[中文主页] | [Docs] | [API] | [DJ-SORA] | [Awesome List]



Data-Juicer is a one-stop multimodal data processing system to make data higher-quality, juicier, and more digestible for LLMs.
We provide a playground with a managed JupyterLab. Try Data-Juicer straight away in your browser! If you find Data-Juicer useful for your research or development, please kindly cite our work.
Platform for AI of Alibaba Cloud (PAI) has cited our work and integrated Data-Juicer into its data processing products. PAI is an AI Native large model and AIGC engineering platform that provides dataset management, computing power management, model tool chain, model development, model training, model deployment, and AI asset management. For documentation on data processing, please refer to: PAI-Data Processing for Large Models.
Data-Juicer is being actively updated and maintained. We will periodically enhance and add more features, data recipes and datasets. We welcome you to join us (via issues, PRs, Slack channel, DingDing group, ...), in promoting data-model co-development along with research and applications of (multimodal) LLMs!
[2024-08-09] We propose Img-Diff, which enhances the performance of multimodal large language models through contrastive data synthesis, achieving a score that is 12 points higher than GPT-4V on the MMVP benchmark. See more details in our paper, and download the dataset from huggingface and modelscope.

History News:
>- [2024-03-07] We release Data-Juicer v0.2.0 now! In this new version, we support more features for multimodal data (including video now), and introduce DJ-SORA to provide open large-scale, high-quality datasets for SORA-like models.
- [2024-02-20] We have actively maintained an awesome list of LLM-Data, welcome to visit and contribute!
- [2024-02-05] Our paper has been accepted by SIGMOD'24 industrial track!
- [2024-01-10] Discover new horizons in "Data Mixture"—Our second data-centric LLM competition has kicked off! Please visit the competition's official website for more information.
- [2024-01-05] We release Data-Juicer v0.1.3 now! In this new version, we support more Python versions (3.8-3.10), and support multimodal dataset converting/processing (Including texts, images, and audios. More modalities will be supported in the future). Besides, our paper is also updated to v3.
- [2023-10-13] Our first data-centric LLM competition begins! Please visit the competition's official websites, FT-Data Ranker (1B Track, 7B Track), for more information.
- Data-Juicer: A One-Stop Data Processing System for Large Language Models
- Table of Contents

-
Systematic & Reusable: Empowering users with a systematic library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific multimodal LLM datasets and processing pipelines.
-
Data-in-the-loop & Sandbox: Supporting one-stop data-model collaborative development, enabling rapid iteration through the sandbox laboratory, and providing features such as feedback loops based on data and model, visualization, and multidimensional automatic evaluation, so that you can better understand and improve your data and models.
-
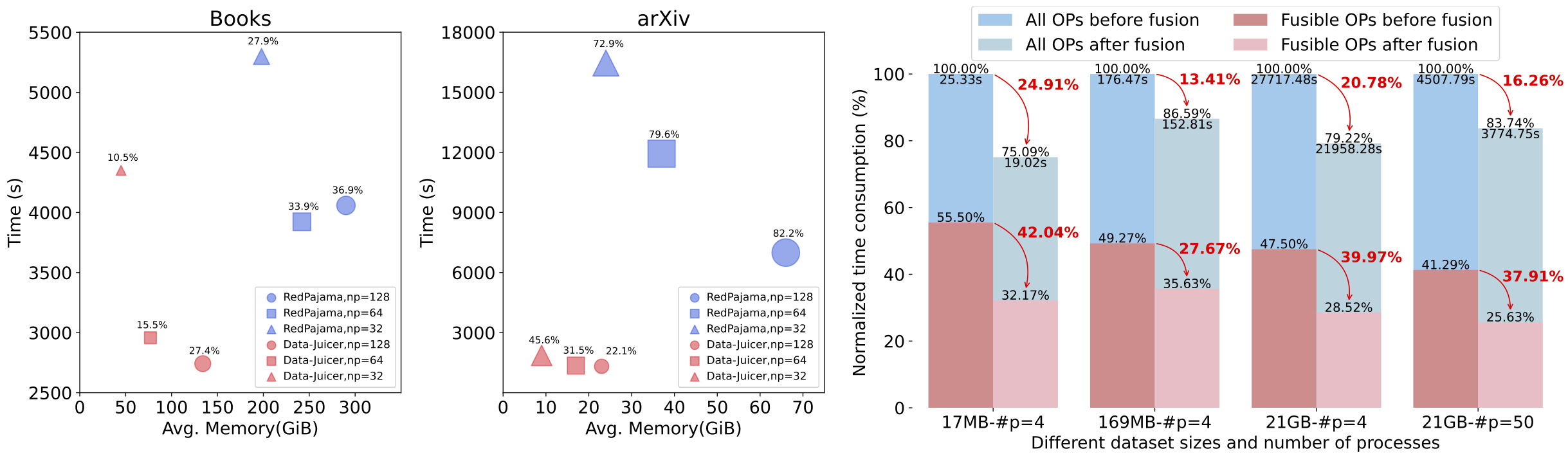
Towards production environment: Providing efficient and parallel data processing pipelines (Aliyun-PAI\Ray\Slurm\CUDA\OP Fusion) requiring less memory and CPU usage, optimized with automatic fault-toleration.
