forked from pytorch/serve
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge branch 'master' into 2-hardware-agnostic-front-and-backend
- Loading branch information
Showing
36 changed files
with
2,422 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -30,6 +30,7 @@ test/model_store/ | |
| test/ts_console.log | ||
| test/config.properties | ||
|
|
||
| model-store-local/ | ||
|
|
||
| .vscode | ||
| .scratch/ | ||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,280 @@ | ||
| ## Multi-Image Generation Streamlit App: Chaining Llama & Stable Diffusion using TorchServe, torch.compile & OpenVINO | ||
|
|
||
| This Multi-Image Generation Streamlit app is designed to generate multiple images based on a provided text prompt. Instead of using Stable Diffusion directly, this app chains Llama and Stable Diffusion to enhance the image generation process. Here’s how it works: | ||
| - The app takes a user prompt and uses [Meta-Llama-3.2](https://huggingface.co/meta-llama) to create multiple interesting and relevant prompts. | ||
| - These generated prompts are then sent to Stable Diffusion with [latent-consistency/lcm-sdxl](https://huggingface.co/latent-consistency/lcm-sdxl) model, to generate images. | ||
| - For performance optimization, the models are compiled using [torch.compile using OpenVINO backend.](https://docs.openvino.ai/2024/openvino-workflow/torch-compile.html) | ||
| - The application leverages [TorchServe](https://pytorch.org/serve/) for efficient model serving and management. | ||
|
|
||
| 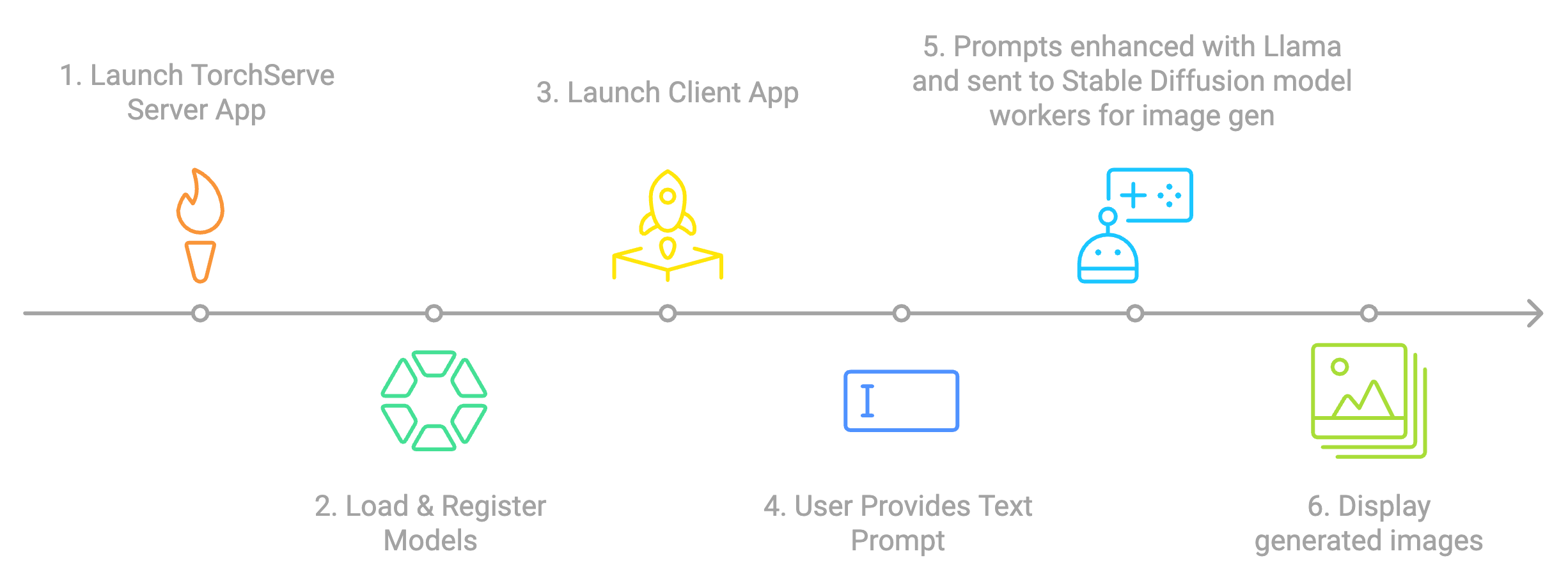 | ||
|
|
||
| ## Quick Start Guide | ||
|
|
||
| **Prerequisites**: | ||
| - Docker installed on your system | ||
| - Hugging Face Token: Create a Hugging Face account and obtain a token with access to the [meta-llama/Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct) model. | ||
|
|
||
| To launch the Multi-Image Generation App, follow these steps: | ||
| ```bash | ||
| # 1: Set HF Token as Env variable | ||
| export HUGGINGFACE_TOKEN=<HUGGINGFACE_TOKEN> | ||
|
|
||
