Table of contents
- Parallel Processing Patterns (PP-Patterns)
In the course of developing services, with a primary focus on scalability, throughput, and performance, a set of recurring challenges within the domain of parallel processing frequently surface. These challenges are addressed through specific solutions, which we categorize as patterns. The focal points of these patterns primarily revolve around concurrent operations, parallel processing, throttle control, and operations sensitive to I/O.
While these patterns may not be as ubiquitous as the well-known Gang of Four (GoF) Design Patterns, they hold substantial practical value within distinct scenarios. Acquainting oneself with these patterns during the early stages of design and implementation can yield substantial benefits for services that demand high performance.
It's worth noting that these patterns have been distilled from real-world development experiences and were coined early in the process. It's entirely possible that others have identified similar patterns under different names. If you come across an existing reference, we encourage you to contribute by creating an issue or pull request in this repository.
In the realm of modern computer systems, the adoption of the interrupt mechanism for I/O is a common practice. When a signal is received, it prompts the CPU to momentarily pause its current task and switch to another. Although the execution at the micro-level remains sequential, the exposed execution model appears to be logically parallel. With the presence of multiple CPUs and cores, computer systems inherently support parallel execution, making them well-suited for asynchronous models.
However, this asynchronous model might not align with the intuitive nature of human thinking, which tends to favor sequential operations. Consequently, there is a need for more user-friendly approaches to writing synchronous routines.
The essence of programming lies at the crossroads of computer execution and human comprehension. Over the past six decades, programming languages have undergone a significant transformation, evolving from computer-centric (punched card) to human-centric (assembly, C++, Python). The primary goal of these languages has been to optimize the experience for humans, making code both more readable and writable. Language compilers handle the intricacies of computer-oriented optimization, while each language provides a unique programming model and interfaces with the operating system stacks.
The emphasis on human-friendliness is a hallmark of programming languages, and the concept of sequential operations remains inherently intuitive and easy to express. In the present day, most high-level programming languages are considered "concurrent programming languages" with native support for the sequential model.
Let's illustrate this with a simple example of sequential operations:
1. Make a phone call to R2D2.
2. Ask R2D2 to translate an article (a time-consuming task) and await a response.
3. Print the translation.
4. Make a phone call to 3-PO.
5. Ask 3-PO to translate an article (a time-consuming task) and await a response.
6. Print the translation.
This example is straightforward to write and understand because it aligns with the natural thought processes of humans. While the tasks (the translation processes) run on separate systems (the robots), they are logically parallel to the main logic above. In many cases, this style is preferred because of its undeniable advantage: it's easy for humans to create and comprehend. The pivotal aspect in achieving this lies in converting parallel execution into a blocking operation using "ask and wait." This style is commonly adopted at various levels, from the operating system to libraries and application layers. Notably, many programming languages, including C, Java, and Python, natively support this blocking style.
The drawbacks of sequential operations become evident when we consider the need to harness the parallelism and asynchronous capabilities provided by modern computing systems. Sequential execution often leads to longer processing times. To address this challenge, various technologies have emerged:
-
Threads: Threads exist both at the operating system level and as counterparts in programming languages. Threads allow us to preserve the sequential logic style while enabling parallel operations.
-
Callbacks: Callbacks describe what actions to take upon specific events. Programming language runtimes handle parallel execution and shield developers from many implementation details.
Let's explore parallel execution using both threads and callbacks:
Example of Parallel Execution Using Threads:
Define thread 1:
Make a phone call to R2D2.
Ask R2D2 to translate an article (which takes some time) and await a response.
Print the translation
Define thread 2:
Make a phone call to 3-PO.
Ask 3-PO to translate an article (which takes some time) and await a response.
Print the translation
Run thread 1 and thread 2 in parallel.
Example of Parallel Execution Using Callbacks:
Make a phone call to R2D2.
Ask R2D2 to translate an article (non-blocking). Upon receiving a response, do:
Print the translation
Make a phone call to 3-PO.
Ask 3-PO to translate an article (non-blocking). Upon receiving a response, do:
Print the translation
It's intriguing to observe the progression of programming languages, particularly the emergence of asynchronous patterns as first-class features. Before we delve into this topic, let's revisit the traditional sequential programming model, threading.
Threading has its merits, stemming from the native support provided by the operating system. It excels at describing step-by-step task completion due to its synchronous nature. Sequential operations are inherently easier to articulate and comprehend. However, the sequential model encounters challenges when asynchronous programming takes center stage, thanks to the inherent nature of programming languages. Is there an alternative model that simplifies the description of asynchronous tasks? The ingenious solution came in the form of asynchronous-native languages, such as JavaScript, where nearly everything happens asynchronously by default. The runtime takes charge of handling asynchronous operations at lower levels, such as the operating system and I/O, effectively shielding complexity from programmers. As a result, these languages excel at expressing asynchronous tasks with fluency.
Examples of sequential-native languages include C++, Java, and Python, which naturally excel at describing sequential problems.
On the other hand, asynchronous-native languages, like those in the JavaScript family (including CoffeeScript and TypeScript), excel at articulating parallel routines.
What's fascinating is that neither of these two styles dominates the programming landscape. Sequential-native languages later introduced features to facilitate the description of asynchronous tasks by incorporating concepts like Futures in Java and C#, as well as async and await in C#, and the Rx framework. These features are relatively easy to achieve in asynchronous-native languages like JavaScript, which also introduced await later to enhance the capability of describing sequential operations.
There exist other models and concepts that fundamentally simplify the description of parallelism problems and the achievement of concurrency. Examples include Java Executors, Java Parallel Streaming, Erlang messaging, Go language channels, and Go goroutines. These models and concepts abstract away unnecessary details, making them effective for describing common problems.
However, regardless of how the building blocks evolve, one core problem remains constant for I/O-centric and performance-sensitive services: the identification of heavyweight cross-boundary operations. Leveraging these building blocks to optimize operations through parallelism or batching, reducing the number of calls, ultimately results in shorter execution times, higher throughput, and reduced system costs.
Engineers design based on experience, while architects rely on methodologies.
Identify unrelated operations at the highest level and process them in isolation. This approach solves the core issue in parallel processing and mitigates contention. Architecturally sequential designs offer limited room for optimization at the micro-level.
Software engineering resembles building a castle with various building blocks. The choice of building blocks significantly impacts how you construct the castle. Understanding the characteristics of these building blocks and selecting the appropriate ones is crucial. In many cases, batch operations, provided by the layers you depend on, are designed for optimization and tend to outperform single-resource operations when used correctly.
Operation cascading involves triggering a downstream operation directly upon the completion of an upstream operation. While operation cascading has its advantages and is intuitive, it can lead to issues in complex systems, especially subsystems with varying processing speeds. A significant problem is that the system's throughput can be bottlenecked by the slowest point, making proper scaling challenging.
Conversely, system decoupling breaks the system into multiple stages, allowing each stage to be designed and optimized with a specific scaling target. This results in a more intricate design and implementation compared to operation cascading. Related patterns include producer-consumer, batch stage chain, and mark-and-sweep.
Every system has a scalability limit within its lifecycle. Identifying this limit during the design phase paves the way for building the system.
Fine granular parallel execution based on stages for improved parallelism.
Conventional programming paradigms, including traditional programming languages, functional programming, and object-oriented programming, often encourage developers to write programs as self-contained function units from the outset. This practice is generally suitable for implementing sequential scenarios, where each function unit operates independently.

