Water Level prediction from RainFall Data
Version: 0.0.3
Author : Md. Nazmuddoha Ansary
- Python == 3.6.8
- Keras==2.3.1
- numpy==1.17.3
- pandas==0.25.2
- Create a Virtualenv
- pip3 install -r requirements.txt
NOTE: tensorflow is used as backend
The dataset comprises of three parts:
- RainFall data:
- Recorded Daily
- Starting Date: 01-01-07
- End Date : 31-12-15
- Lat Info : 22.875 to 25.875 with increase of 0.25
- Lon Info : 88.875 to 94.875 with increase of 0.25
- Total Data Points: 325 locations
- Basin : Meghna
- Zone : Borak
- Water Level data:
- Recorded Daily
- Starting Date: 01-01-10
- End Date : 31-12-14
- Outlet: Bhairab Bazar
- Shape File for ROI

ROI- {lat}_{lon}
['25.125_93.375', '25.125_93.625', '23.625_92.875', '23.875_92.875', '23.875_93.125',
'23.875_93.375', '24.125_93.125', '24.375_93.125', '24.625_93.125', '24.875_93.875',
'23.375_92.625', '23.625_92.625', '23.875_92.375', '23.875_92.625', '24.125_92.625',
'24.125_92.875', '24.375_92.875', '25.375_93.875', '24.625_93.625', '24.875_93.625',
'24.375_92.625', '24.625_92.625', '24.625_92.875', '24.875_92.625', '24.875_92.875',
'24.875_93.125', '25.125_93.125', '24.625_93.375', '24.875_93.375', '24.625_93.875',
'25.375_93.625', '25.375_94.125', '24.375_93.375', '24.125_93.375', '24.375_93.625',
'25.125_92.875', '25.125_93.875']
NOTES:
- Prediction period in the future is tuned by: pred_len in config.json (default=1 day)
- The input sequence comprises of both water level data and rainfall data with seq_len in config.json (default=7 days)
- From the 5 Years of mergeable data available (2010,2011,2012,2013,2014): 2014 is taken as test data and 2010-2013 is taken as train data
- Maximum Rainfall is recorded to be : ~ 585 mm (Taken as int for normalization ease)
- Maximum WaterLevel is recorded to be : ~ 20 m (Taken as int for normalization ease)
-
Change The following Values in config.json