| # 2: Build Docker image for this Multi-Image Generation App | ||
| git clone https://github.com/pytorch/serve.git | ||
| cd serve | ||
| ./examples/usecases/llm_diffusion_serving_app/docker/build_image.sh | ||
|
|
||
| # 3: Launch the streamlit app for server & client | ||
| # After the Docker build is successful, you will see a "docker run" command printed to the console. | ||
| # Run that "docker run" command to launch the Streamlit app for both the server and client. | ||
| ``` | ||
|
|
||
| #### Sample Output of Docker Build: | ||
|
|
||
| <details> | ||
|
|
||
| ```console | ||
| ubuntu@ip-10-0-0-137:~/serve$ ./examples/usecases/llm_diffusion_serving_app/docker/build_image.sh | ||
| EXAMPLE_DIR: .//examples/usecases/llm_diffusion_serving_app/docker | ||
| ROOT_DIR: /home/ubuntu/serve | ||
| DOCKER_BUILDKIT=1 docker buildx build --platform=linux/amd64 --file .//examples/usecases/llm_diffusion_serving_app/docker/Dockerfile --build-arg BASE_IMAGE="pytorch/torchserve:latest-cpu" --build-arg EXAMPLE_DIR=".//examples/usecases/llm_diffusion_serving_app/docker" --build-arg HUGGINGFACE_TOKEN=hf_<token> --build-arg HTTP_PROXY= --build-arg HTTPS_PROXY= --build-arg NO_PROXY= -t "pytorch/torchserve:llm_diffusion_serving_app" . | ||
| [+] Building 1.4s (18/18) FINISHED docker:default | ||
| => [internal] load .dockerignore 0.0s | ||
| . | ||
| . | ||
| . | ||
| => => naming to docker.io/pytorch/torchserve:llm_diffusion_serving_app 0.0s | ||
|
|
||
| Docker Build Successful ! | ||
|
|
||
| ............................ Next Steps ............................ | ||
| -------------------------------------------------------------------- | ||
| [Optional] Run the following command to benchmark Stable Diffusion: | ||
| -------------------------------------------------------------------- | ||
|
|
||
| docker run --rm --platform linux/amd64 \ | ||
| --name llm_sd_app_bench \ | ||
| -v /home/ubuntu/serve/model-store-local:/home/model-server/model-store \ | ||
| --entrypoint python \ | ||
| pytorch/torchserve:llm_diffusion_serving_app \ | ||
