{kind=link}
{kind=link}
{kind=link}
These are some short ML projects that I coded up from scratch as part of the CS4771 course at Columbia.
I trained two classifiers to classify spam emails. The first classifier is a naive Bayes classifier, which was one of the first spam filters ever implemented. The second classifier is a decision tree classifier.
The naive Bayes classifier achieved >93% accuracy and the decision tree achieved >90% accuracy.
Filename: email_spam_load_emails.py
The emails are taken from the Enron email dataset.
I first removed numbers and words with non-alphanumeric characters. The remaining words are put through a word stemmer so that the all words derived from the same word are counted as the same word.
Each email is represented using the bag-of-words model. I first built a dictionary of all possible words in the emails. Then, each email is reprensted by a vector where each entry is the number of times that word appears in the email. This model ignores the relative ordering of the words.
Filename: email_spam_naive_bayes.py
The Naïve Bayes is based on the Bayes rule. Given a test email test_email, we estimate the probability of it being a spam email as follows:
P(spam|test_email) = P(test_email|spam) * P(spam) / P(test_email)
If P(spam|test_email) > P(ham|test_email), then the email is classified as spam and vice versa.
To estimate the conditional on the right hand side, we use the independence of word counts that's reflected in the bag of words model. If test_email consists of words word1, word2, ... the conditional is given by
P(test_email|spam) = P(word1|spam) * P(word2|spam) * ...
Each of the terms can be estimated using the count rate for each word (a multinomial distribution). So if word1 occurrs word1_count times in test_email,
P(word1|spam) = # of spam emails in the training set where word1 appeared word1_count times / # of spam emails in the trainig set
Finally, I tried several different priors and compared their performance.
One problem with the above expressions is that if P(word1|spam) is zero, then P(test_email|spam) would be zero irrespective of the counts for other words. To avoid this problem, a pseudocount pc is used. Each word is assumed to appear pc number of times in every email in the training set.
Another problem is that a word can potentially appear infinitely many times in an email. So in principle, I should track of an infinite number of possible counts. To avoid this, I used a maximum count mc. If a word appears more than mc times in an email, I treat it as appearing mc times.
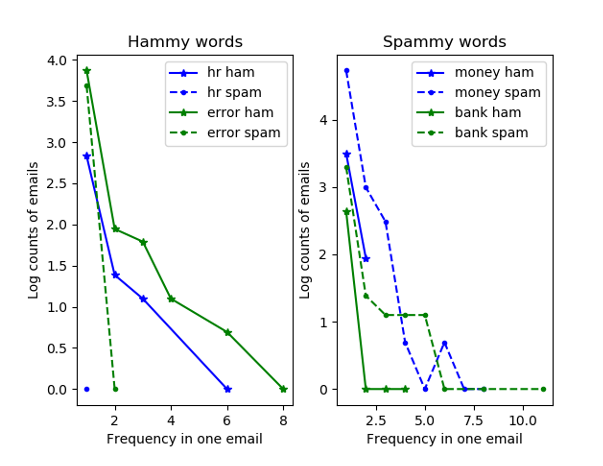
First, we can visualize the dataset by considering some "hammy" and "spammy" words. Words like hr and error are much more likely to appear in ham emails than spam, while words such as bank and money appear more often in spam emails.
I used a total of 5172 emails of which 3672 were ham and 1500 were spam. I used a train-test split of 80-20.
In this case, I set P(spam) = # of spam emails in the training set / # of emails in the training set. The overall accuracy was 91.85%.
Confusion matrix:
| Type | Classified Ham | Classified Spam |
|---|---|---|
| Actually Ham | 89.55 | 10.45 |
| Actually Spam | 2.05 | 97.95 |
In this case, P(ham) = P(spam). Overall accuracy 92.13%
Confusion matrix:
| Type | Classified Ham | Classified Spam |
|---|---|---|
| Actually Ham | 89.16 | 10.84 |
| Actually Spam | 0 | 100 |
Overall accuracy 93.52%
Confusion matrix:
| Type | Classified Ham | Classified Spam |
|---|---|---|
| Actually Ham | 87.74 | 12.26 |
| Actually Spam | 0 | 100 |
Filename: email_spam_decision_tree.py
Here, I used a single decision tree to classify the emails.