"ARGS": { "SHP_FILE" : "/home/ansary/RESEARCH/RainFall/Data/Borak/Borak.shp", "WATER_LEVEL_CSV" : "/home/ansary/RESEARCH/RainFall/Data/Raw/waterlevel.csv", "RAINFALL_CSV" : "/home/ansary/RESEARCH/RainFall/Data/Raw/rainfall.csv", "OUTPUT_DIR" : "/home/ansary/RESEARCH/RainFall/Data/" } -
Run main.py
version: 0.0.2
usage: main.py [-h] model_type
WaterLevel Data Prediction From RainFall Data
positional arguments:
model_type name of the LSTM model to be USED. Available: StackedLSTM
optional arguments:
-h, --help show this help message and exit
-
If execution is successful a folder called h5s should be created with the following folder tree:
h5s ├── X_Eval.h5 ├── X_Train.h5 ├── Y_Eval.h5 └── Y_Train.h5 -
After Complete Training and Testing a folder named {MODELNAME}_MAX_FEATs:{maximum_features_to_be_extracted}_EPOCHS:{num_of_training_epochs} (which is considered as identifier for a certain setting) will be created in the OUTPUT_DIR which will contain the following folder tree:
identifier ├── arch.png ├── loss.png ├── model.h5 └── test.png
NOTE
- An Example idenditier looks like: StackedLSTM_MAX_FEATs:64_EPOCHS:500
Model Name= StackedLSTM, Max Feats = 64, Epochs = 500
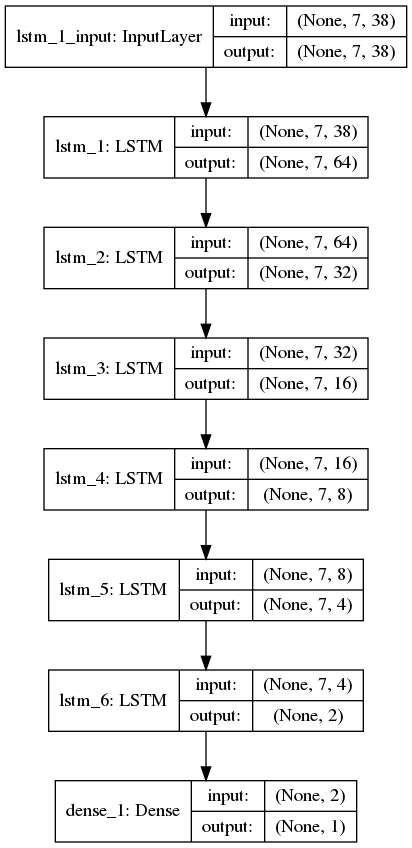
- arch.png plots the model structre
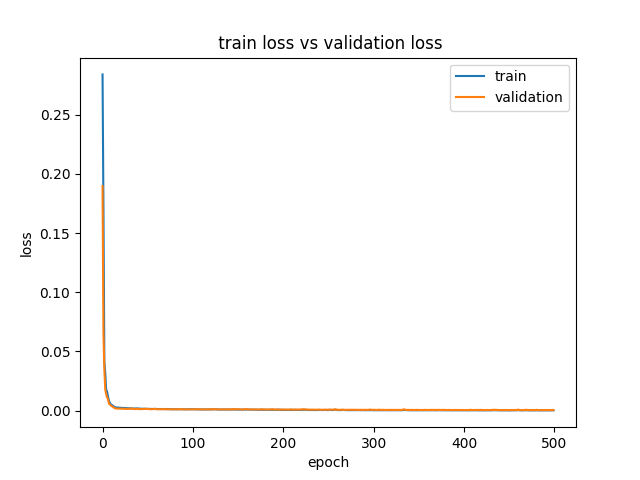
- loss.png plots training history (overfit/ underfit identification)
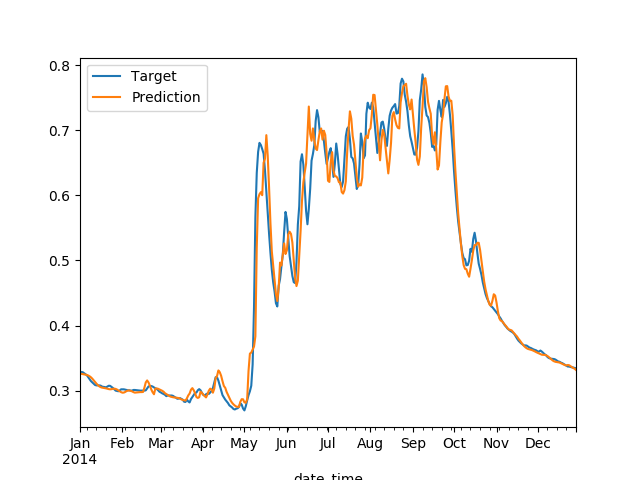
- test.png plots the test data and prediction
- model.h5 is the model_weight file for deployment
- Stacked LSTM
- Bidirectional LSTM
To Be Added in version 0.0.5
- CNN LSTM
To Be Added in version 0.0.6
- ConvLSTM
To Be Added in version 0.0.7
The implemented Model Structre is as follows:
- NUMBER OF TRAINING EPOCHS: 500
- BATCH SIZE: 128
- MAXIMUM FEATURE TAKEN AT ANY LAYER: 64
- R2 SCORE: 0.9654419438558642
- Mean Absolute Error : 0.1374554411601445
The training loss history and prediction with target plot is as follows:
ENVIRONMENT
OS : Ubuntu 18.04.3 LTS (64-bit) Bionic Beaver
Memory : 7.7 GiB
Processor : Intel® Core™ i5-8250U CPU @ 1.60GHz × 8
Graphics : Intel® UHD Graphics 620 (Kabylake GT2)
Gnome : 3.28.2