| /home/model-server/llm_diffusion_serving_app/sd-benchmark.py -ni 3 | ||
|
|
||
| ------------------------------------------------------------------- | ||
| Run the following command to start the Multi-Image generation App: | ||
| ------------------------------------------------------------------- | ||
|
|
||
| docker run --rm -it --platform linux/amd64 \ | ||
| --name llm_sd_app \ | ||
| -p 127.0.0.1:8080:8080 \ | ||
| -p 127.0.0.1:8081:8081 \ | ||
| -p 127.0.0.1:8082:8082 \ | ||
| -p 127.0.0.1:8084:8084 \ | ||
| -p 127.0.0.1:8085:8085 \ | ||
| -v /home/ubuntu/serve/model-store-local:/home/model-server/model-store \ | ||
| -e MODEL_NAME_LLM=meta-llama/Llama-3.2-3B-Instruct \ | ||
| -e MODEL_NAME_SD=stabilityai/stable-diffusion-xl-base-1.0 \ | ||
| pytorch/torchserve:llm_diffusion_serving_app | ||
|
|
||
| Note: You can replace the model identifiers (MODEL_NAME_LLM, MODEL_NAME_SD) as needed. | ||
|
|
||
| ``` | ||
|
|
||
| </details> | ||
|
|
||
| ## What to expect | ||
| After launching the Docker container using the `docker run ..` command displayed after a successful build, you can access two separate Streamlit applications: | ||
| 1. TorchServe Server App (running at http://localhost:8084) to start/stop TorchServe, load/register models, scale up/down workers. | ||
| 2. Client App (running at http://localhost:8085) where you can enter prompt for Image generation. | ||
|
|
||
| > Note: You could also run a quick benchmark comparing the performance of Stable Diffusion with Eager, torch.compile with inductor and openvino. | ||
| > Review the `docker run ..` command displayed after a successful build for benchmarking | ||
| #### Sample Output of Starting the App: | ||
|
|
||
| <details> | ||
|
|
||
| ```console | ||
| ubuntu@ip-10-0-0-137:~/serve$ docker run --rm -it --platform linux/amd64 \ | ||
| --name llm_sd_app \ | ||
| -p 127.0.0.1:8080:8080 \ | ||
| -p 127.0.0.1:8081:8081 \ | ||
| -p 127.0.0.1:8082:8082 \ | ||
| -p 127.0.0.1:8084:8084 \ | ||
| -p 127.0.0.1:8085:8085 \ | ||
| -v /home/ubuntu/serve/model-store-local:/home/model-server/model-store \ | ||