When parallelism becomes a requirement, the natural inclination is to reuse these existing function units as building blocks and execute them in parallel to enhance speed and performance. This straightforward approach often works well initially, which we can refer to as the "Parallel Sequential Units" pattern.
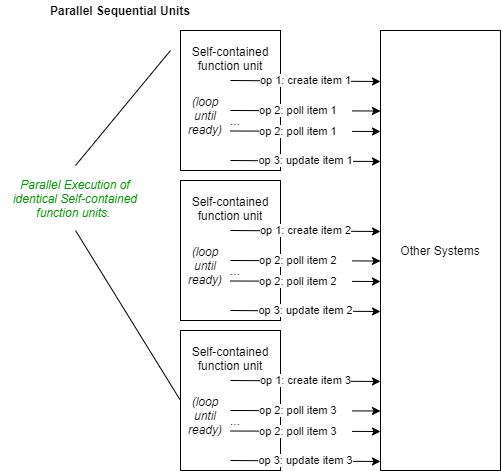
However, when dealing with complex sequences, especially those involving multiple heavyweight operations (e.g., I/O or inter-service calls), running the function units in parallel may not be the most optimal choice for two key reasons:
- More efficient methods for batch I/O or inter-service calls typically exist. Batch operations are usually more effective.
- Heavyweight operations might have inherent concurrency limits or API quota restrictions. Executing the existing units in parallel, all performing essentially the same procedure concurrently, could either exceed the limits (if the parallelism number is high) or underutilize the concurrency capacity (if the parallelism number is low).
The solution to this problem involves breaking down the sequential operation into multiple stages. Heavyweight operations can be managed in a batch fashion or adequately handled within each stage's concurrency. In ideal scenarios, batch operations are optimized at the process level, and concurrency takes place at this stage. The producer-consumer pattern connects these stages in a chain, with the output of one stage serving as the input for the next stage. We can refer to this pattern as the "Batch Stage Chain." In many instances, this pattern outperforms the Parallel Sequential Units pattern in terms of performance, albeit at the cost of a less intuitive implementation.