-
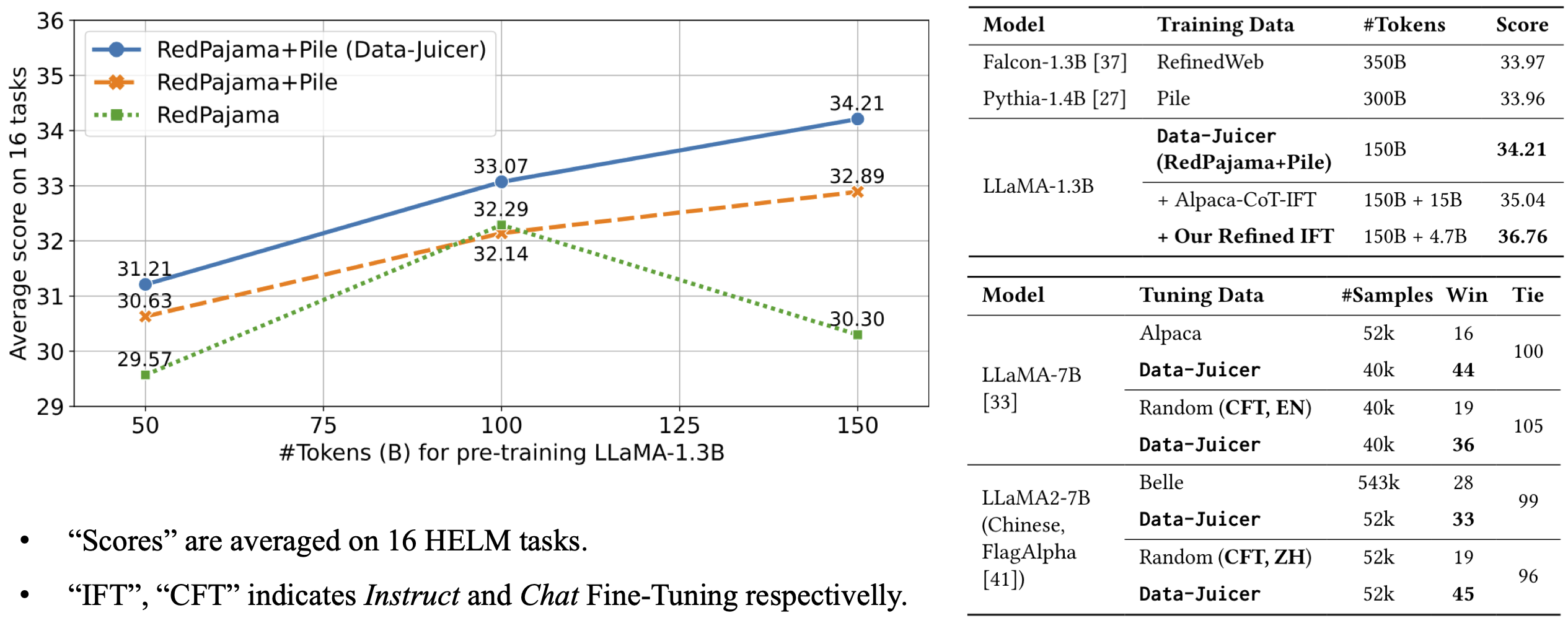
Comprehensive Data Processing Recipes: Offering tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. Validated on reference LLaMA and LLaVA models.
