant, these results have been obtained in DEBUG mode with Intel Fortran 13.0.0.