- As multiple calls of the same operation are grouped together within a stage, each stage can naturally apply optimizations, enabling the possibility of achieving enhanced concurrency and performance.
- The solution may require a less intuitive implementation compared to Parallel Sequential Units.
Aggregate requests and perform them in a batch manner while maintaining a simple interface for callers.
Working with a single resource is typically more straightforward than dealing with multiple resources simultaneously. Single-resource operations are easy to understand, design, and implement, making them inherently more user-friendly. Software systems and libraries often opt for a single-resource operation interface style, such as providing interfaces for getting a single book versus getting multiple books in a bookstore management system.
Due to the layering in software design, this single-resource operation interface style permeates multiple layers and related systems.
In situations like these, when operations on multiple resources become necessary, the existing software layering and interfaces may constrain developers to adhere to the single-resource interface. For example, a third-party cloud service may only expose single-resource operations, which may be beyond our control.
For performance-related scenarios, making concurrent calls using single resource operations is a natural choice. The rationale is akin to the self-contained function unit discussed in the previous section. This approach offers numerous practical advantages and is often the best choice.
However, when even greater performance is required, it can become a labor-intensive task.
For instance, consider the network socket I/O library provided by the operating system. The OS often manages socket presentation and operation as a batch to align with underlying hardware capabilities (e.g., Linux epoll and Windows completion port). Nevertheless, high-level libraries tend to expose interfaces for single-socket operations, like reading from a socket. When it comes to concurrent operations on multiple sockets, many implementations resort to using threads. This approach retains the simplicity of operating a single socket in some sequence for the function unit, but it necessitates optimization at the layers beneath the API or requires meticulous design and implementation to maintain the user-friendly single-resource interface without sacrificing the benefits of batch operations.
The aggregator pattern is designed to preserve the user-friendly single-resource operation interfaces while harnessing batch operations to optimize cross-system calls, especially those involving heavy processing.

The single-resource operation interface remains intact, while batch operations are employed to enhance the efficiency of cross-system heavy calls. With careful design, the number of cross-system calls can be minimized.
Poll states for a large number of items in controlled batches.
When polling a large number of items, polling them all together might not be feasible, and polling them individually is often inefficient. It becomes essential to segment the operation into smaller batches to comply with service requirements, such as batch size limits, response size limits, and API call quotas.
A rolling window concept is used to define the targets to be polled within an array of target items. The size of the window is determined by the target system's requirements or optimization criteria. In each iteration, only the items within the poller window are polled from the target system, ideally in a single batch. The results are cached locally. The poller window moves within the array until it reaches the end. Subsequently, the items in the array are reorganized, either within the array or using separate data structures, so that only the unfinished items remain as the polling targets. The rolling window then continues. This process repeats until all items reach the desired completion state.