-
Flexible & Extensible: Accommodating most types of data formats (e.g., jsonl, parquet, csv, ...) and allowing flexible combinations of OPs. Feel free to implement your own OPs for customizable data processing.
-
User-Friendly Experience: Designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.
- Overview
- Operator Zoo
- Configs
- Developer Guide
- API references
- KDD-Tutorial
- "Bad" Data Exhibition
- Awesome LLM-Data
- Dedicated Toolkits
- DJ-SORA
- Third-parties (LLM Ecosystems)
- Introduction to Data-Juicer [ModelScope] [HuggingFace]
- Data Visualization:
- Basic Statistics [ModelScope] [HuggingFace]
- Lexical Diversity [ModelScope] [HuggingFace]
- Operator Insight (Single OP) [ModelScope] [HuggingFace]
- Operator Effect (Multiple OPs) [ModelScope] [HuggingFace]
- Data Processing:
- Scientific Literature (e.g. arXiv) [ModelScope] [HuggingFace]
- Programming Code (e.g. TheStack) [ModelScope] [HuggingFace]
- Chinese Instruction Data (e.g. Alpaca-CoT) [ModelScope] [HuggingFace]
- Tool Pool:
- Dataset Splitting by Language [ModelScope] [HuggingFace]
- Quality Classifier for CommonCrawl [ModelScope] [HuggingFace]
- Auto Evaluation on HELM [ModelScope] [HuggingFace]
- Data Sampling and Mixture [ModelScope] [HuggingFace]
- Data Processing Loop [ModelScope] [HuggingFace]
- Recommend Python>=3.9,<=3.10
- gcc >= 5 (at least C++14 support)
- Run the following commands to install the latest basic
data_juicerversion in editable mode:
cd <path_to_data_juicer>
pip install -v -e .- Some OPs rely on some other too large or low-platform-compatibility third-party libraries. You can install optional dependencies as needed:
cd <path_to_data_juicer>
pip install -v -e . # install a minimal dependencies, which support the basic functions
pip install -v -e .[tools] # install a subset of tools dependenciesThe dependency options are listed below:
| Tag | Description |
|---|---|
. or .[mini] |
Install minimal dependencies for basic Data-Juicer. |
.[all] |
Install all dependencies except sandbox. |
.[sci] |
Install all dependencies for all OPs. |
.[dist] |
Install dependencies for distributed data processing. (Experimental) |
.[dev] |
Install dependencies for developing the package as contributors. |
.[tools] |
Install dependencies for dedicated tools, such as quality classifiers. |
.[sandbox] |
Install all dependencies for sandbox. |
- Install dependencies for specific OPs
With the growth of the number of OPs, the dependencies of all OPs becomes very heavy. Instead of using the command pip install -v -e .[sci] to install all dependencies,
we provide two alternative, lighter options:
-
Automatic Minimal Dependency Installation: During the execution of Data-Juicer, minimal dependencies will be automatically installed. This allows for immediate execution, but may potentially lead to dependency conflicts.
-
Manual Minimal Dependency Installation: To manually install minimal dependencies tailored to a specific execution configuration, run the following command:
# only for installation from source python tools/dj_install.py --config path_to_your_data-juicer_config_file # use command line tool dj-install --config path_to_your_data-juicer_config_file
- Run the following command to install the latest released
data_juicerusingpip:
pip install py-data-juicer- Note:
- only the basic APIs in
data_juicerand two basic tools (data processing and analysis) are available in this way. If you want customizable and complete functions, we recommend you installdata_juicerfrom source. - The release versions from pypi have a certain lag compared to the latest version from source.
So if you want to follow the latest functions of
data_juicer, we recommend you install from source.
