Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[SPARK-42591][SS][DOCS] Add examples of unblocked workloads after SPA…
…RK-42376 ### What changes were proposed in this pull request? This PR proposes to add examples of unblocked workloads after SPARK-42376, which unblocks stream-stream time interval join followed by stateful operator. ### Why are the changes needed? We'd like to remove the description of limitations which no longer exist, as well as provide some code examples so that users can get some sense how to use the functionality. ### Does this PR introduce _any_ user-facing change? Yes, documentation change. ### How was this patch tested? Created a page via SKIP_API=1 bundle exec jekyll serve --watch and confirmed. Screenshots: > Scala 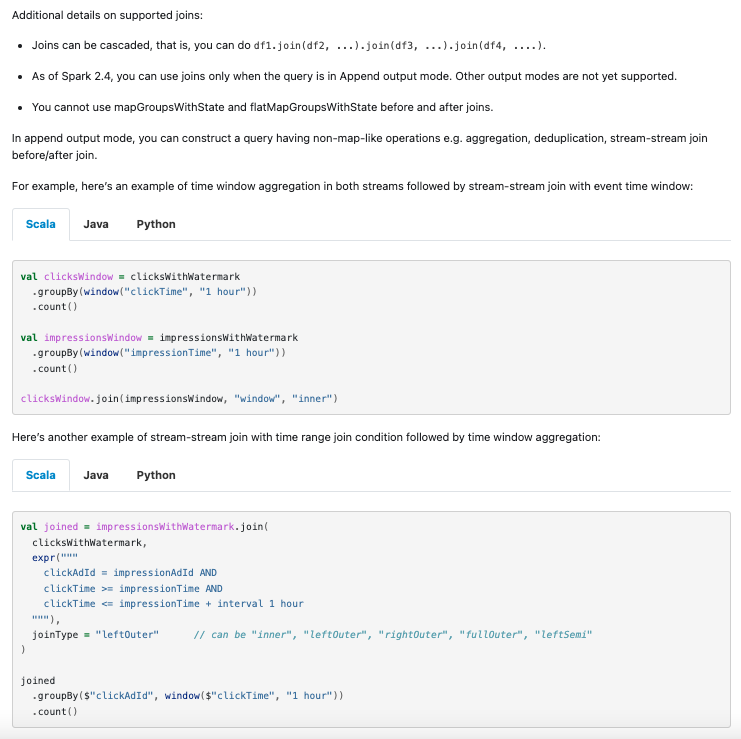 > Java 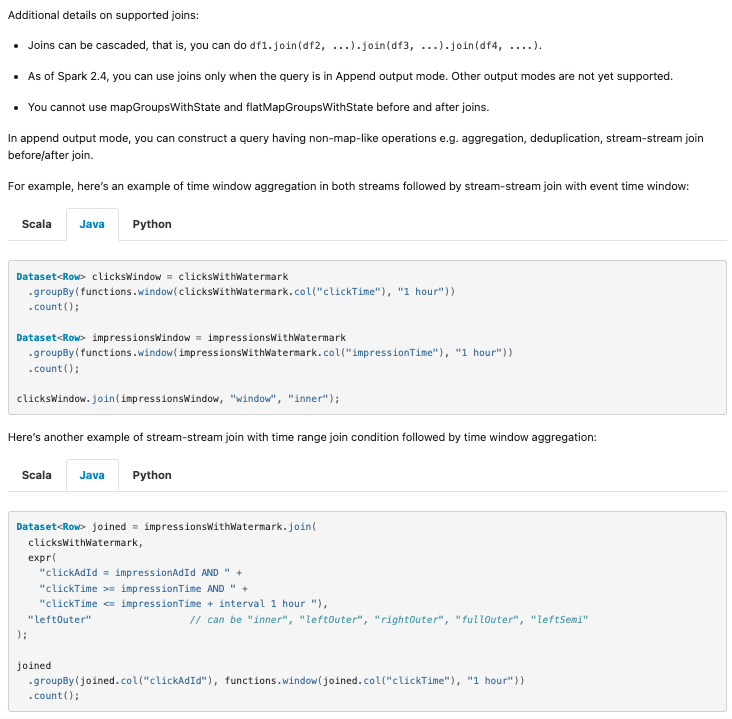 > Python 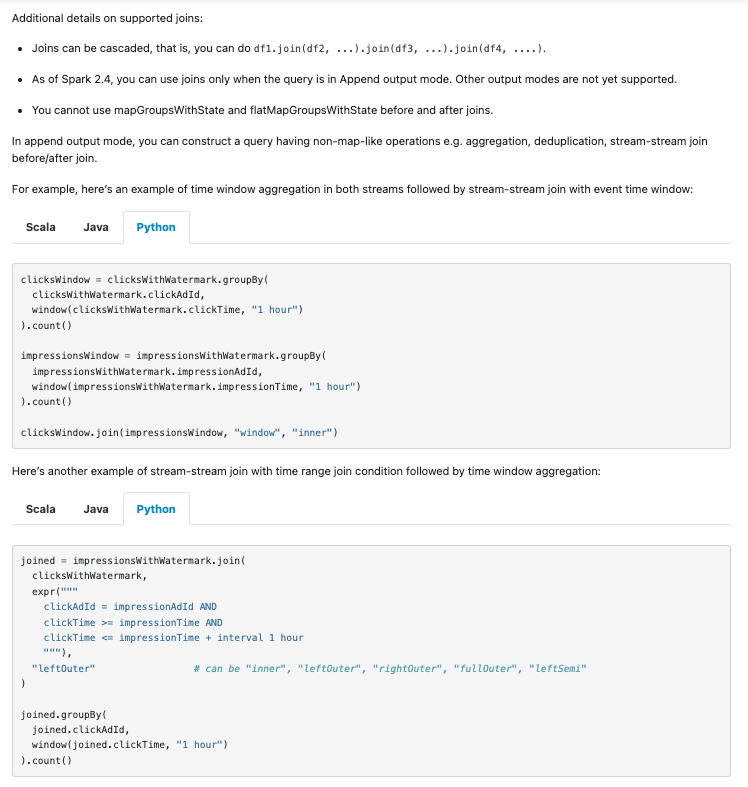 Closes apache#40215 from HeartSaVioR/SPARK-42591. Authored-by: Jungtaek Lim <[email protected]> Signed-off-by: Jungtaek Lim <[email protected]>
{kind=link}
{kind=link}
{kind=link}
- Loading branch information
1 parent
51504e4
commit 27c34bd