Comparison of messaging patterns
This document outlines design patterns used to realise the Atomic Messaging requirement.
The software development industry is on a firm course towards a combination of distributed µ-services and event-driven architecture, as a means of realising greenfield software projects and modernising legacy applications.
One of the notable challenges of this architectural style is maintaining consistency across disparate systems. Used correctly, Kafka's topic-partition model enables causal consistency — a trait that most designers of distributed applications have come to rely upon heavily.
Causal consistency captures the potential causal relationships between operations, and guarantees that all processes observe causally-related operations in a common order. In other words, all processes in the system agree on the order of the causally-related operations. They may disagree on the order of causally unrelated operations.
For this to work, we need to guarantee that all changes to systems of record are followed by a corresponding event on Kafka, on the same partition as all prior related events. And therein lies the snag: the way most applications publish events today does not satisfy this guarantee in all cases. Specifically, it is not tolerant of process failures. The updating of master data and the publishing of corresponding events is not an atomic operation, meaning that a midstream failure will leave the system in an inconsistent state.
To understand the problem, consider the following diagram.
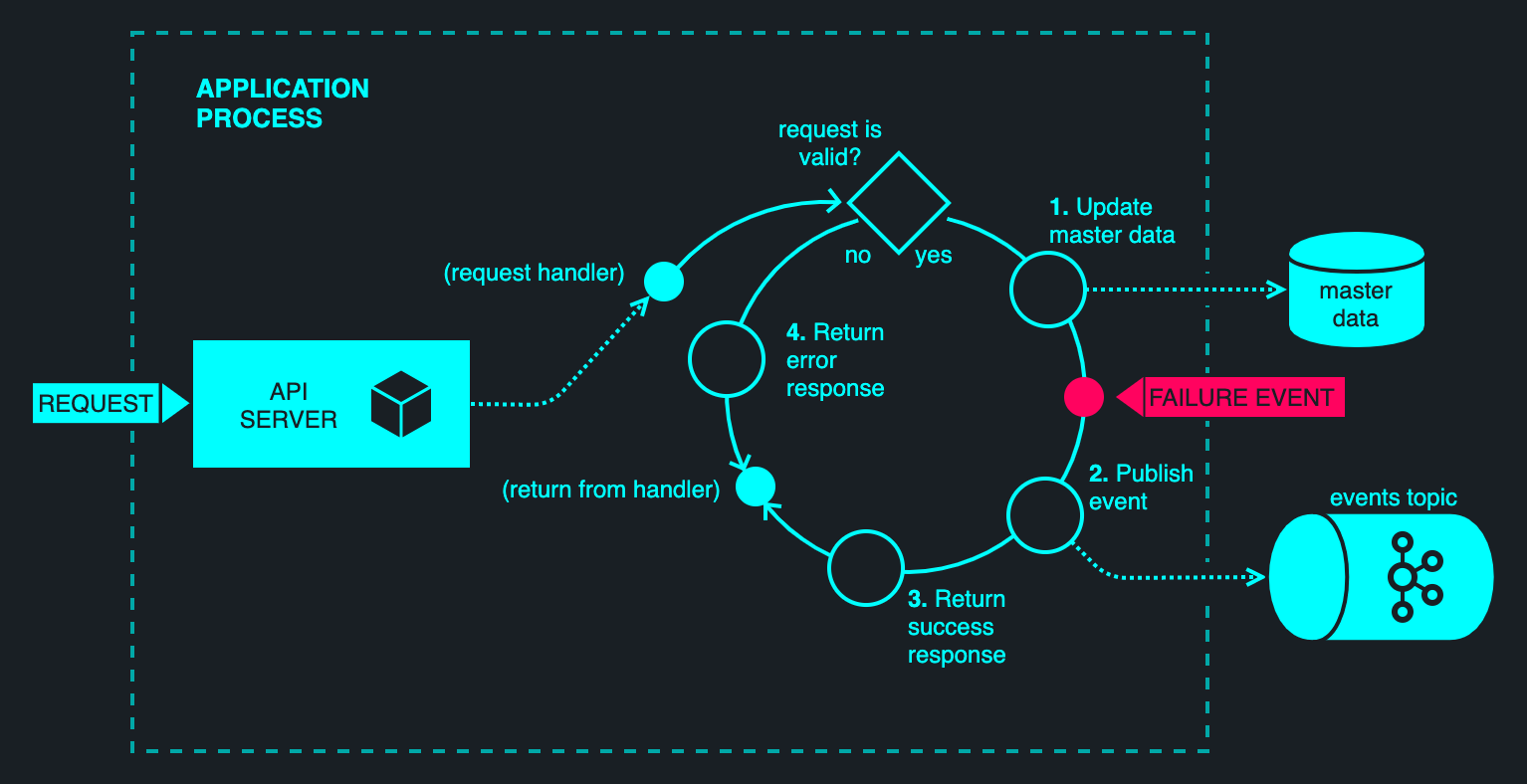
The figure above illustrates a typical web-based application, comprising an API server that makes changes to some underlying persistent datastore and broadcasts corresponding events on Kafka. Presumably, one or more downstream applications consume these events and update their own state projections accordingly, or otherwise react to the published events in some business-meaningful way. Most event-driven applications will have one or more such elements scattered about their implementation.