This system issues requests to the target system in a controlled manner, respecting the constraints imposed by the target system. This mechanism is particularly effective when items need to be dynamically added or removed during runtime. It can be employed in conjunction with the Request Aggregator to optimize system performance.
Break long-running tasks into multiple transient tasks for scalability.
Distributed tasks, provided by a task scheduler, are commonly used in management systems to achieve reliability, scalability, and responsibility decoupling, particularly in a Shared-nothing Architecture. Applications submit tasks to a task scheduler, which processes them in the background reliably and in a distributed manner. A conventional and intuitive implementation of a long-running task typically follows this sequence:
- Perform some operations.
- Wait for a certain completion, often involving repeated polling from a target service.
- Complete the task as successful, canceled, or in error.
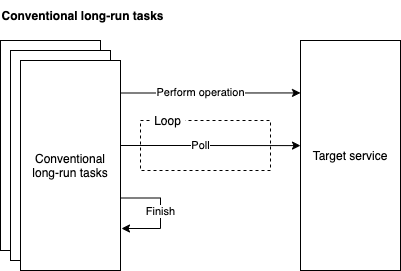
While this long-running style is intuitive in many cases, it has the following drawbacks:
- Each long-running task occupies a worker capacity from the scheduler, usually a thread, limiting task concurrency, even for waiting tasks, thereby limiting system throughput.
- The polling model incurs additional I/O.
- Aggregating inter-system I/O as batches for optimization is challenging, as distributed tasks may run on different nodes in a cluster.
The Sparse Task pattern transforms a long-running task into multiple small, independent pieces, changing the overall structure from a polling model to an event-driven model. The pattern comprises the following components:
- Submitter: Executes the actual task operation and schedules a timeout monitor task on the task scheduler for each task. The Submitter may or may not be a distributed task, depending on the implementation.
- Timeout monitor task: A scheduled task that notifies the event handler if the operation times out. The monitor task is typically a distributed task for reliability, ensuring the task survives service restarts. One of the principles for a reliable task system is to never hold states in a process/thread; states from the persistence layer are the only source of truth.
- Event handler: Manages task completion events. The timeout monitor task is closed upon completion.

This pattern relies on a callback to notify the event handler about task completion. Examples of such callbacks include message bus events, Webhooks, and more. If a messaging infrastructure is absent, a polling mechanism can be used to achieve the callback:

- Scalability increases as the blocking logic per long-running task no longer occupies the task scheduler's capacity. Consequently, more tasks than the number of scheduler worker capacities can logically run in parallel.
- Task implementation is simplified. While the entire task logic should be idempotent for long-running tasks in a high-availability environment, for sparse tasks, each tiny piece must be idempotent, which is typically easier.
- System I/O is reduced by moving from polling to event-driven patterns.
- System dependencies increase. Typically, polling is more straightforward, while callback or messaging requires additional infrastructure.
- A mechanism to identify the monitor task from the event callback context is needed, allowing the task to be closed upon a successful callback. The supporting framework or user typically handles this.
- Tracking the task requires additional consideration since a logical task now consists of two physical tasks.
The Sparse Task pattern depends on a distributed scheduler to monitor task timeouts. One timeout task is associated with one logical long-running task. This model handles each task individually.
Flag and process todo items separately to decouple high-speed and low-speed systems.
In certain systems, triggers or events occur, and specific operations or processing are required upon these triggers, usually targeting a specific object. For example, an event-driven system with a cleanup event to indicate "cleanup needed in room 1." A straightforward approach is to perform the operation in place upon the event, which is suitable in many cases due to its simplicity. However, challenges arise in more complex scenarios, such as:
- The event's peak speed exceeds the processing capabilities of the handling part.
- The target's processing needs to be unique, and reacting to each event leads to unnecessary duplicated operations.
- Event Cascading: The processing may trigger another event, leading to another operation, creating a complex and hard-to-control system as it grows.
The Marker and Sweeper pattern separates the component of the system responsible for requesting changes and the part that handles those changes. It comprises three key elements:
- The marker: Upon request, marks the associated target in a flag set.
- The flag set: A state that maintains a record of targets to be processed.
- The sweeper: Consumes the flag set and processes the targets accordingly.

The Marker and Sweeper pattern bears resemblance to the Producer and Consumer pattern.
- Decouples the requester part and the handler part, allowing them to work at their own pace and be scaled separately.
- The requester part (marker) can operate with high throughput due to the lightweight nature of the flag set.
- The set-based approach of the flag set makes it ideal for deduplication.
- The handler part (sweeper) has the opportunity to process items in a batch manner.
Typical examples of the Marker and Sweeper pattern include the network socket select API and Linux epoll, among others.
Pattern abstraction originates from practical experience and, in turn, finds its application in practice. This iterative process often prompts me to reconsider how we create software. There's no universally superior pattern for every problem, but there should be a well-suited one for each specific context. What guides our designs and patterns are the principles underpinning them, which we've distilled from various real-world practices. It's these principles that we should adhere to. Perhaps, one day in the future, when we reflect on our engineering careers, the only thing that will endure is the Doctrine of the Mean.