| -e MODEL_NAME_LLM=meta-llama/Llama-3.2-3B-Instruct \ | ||
| -e MODEL_NAME_SD=stabilityai/stable-diffusion-xl-base-1.0 \ | ||
| pytorch/torchserve:llm_diffusion_serving_app | ||
|
|
||
| Preparing meta-llama/Llama-3.2-1B-Instruct | ||
| /home/model-server/llm_diffusion_serving_app/llm /home/model-server/llm_diffusion_serving_app | ||
| Model meta-llama---Llama-3.2-1B-Instruct already downloaded. | ||
| Model archive for meta-llama---Llama-3.2-1B-Instruct exists. | ||
| /home/model-server/llm_diffusion_serving_app | ||
|
|
||
| Preparing stabilityai/stable-diffusion-xl-base-1.0 | ||
| /home/model-server/llm_diffusion_serving_app/sd /home/model-server/llm_diffusion_serving_app | ||
| Model stabilityai/stable-diffusion-xl-base-1.0 already downloaded | ||
| Model archive for stabilityai---stable-diffusion-xl-base-1.0 exists. | ||
| /home/model-server/llm_diffusion_serving_app | ||
|
|
||
| Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false. | ||
|
|
||
| Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false. | ||
|
|
||
| You can now view your Streamlit app in your browser. | ||
|
|
||
| Local URL: http://localhost:8085 | ||
| Network URL: http://123.11.0.2:8085 | ||
| External URL: http://123.123.12.34:8085 | ||
|
|
||
|
|
||
| You can now view your Streamlit app in your browser. | ||
|
|
||
| Local URL: http://localhost:8084 | ||
| Network URL: http://123.11.0.2:8084 | ||
| External URL: http://123.123.12.34:8084 | ||
| ``` | ||
|
|
||
| </details> | ||
|
|
||
| #### Sample Output of Stable Diffusion Benchmarking: | ||
| To run Stable Diffusion benchmarking, use the `sd-benchmark.py`. See details below for a sample console output. | ||
|
|
||
| <details> | ||
|
|
||
| ```console | ||
| ubuntu@ip-10-0-0-137:~/serve$ docker run --rm --platform linux/amd64 \ | ||
| --name llm_sd_app_bench \ | ||
| -v /home/ubuntu/serve/model-store-local:/home/model-server/model-store \ | ||
| --entrypoint python \ | ||
| pytorch/torchserve:llm_diffusion_serving_app \ | ||
| /home/model-server/llm_diffusion_serving_app/sd-benchmark.py -ni 3 | ||