The challenge here is maintaining the mutual consistency of the state of the database and the message bus in the event of failure. The failure could come in the form of abrupt process termination, or a network partition that prevents one of the two I/O operations to complete successfully.
By way of example, consider a process failure between steps #1 and #2 — this is a classical situation where a state change is stably recorded but no corresponding event is observed. This situation is difficult to identify when it occurs, and even more difficult to resolve. (One cannot simply publish a missed message, because other related messages may have been published since. Doing so indiscriminately may violate causality among messages.)
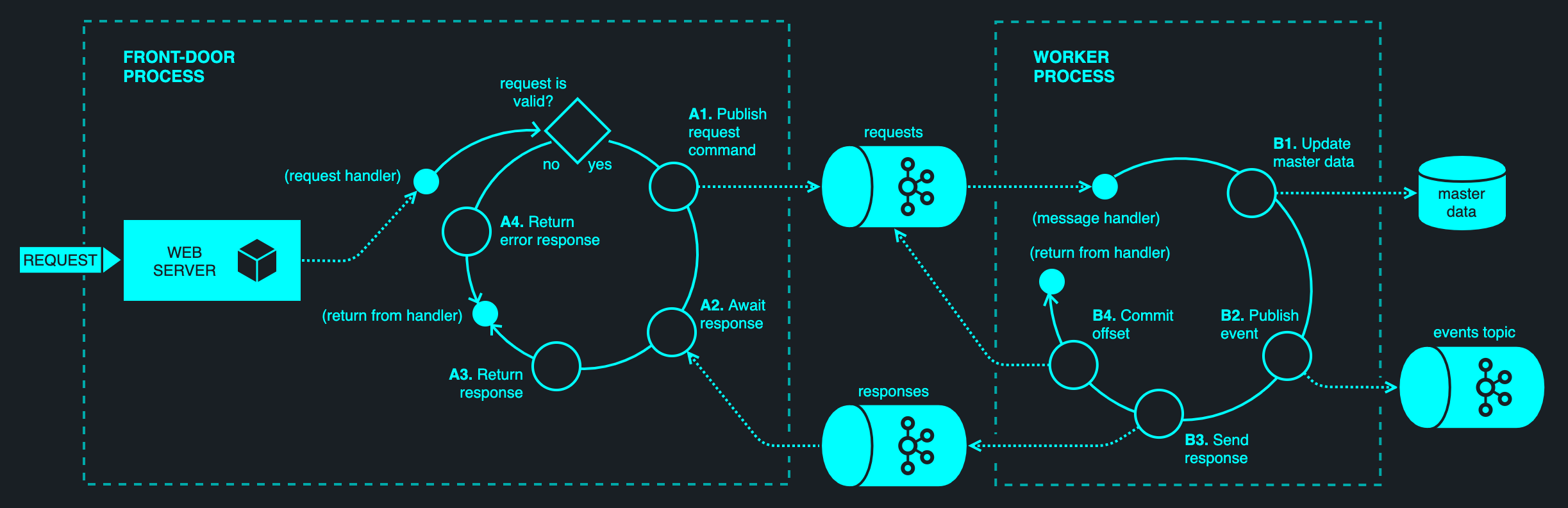
For the typical scenario of an API-initiated entity update, the Front-Door Queue separates the acceptance of the API request from its subsequent servicing.
Two processes (or threads) operate on a request in tandem. The front-door process is responsible for accepting a request and queuing it onto an internal request queue. The worker process subsequently pops the command from the request queue and processes it. The processing of a request may have side effects — updating of database tables and sending of Kafka messages. Once a request has been processed, the worker sends a response message that is correlated to the request and commits the offsets for the request queue.