- only the basic APIs in
- You can
-
either pull our pre-built image from DockerHub:
docker pull datajuicer/data-juicer:<version_tag>
-
or run the following command to build the docker image including the latest
data-juicerwith provided Dockerfile:docker build -t datajuicer/data-juicer:<version_tag> .
-
The format of
<version_tag>is likev0.2.0, which is the same as release version tag.
-
import data_juicer as dj
print(dj.__version__)Before using video-related operators, FFmpeg should be installed and accessible via the $PATH environment variable.
You can install FFmpeg using package managers(e.g. sudo apt install ffmpeg on Debian/Ubuntu, brew install ffmpeg on OS X) or visit the official ffmpeg link.
Check if your environment path is set correctly by running the ffmpeg command from the terminal.
- Run
process_data.pytool ordj-processcommand line tool with your config as the argument to process your dataset.
# only for installation from source
python tools/process_data.py --config configs/demo/process.yaml
# use command line tool
dj-process --config configs/demo/process.yaml-
Note: For some operators that involve third-party models or resources which are not stored locally on your computer, it might be slow for the first running because these ops need to download corresponding resources into a directory first. The default download cache directory is
~/.cache/data_juicer. Change the cache location by setting the shell environment variable,DATA_JUICER_CACHE_HOMEto another directory, and you can also changeDATA_JUICER_MODELS_CACHEorDATA_JUICER_ASSETS_CACHEin the same way: -
Note: When using operators with third-party models, it's necessary to declare the corresponding
mem_requiredin the configuration file (you can refer to the settings in theconfig_all.yamlfile). During runtime, Data-Juicer will control the number of processes based on memory availability and the memory requirements of the operator models to achieve better data processing efficiency. When running with CUDA environment, if the mem_required for an operator is not declared correctly, it could potentially lead to a CUDA Out of Memory issue.
# cache home
export DATA_JUICER_CACHE_HOME="/path/to/another/directory"
# cache models
export DATA_JUICER_MODELS_CACHE="/path/to/another/directory/models"
# cache assets
export DATA_JUICER_ASSETS_CACHE="/path/to/another/directory/assets"We provide various simple interfaces for users to choose from as follows.
#... init op & dataset ...
# Chain call style, support single operator or operator list
dataset = dataset.process(op)
dataset = dataset.process([op1, op2])
# Functional programming style for quick integration or script prototype iteration
dataset = op(dataset)
dataset = op.run(dataset)We have now implemented multi-machine distributed data processing based on RAY. The corresponding demos can be run using the following commands:
# Run text data processing
python tools/process_data.py --config ./demos/process_on_ray/configs/demo.yaml
# Run video data processing
python tools/process_data.py --config ./demos/process_video_on_ray/configs/demo.yaml- To run data processing across multiple machines, it is necessary to ensure that all distributed nodes can access the corresponding data paths (for example, by mounting the respective data paths on a file-sharing system such as NAS).
- The deduplicator operators for RAY mode are different from the single-machine version, and all those operators are prefixed with
ray, e.g.ray_video_deduplicatorandray_document_deduplicator. Those operators also rely on a Redis instance. So in addition to starting the RAY cluster, you also need to setup your Redis instance in advance and providehostandportof your Redis instance in configuration.
Users can also opt not to use RAY and instead split the dataset to run on a cluster with Slurm. In this case, please use the default Data-Juicer without RAY. Aliyun PAI-DLC supports the RAY framework, Slurm framework, etc. Users can directly create RAY jobs and Slurm jobs on the DLC cluster.
- Run
analyze_data.pytool ordj-analyzecommand line tool with your config as the argument to analyze your dataset.
# only for installation from source
python tools/analyze_data.py --config configs/demo/analyzer.yaml
# use command line tool
dj-analyze --config configs/demo/analyzer.yaml- Note: Analyzer only compute stats of Filter ops. So extra Mapper or Deduplicator ops will be ignored in the analysis process.
- Run
app.pytool to visualize your dataset in your browser. - Note: only available for installation from source.
streamlit run app.py- Config files specify some global arguments, and an operator list for the
data process. You need to set:
- Global arguments: input/output dataset path, number of workers, etc.
- Operator list: list operators with their arguments used to process the dataset.