| . | ||
| . | ||
| . | ||
|
|
||
| Hardware Info: | ||
| -------------------------------------------------------------------------------- | ||
| cpu_model: Intel(R) Xeon(R) Platinum 8488C | ||
| cpu_count: 64 | ||
| threads_per_core: 2 | ||
| cores_per_socket: 32 | ||
| socket_count: 1 | ||
| total_memory: 247.71 GB | ||
|
|
||
| Software Versions: | ||
| -------------------------------------------------------------------------------- | ||
| Python: 3.9.20 | ||
| TorchServe: 0.12.0 | ||
| OpenVINO: 2024.5.0 | ||
| PyTorch: 2.5.1+cpu | ||
| Transformers: 4.46.3 | ||
| Diffusers: 0.31.0 | ||
|
|
||
| Benchmark Summary: | ||
| -------------------------------------------------------------------------------- | ||
| +-------------+----------------+---------------------------+ | ||
| | Run Mode | Warm-up Time | Average Time for 3 iter | | ||
| +=============+================+===========================+ | ||
| | eager | 11.25 seconds | 10.13 +/- 0.02 seconds | | ||
| +-------------+----------------+---------------------------+ | ||
| | tc_inductor | 85.40 seconds | 8.85 +/- 0.03 seconds | | ||
| +-------------+----------------+---------------------------+ | ||
| | tc_openvino | 52.57 seconds | 2.58 +/- 0.04 seconds | | ||
| +-------------+----------------+---------------------------+ | ||
|
|
||
| Results saved in directory: /home/model-server/model-store/benchmark_results_20241123_071103 | ||
| Files in the /home/model-server/model-store/benchmark_results_20241123_071103 directory: | ||
| benchmark_results.json | ||
| image-eager-final.png | ||
| image-tc_inductor-final.png | ||
| image-tc_openvino-final.png | ||
|
|
||
| Results saved at /home/model-server/model-store/ which is a Docker container mount, corresponds to 'serve/model-store-local/' on the host machine. | ||
|
|
||
| ``` | ||
|
|
||
| </details> | ||
|
|
||
| #### Sample Output of Stable Diffusion Benchmarking with Profiling: | ||