Having matched an earlier request to its corresponding response message, the front-door process synchronously delivers the response to the API consumer. A timeout is typically enforced; if the worker fails to produce a response within a set time frame, the front-door process replies with a 504 Gateway Timeout status code.
Since the committing of offsets is the last step in the process, a failure at any point leaves the message uncommitted. Kafka will rebalance partitions following a consumer failure, assigning the request partitions to the remaining workers. When the processing resumes, the next worker will process the message from the beginning. This may lead to duplication (and appropriate idempotence controls should be in place), but all side effects will take place eventually.
| Benefits | Drawbacks |
|---|---|
| Transaction scope is not necessary. | Requirement to use two threads/processes, both of which are application-specific. |
| Idiomatic to event streaming pipelines, whereby the initial API request is treated as an event in its own right. | Cannot be easily retrofitted, requiring fundamental architectural changes to existing applications. |
| Service uptime is directly coupled to Kafka. If the brokers are down or experiencing degraded performance, the servicing of API requests is impacted. In the worst case, API requests will time out. | |
| Adds a significant amount of latency to request handling — owing to a pair of queues and asynchronous processing. Kafka is throughput-optimised by design; the added round-trip will be in the order of hundreds of milliseconds. | |
| Response messages cannot be selectively cherry-picked by the initial requester. Every front-door handler instance is forced to consume all response messages, matching them to outstanding requests. Alternatively, each front-door handler may have its own short-lived response queue, but this complicates queue management. |
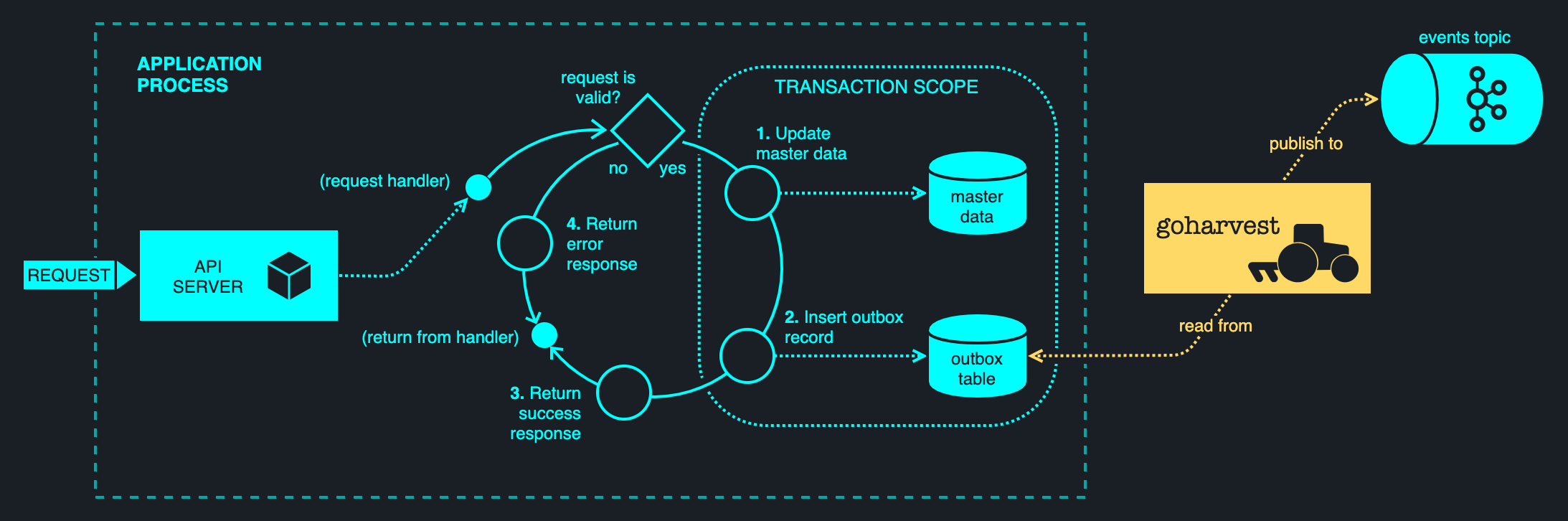
The transactional outbox pattern separates the queueing of a message from its publishing, employing the database as a persistent buffer. Updates to entity tables and the enqueuing of the message are performed in a transaction. A downstream outbox harvester aggregates the backlogged messages and publishes them asynchronously. A failure in the harvester may be retried indefinitely — there is no impact to the servicing of the request. This pattern is illustrated below.