- You can build up your own config files by:
- ➖:Modify from our example config file
config_all.yamlwhich includes all ops and default arguments. You just need to remove ops that you won't use and refine some arguments of ops. - ➕:Build up your own config files from scratch. You can refer our
example config file
config_all.yaml, op documents, and advanced Build-Up Guide for developers. - Besides the yaml files, you also have the flexibility to specify just one (of several) parameters on the command line, which will override the values in yaml files.
- ➖:Modify from our example config file
python xxx.py --config configs/demo/process.yaml --language_id_score_filter.lang=en-
The basic config format and definition is shown below.

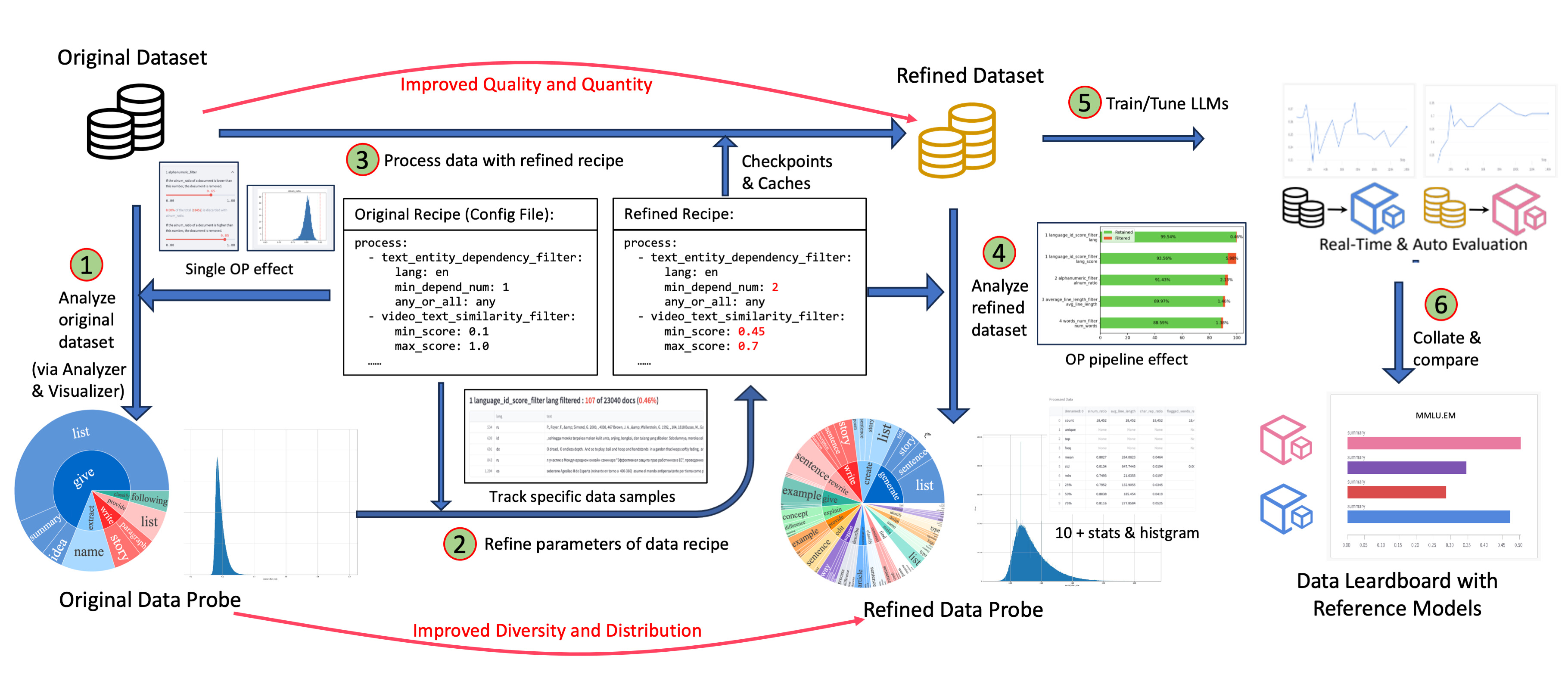
The data sandbox laboratory (DJ-Sandbox) provides users with the best practices for continuously producing data recipes. It features low overhead, portability, and guidance.