| To run Stable Diffusion benchmarking with profiling, use `--run_profiling` or `-rp`. See details below for a sample console output. Sample profiling benchmarking output files are available in [assets/benchmark_results_20241123_044407/](https://github.com/pytorch/serve/tree/master/examples/usecases/llm_diffusion_serving_app/assets/benchmark_results_20241123_044407) | ||
|
|
||
| <details> | ||
|
|
||
| ```console | ||
| ubuntu@ip-10-0-0-137:~/serve$ docker run --rm --platform linux/amd64 \ | ||
| --name llm_sd_app_bench \ | ||
| -v /home/ubuntu/serve/model-store-local:/home/model-server/model-store \ | ||
| --entrypoint python \ | ||
| pytorch/torchserve:llm_diffusion_serving_app \ | ||
| /home/model-server/llm_diffusion_serving_app/sd-benchmark.py -rp | ||
| . | ||
| . | ||
| . | ||
| Hardware Info: | ||
| -------------------------------------------------------------------------------- | ||
| cpu_model: Intel(R) Xeon(R) Platinum 8488C | ||
| cpu_count: 64 | ||
| threads_per_core: 2 | ||
| cores_per_socket: 32 | ||
| socket_count: 1 | ||
| total_memory: 247.71 GB | ||
|
|
||
| Software Versions: | ||
| -------------------------------------------------------------------------------- | ||
| Python: 3.9.20 | ||
| TorchServe: 0.12.0 | ||
| OpenVINO: 2024.5.0 | ||
| PyTorch: 2.5.1+cpu | ||
| Transformers: 4.46.3 | ||
| Diffusers: 0.31.0 | ||
|
|
||
| Benchmark Summary: | ||
| -------------------------------------------------------------------------------- | ||
| +-------------+----------------+---------------------------+ | ||
| | Run Mode | Warm-up Time | Average Time for 1 iter | | ||
| +=============+================+===========================+ | ||
| | eager | 9.33 seconds | 8.57 +/- 0.00 seconds | | ||
| +-------------+----------------+---------------------------+ | ||
| | tc_inductor | 81.11 seconds | 7.20 +/- 0.00 seconds | | ||
| +-------------+----------------+---------------------------+ | ||
| | tc_openvino | 50.76 seconds | 1.72 +/- 0.00 seconds | | ||
| +-------------+----------------+---------------------------+ | ||
|
|
||
| Results saved in directory: /home/model-server/model-store/benchmark_results_20241123_071629 | ||