For a single decision tree, there are two hyperparamters that control the complexity of the tree. First is the number of features which in this case is the number of words that are included in the decision tree. I chose the words in a greedy fashion by considering their interclass variance:
interclass_var = abs(ham_mean - spam_mean) / (ham_mean + spam_mean)
where ham_mean is the number of times the word appears in ham emails and spam_mean is the number of times the word appears in spam emails. Words that appear the same number of times in both ham and spam emails on average have a variance of zero while words that only appear in either ham or spam emails would have a variance of 1.
Here's a histogram of the variance for all the words in the dataset
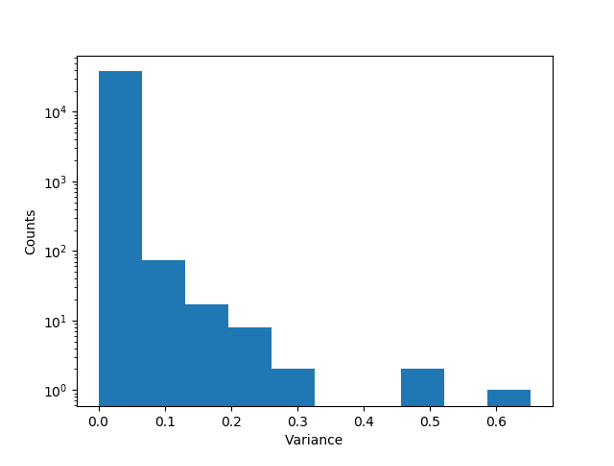
Most words have a variance of zero. The words with the highest variance were ect, hou, fischer, unoc, purchas and to.
The second hyperparameter is the number of nodes in the decision tree. I set this to be at least twice the number of features.
Here are the results with 13 features and 256 nodes
Overall accuracy 86.04%
Confusion matrix:
| Type | Classified Ham | Classified Spam |
|---|---|---|
| Actually Ham | 82.19 | 17.81 |
| Actually Spam | 3.77 | 96.23 |
With 59 features and 256 nodes, the overall accuracy is slightly better even though the precision of spam classification is lower
Overall accuracy 86.79%
Confusion matrix:
| Type | Classified Ham | Classified Spam |
|---|---|---|
| Actually Ham | 84.77 | 15.23 |
| Actually Spam | 7.88 | 92.12 |
With more and more features, the accuracy improved before eventually decreasing because of overfitting
| Features | Nodes | Overall accuracy |
|---|---|---|
| 142 | 256 | 86.97% |
| 327 | 256 | 87.25% |
| 327 | 1024 | 90.72% |
| 1128 | 2048 | 91.28% |
| 2122 | 4096 | 91% |
With more careful hyperparameter tuning, the accuracy could be improved.
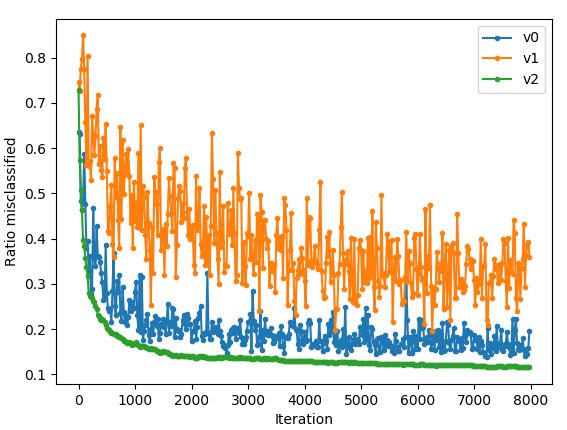
Filename: perceptron_mnist.py
Here, I used different perceptron algorithms to classify handwritten digits (MNIST dataset). I achieved close to 90% accuracy even with this very simple linear classifier.