- In the sandbox, users can quickly experiment, iterate, and refine data recipes based on small-scale datasets and models, before scaling up to produce high-quality data to serve large-scale models.
- In addition to the basic data optimization and recipe refinement features offered by Data-Juicer, users can seamlessly use configurable components such as data probe and analysis, model training and evaluation, and data and model feedback-based recipe refinement to form a complete one-stop data-model research and development pipeline.
The sandbox is run using the following commands by default, and for more information and details, please refer to the sandbox documentation.
python tools/sandbox_starter.py --config configs/demo/sandbox/sandbox.yaml- Our formatters support some common input dataset formats for now:
- Multi-sample in one file: jsonl/json, parquet, csv/tsv, etc.
- Single-sample in one file: txt, code, docx, pdf, etc.
- However, data from different sources are complicated and diverse. Such as:
- Raw arXiv data downloaded from S3 include thousands of tar files and even more gzip files in them, and expected tex files are embedded in the gzip files so they are hard to obtain directly.
- Some crawled data include different kinds of files (pdf, html, docx, etc.). And extra information like tables, charts, and so on is hard to extract.
- It's impossible to handle all kinds of data in Data-Juicer, issues/PRs are welcome to contribute to process new data types!
- Thus, we provide some common preprocessing tools in
tools/preprocessfor you to preprocess these data.- You are welcome to make your contributions to new preprocessing tools for the community.
- We highly recommend that complicated data can be preprocessed to jsonl or parquet files.
- If you build or pull the docker image of
data-juicer, you can run the commands or tools mentioned above using this docker image. - Run directly:
# run the data processing directly
docker run --rm \ # remove container after the processing
--privileged \
--shm-size 256g \
--network host \
--gpus all \
--name dj \ # name of the container
-v <host_data_path>:<image_data_path> \ # mount data or config directory into the container
-v ~/.cache/:/root/.cache/ \ # mount the cache directory into the container to reuse caches and models (recommended)
datajuicer/data-juicer:<version_tag> \ # image to run
dj-process --config /path/to/config.yaml # similar data processing commands- Or enter into the running container and run commands in editable mode:
# start the container
docker run -dit \ # run the container in the background
--privileged \
--shm-size 256g \
--network host \
--gpus all \
--rm \
--name dj \
-v <host_data_path>:<image_data_path> \
-v ~/.cache/:/root/.cache/ \
datajuicer/data-juicer:latest /bin/bash
# enter into this container and then you can use data-juicer in editable mode
docker exec -it <container_id> bash- Recipes for data process in BLOOM
- Recipes for data process in RedPajama
- Refined recipes for pre-training text data
- Refined recipes for fine-tuning text data
- Refined recipes for pre-training multi-modal data
Data-Juicer is released under Apache License 2.0.
We are in a rapidly developing field and greatly welcome contributions of new features, bug fixes and better documentations. Please refer to How-to Guide for Developers.
If you have any questions, please join our discussion groups.
Data-Juicer is used across various LLM products and research initiatives, including industrial LLMs from Alibaba Cloud's Tongyi, such as Dianjin for financial analysis, and Zhiwen for reading assistant, as well as the Alibaba Cloud's platform for AI (PAI). We look forward to more of your experience, suggestions and discussions for collaboration!
Data-Juicer thanks and refers to several community projects, such as Huggingface-Datasets, Bloom, RedPajama, Pile, Alpaca-Cot, Megatron-LM, DeepSpeed, Arrow, Ray, Beam, LM-Harness, HELM, ....
If you find our work useful for your research or development, please kindly cite the following paper.
@inproceedings{chen2024datajuicer,
title={Data-Juicer: A One-Stop Data Processing System for Large Language Models},
author={Daoyuan Chen and Yilun Huang and Zhijian Ma and Hesen Chen and Xuchen Pan and Ce Ge and Dawei Gao and Yuexiang Xie and Zhaoyang Liu and Jinyang Gao and Yaliang Li and Bolin Ding and Jingren Zhou},
booktitle={International Conference on Management of Data},
year={2024}
}