| Files in the /home/model-server/model-store/benchmark_results_20241123_071629 directory: | ||
| benchmark_results.json | ||
| image-eager-final.png | ||
| image-tc_inductor-final.png | ||
| image-tc_openvino-final.png | ||
| profile-eager.txt | ||
| profile-tc_inductor.txt | ||
| profile-tc_openvino.txt | ||
|
|
||
| num_iter is set to 1 as run_profiling flag is enabled ! | ||
|
|
||
| Results saved at /home/model-server/model-store/ which is a Docker container mount, corresponds to 'serve/model-store-local/' on the host machine. | ||
|
|
||
| ``` | ||
|
|
||
| </details> | ||
|
|
||
| ## Multi-Image Generation App UI | ||
|
|
||
| ### App Workflow | ||
| 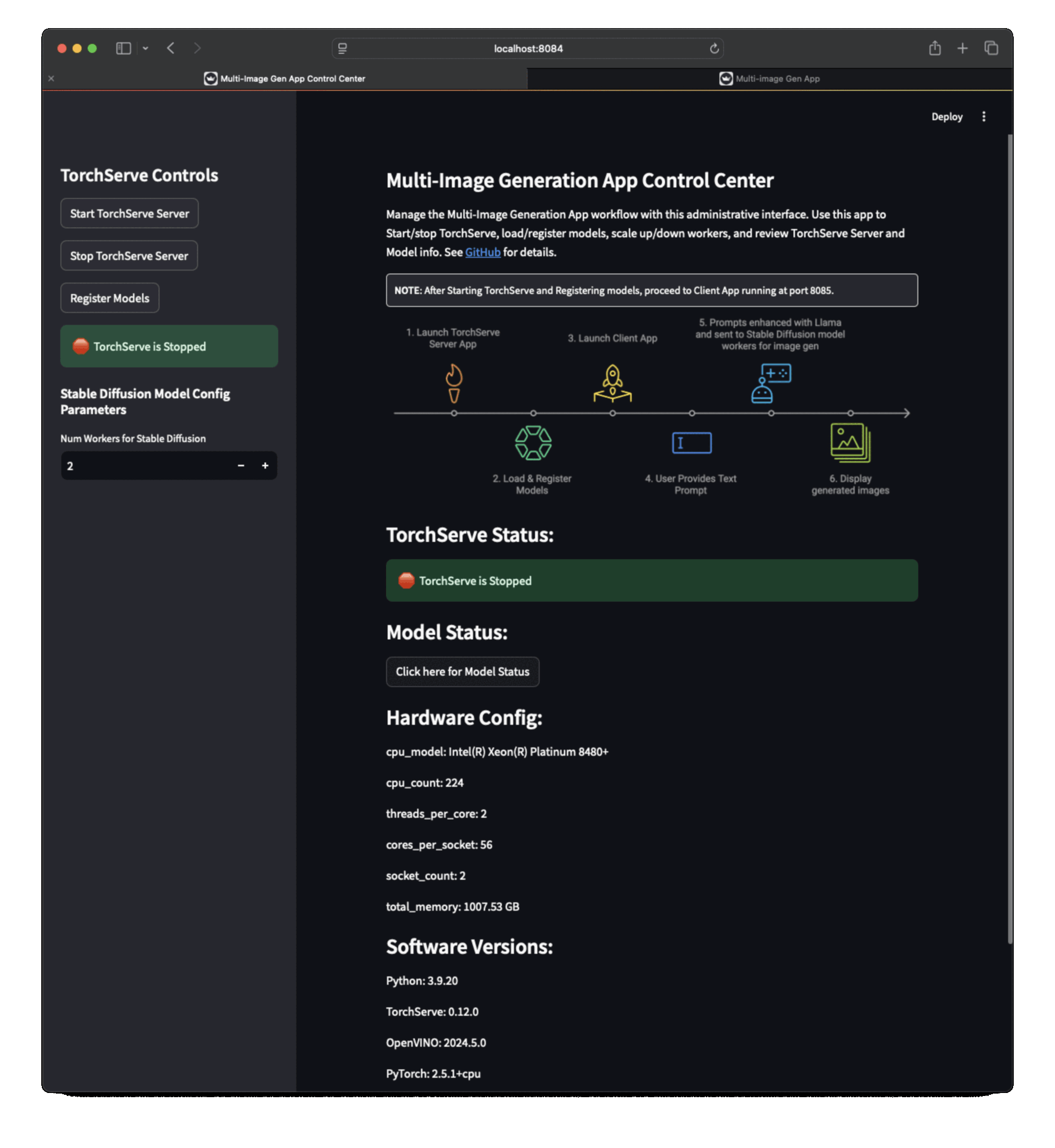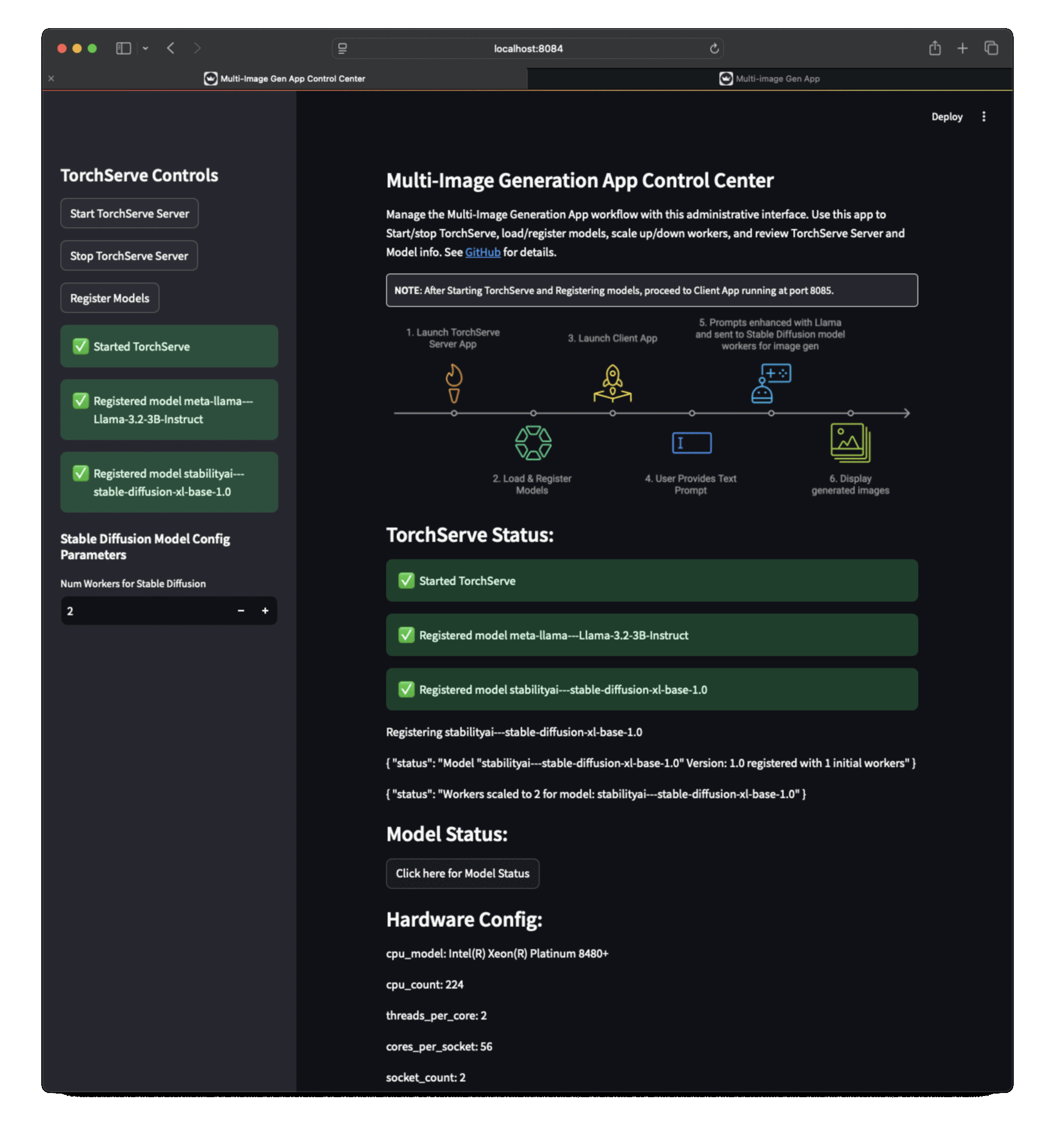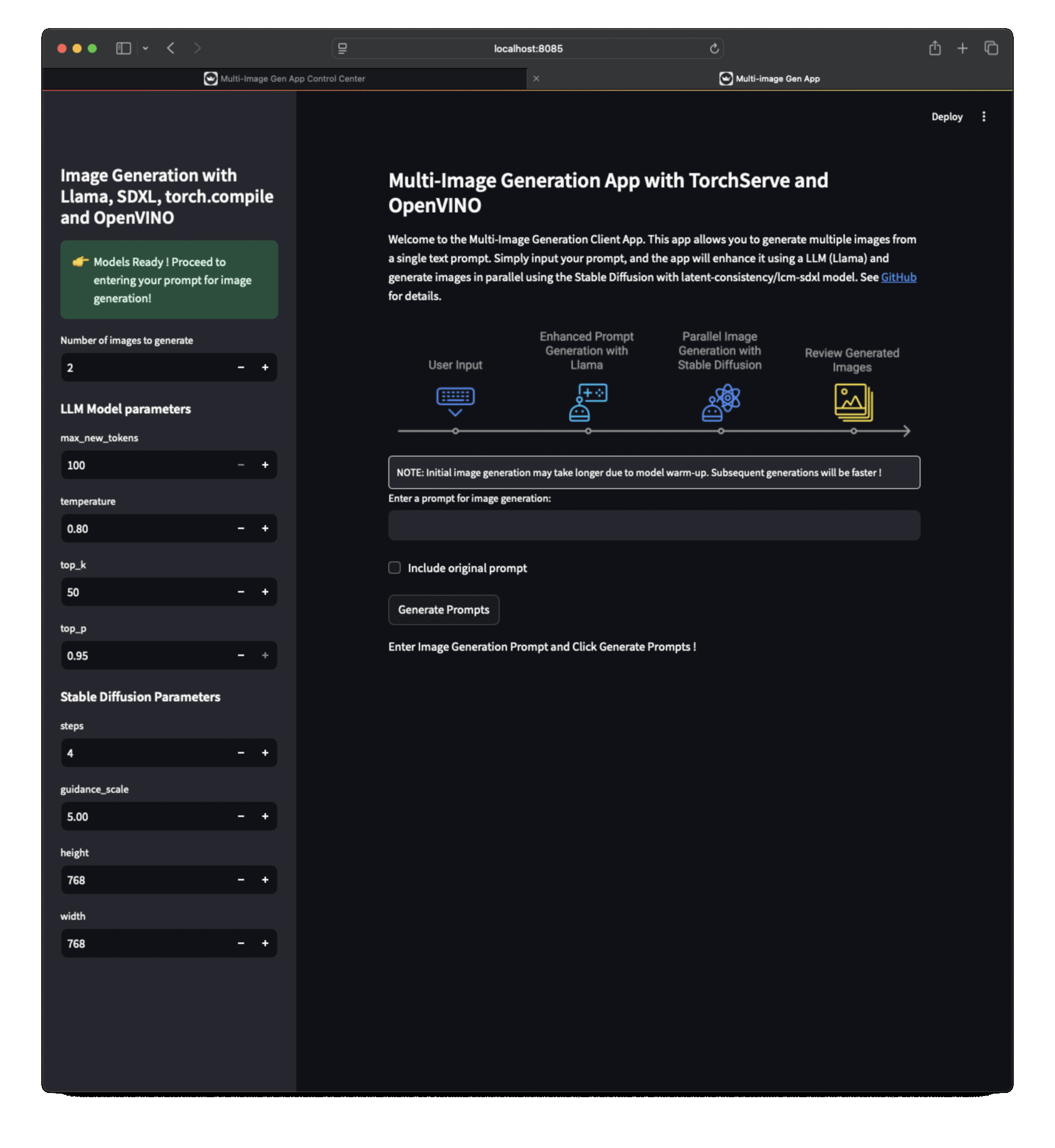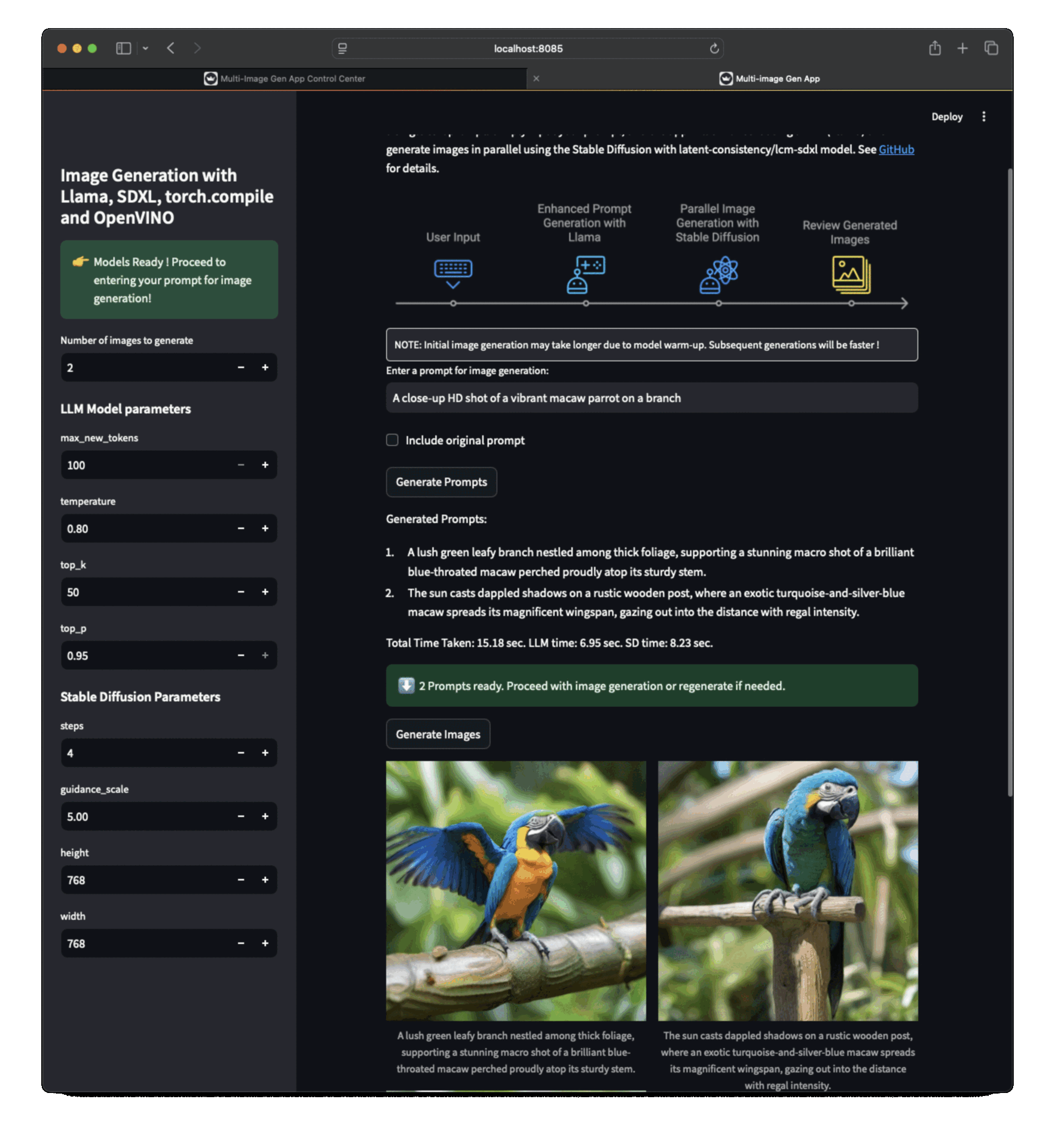 | ||
|
|
||
| ### App Screenshots | ||
|
|
||
| <details> | ||
|
|
||
| | Server App Screenshot 1 | Server App Screenshot 2 | Server App Screenshot 3 | | ||
| | --- | --- | --- | | ||
| | <img src="https://raw.githubusercontent.com/pytorch/serve/master/examples/usecases/llm_diffusion_serving_app/docker/img/server-app-screen-1.png" width="400"> | <img src="https://raw.githubusercontent.com/pytorch/serve/master/examples/usecases/llm_diffusion_serving_app/docker/img/server-app-screen-2.png" width="400"> | <img src="https://raw.githubusercontent.com/pytorch/serve/master/examples/usecases/llm_diffusion_serving_app/docker/img/server-app-screen-3.png" width="400"> | | ||
|
|
||
| | Client App Screenshot 1 | Client App Screenshot 2 | Client App Screenshot 3 | | ||
| | --- | --- | --- | | ||
| | <img src="https://raw.githubusercontent.com/pytorch/serve/master/examples/usecases/llm_diffusion_serving_app/docker/img/client-app-screen-1.png" width="400"> | <img src="https://raw.githubusercontent.com/pytorch/serve/master/examples/usecases/llm_diffusion_serving_app/docker/img/client-app-screen-2.png" width="400"> | <img src="https://raw.githubusercontent.com/pytorch/serve/master/examples/usecases/llm_diffusion_serving_app/docker/img/client-app-screen-3.png" width="400"> | | ||