| Benefits | Drawbacks |
|---|---|
| Once implemented, can easily be reused for a given combination of DBMS and message broker. | Requires some changes to the application to write to an outbox table, rather than directly to Kafka. |
| Removes the Kafka dependency from the application, not just from a library standpoint, but also operationally. Requests are not reliant on the availability of Kafka. If Kafka is down, the servicing of API requests may continue without interruptions. Removal of Kafka from the transaction path positively contributes to service availability. |
Change Data Capture (CDC) is a variation of the transactional outbox pattern that uses a proprietary database capability for capturing row-by-row deltas. The outbox harvester then tails the CDC records rather than a primary table.
| Benefits | Drawbacks |
|---|---|
| CDC presents data in the order they were committed, rather than the order in which the sequence numbers were assigned. There are no gaps and the audit records and queries are straightforward. | CDC is not portable. Not all databases support CDC, and those that do might not offer CDC capability on managed offerings. For example, AWS offers CDC on conventional RDS, but not Aurora. Google Cloud SQL does not offer CDC at all. (Log-based CDC requires parsing of the database Write-Ahead Log, which means additional software must be running on each database server node.) |
| Tracking of the harvester state is reduced to a basic offset, owing to the favourable property that CDC records are monotonic. |
Due to the asynchronous nature of publishing and the prospect of failures, we need to store a delivery state for each outbox record. Depending on how CRC is implemented, this may not be trivial.
|
| Log-based CDC is not enabled at the database, but at the master node. (This is the case for Postgres; others may differ.) If a failover occurs, logical replication must be explicitly re-enabled on the new active node. The failover event may not be apparent to the application, particularly when using a Cloud-based service. Trigger-based CDC does not suffer from this approach, but is markedly less efficient than the log-based model. |
While it appears straightforward on the surface, there are several challenges inherent in CDC:
One of the characteristics of this approach is that it couples the harvester to the CDC schema, making it application-specific. (And thereby, not reusable.) This can be addressed by using an intermediate outbox table, which is subsequently CDC-enabled; in other words, a hybrid Outbox-CDC model. The application writes to both an entity table and the outbox in transaction scope as per the traditional Transactional Outbox pattern; the harvester reads from a CDC table or stream (depending on the DBMS). Because CDC sources from the outbox, it can be structured generically, yielding a reusable harvester implementation.
Under the models above, the publishing of a message is an explicit action initiated by the application. In other words, the application is aware of the messaging concern and addresses it explicitly (by either publishing directly or via an intermediate outbox).
An alternative approach is where the application is unaware of messaging — it updates its entity tables as it were. Another process scrapes these tables, identifying changes and publishing these as Kafka messages.
The main limitation of this approach is that individual changes are not captured — the harvester sees snapshots of data and compares entity states at arbitrary points in time. This model may not be suitable in all applications.
| Benefits | Drawbacks |
|---|---|
| Where the outbox (and its CDC-based variant) requires additional elements in the database schema, this model largely relies on the existing tables. Sometimes minor changes are introduced, such as the addition of timestamps, to identify changes in existing rows. | Implementation is entirely application-specific. Every application requires a bespoke harvester implementation. |
| May be suitable for legacy applications that might not be easily refactored to use other patterns. | Coarse-grained change capture that is unable to identify discrete changes, leading to gaps in historic data. |
Of the models above, Front-Door Queuing and Direct Entity Scraping are unsuitable for most applications.
Front-Door Queueing requires significant rework of existing applications and couples request servicing to Kafka, which may negatively impact the service uptime rating. While this model is idiomatic to event streaming pipelines, most of Atomic Messaging needs stem from interactive API requests, which have near-real-time servicing requirements. In contrast, event streaming pipelines generally operate under non-real-time constraints.
Scraping of entity tables does not work in all scenarios and requires copious amounts of application-specific code that cannot be easily reused.
The two that stack up are the Transactional Outbox and its CDC-based variation. As far as the application is concerned, both models provide an identical interface — a straightforward INSERT into the outbox table within a transaction. Of the two, CDC is the least portable approach and requires additional configuration on the database. It is also more difficult to administer. It can also be problematic during the failover of the active database node.
The Transactional Outbox is the preferred approach. Harvesting an outbox is not straightforward; however, the complexities of the implementation are fully encapsulated in a library. The result is a simple to use Atomic Messaging solution that is straightforward to configure and operate, and can be used with just about any application.
![]()