MyHeyGen | EN
一个平民版视频翻译工具,音频翻译,翻译校正,视频唇纹合成全流程解决方案
HeyGenClone、TTS、Video-retalking、CodeFormer
- 【MyHeyGen | 你听过张三老师的英文脱口秀吗?】
- 【MyHeyGen | 1个月,头发都秃了,终于实现视频翻译自由啦!】
- voice_only效果 【MyHeyGen测试 | 音视频已经无缝对齐了,这是VOICE_ONLY模式】
- finetune效果 【MyHeyGen测试 | 节选霉霉的NYU毕业演讲片段】
- 【6种语言向世界报喜,我的女儿面面出生啦 ! | MyHeyGen 用例】
【MyHeyGen教程|这样配置应该简单很多吧】 相当于一键包,不需要配环境,但是得微氪金
此开源代码只能用于研究/学术/个人目的,严格禁止任何形式的商业用途。如有商业要求,请直接联系我们!
- GPU >= 24GB, Pyhton >= 3.10.0, torch 2.1.0, cuda:11.8
- 在huggingface申请token,放在config.json的HF_TOKEN参数下,分别同意
speaker-diarization和segmentation的使用协议 - 在百度翻译申请APPKey用于翻译字幕放在config.json的TS_APPID和TS_APPKEY参数下
- 下载
weightsdrive放在MyHeyGen目录下,下载checkpointsdrive 放在video-retalking目录下,从weights复制GFPGANv1.4.pth到checkpoints,如下图
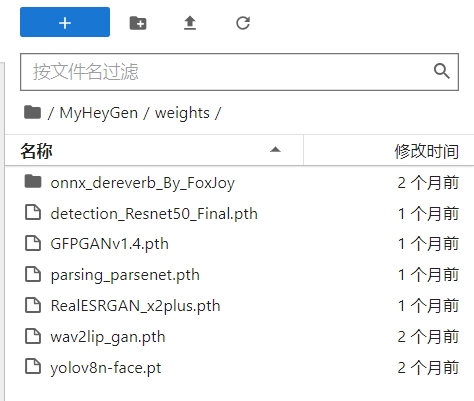
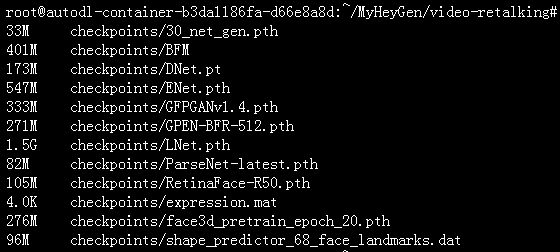
1.Linux
git clone https://github.com/AIFSH/MyHeyGen.git
cd MyHeyGen
bash install.sh
2.Mac M series确保依赖版本号正确
git clone https://github.com/AIFSH/MyHeyGen.git
cd MyHeyGen
bash install.sh
pip install tensorflow=2.13.0
pip install numpy=1.22.2
群友weiraneve反馈已跑通
3.或者拉取docker镜像
docker pull registry.cn-beijing.aliyuncs.com/codewithgpu2/aifsh-myheygen:27YrVoDwTG
python translate.py /root/MyHeyGen/test/src.mp4 'zh-cn' -o /root/MyHeyGen/test/out_zh.mp4
python translate.py 原视频文件路径 想要翻译成的语言代码 -o 翻译好的视频路径
## 语言代码可以选择这些中之一:['en', 'es', 'fr', 'de', 'it', 'pt', 'pl', 'tr', 'ru', 'nl', 'cs', 'ar', 'zh-cn', 'ja','hu','ko']
##分别对应[英语、西班牙语、法语、德语、意大利语、葡萄牙语、波兰语、土耳其语、俄语、荷兰语、捷克语、阿拉伯语、中文(简体)、日语、匈牙利语、韩语]16种语言
- 2023.11.7 add TTS_MODEL in config.json to custom model
- 2023.11.8 update TTS for more reality
- 2023.11.9 fix video-retalking oface error
- 2023.11.10 fix librosa version conflict with latest TTS
- 2023.11.16 add finetune for voice cloning(test on GPU A5000 24GB)
- 2023.11.19 Huge update !!! add codeformer,h5 vocal split,rewrite audio aligment,voice-only mode
{
"DET_TRESH": 0.3,
"DIST_TRESH": 0.2,
"DB_NAME": "storage.db",
"HF_TOKEN": "", ## 从huggingface申请的token
"TS_APPID": "", ## 从百度翻译申请,注意开通“通用文本翻译”功能
"TS_APPKEY": "", ## 从百度翻译申请,注意开通“通用文本翻译”功能
"HUMAN_TRANS": 0, ## 1表示开启人工翻译校正 0 表示不干预百度翻译结果
"TTS_MODEL":"tts_models/multilingual/multi-dataset/xtts_v2",
"FT_TTS_MODEL": "" ##填入finetune模型所在文件夹的绝对路径则开启TTS的finetune模式
"AUDIO_H5": 0, ## 1 使用H5做人声分离算法 0 不使用
"VOICE_ONLY": 0 ## 1 只处理音频文件 0 不开启
}
GPU A5000 24GB测试通过,请自行修改xtts_ft.sh 相关参数
python xtts_ft.py luoxiang /root/autodl-tmp/xtts_ft/luoxiang/speaker.WAV /root/autodl-tmp/xtts_ft 3 1
# luoxiang 说话人编号
# /root/autodl-tmp/xtts_ft/luoxiang/speaker.WAV 语料路径,支持.wav,.mp4文件,建议时长30min以上,音质佳,杂音少
# /root/autodl-tmp/xtts_ft 这是fine-tune工作路径,建议可用存储空间在20GB以上
# 3 这是fine-tune的batch_size
# 1 这里指定是否生成fine-tune所需的dataset,填 0 则不需要再次生成