|
|
||
| </details> |
54 changes: 54 additions & 0 deletions
54
...llm_diffusion_serving_app/assets/benchmark_results_20241123_044407/benchmark_results.json
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,54 @@ | ||
| { | ||
| "timestamp": "2024-11-23T04:44:07.510110", | ||
| "hardware_config": { | ||
| "cpu_model": "Intel(R) Xeon(R) Platinum 8488C", | ||
| "cpu_count": "64", | ||
| "threads_per_core": "2", | ||
| "cores_per_socket": "32", | ||
| "socket_count": "1", | ||
| "total_memory": "247.71 GB" | ||
| }, | ||
| "software_versions": { | ||
| "Python": "3.9.20", | ||
| "TorchServe": "0.12.0", | ||
| "OpenVINO": "2024.5.0", | ||
| "PyTorch": "2.5.1+cpu", | ||
| "Transformers": "4.46.3", | ||
| "Diffusers": "0.31.0" | ||
| }, | ||
| "benchmark_results": [ | ||
| { | ||
| "run_mode": "eager", | ||
| "warmup_time": 11.164182662963867, | ||
| "statistics": { | ||
| "mean": 10.437215328216553, | ||
| "std": 0.0, | ||
| "all_iterations": [ | ||
| 10.437215328216553 | ||
| ] | ||
| } | ||
| }, | ||
| { | ||
| "run_mode": "tc_inductor", | ||
| "warmup_time": 83.48197150230408, | ||
| "statistics": { | ||
| "mean": 8.774884462356567, | ||
| "std": 0.0, | ||
| "all_iterations": [ | ||
| 8.774884462356567 | ||
| ] | ||
| } | ||
| }, | ||
| { | ||
| "run_mode": "tc_openvino", | ||
| "warmup_time": 52.01788377761841, | ||
| "statistics": { | ||
| "mean": 2.633979082107544, | ||
| "std": 0.0, | ||
| "all_iterations": [ | ||
| 2.633979082107544 | ||
| ] | ||
| } | ||
| } | ||
| ] | ||
| } |
Binary file added
BIN
+722 KB
...sion_serving_app/assets/benchmark_results_20241123_044407/image-eager-final.png
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Binary file added
BIN
+819 KB
...erving_app/assets/benchmark_results_20241123_044407/image-tc_inductor-final.png
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Binary file added
BIN
+753 KB
...erving_app/assets/benchmark_results_20241123_044407/image-tc_openvino-final.png
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Oops, something went wrong.