You can find here a small tokenization utility and examples of table extraction from images using Google Vision API. Google provides a good OCR to extract text from images but the output is not the best sometimes, in this repository I provide a simple postprocessing of the output in order to make it easier to use the API output.
Google OCR provides a text output which might not have the expected format, if that's the case it also provides a JSON output with information about the position of each recognized entity. The problem is that this data is not so well structured for some tasks, extracting tokens (Series of characters without spaces between each other) is not so easy with this JSON since it doesn't provides directly this information. The goal of this is to provide a way to postprocess this data into something more maneagable, so it's more appropiate for text processing tasks like extracting full lines of text or filtering words.
In order to do this a postprocessing code is provided at image2tokens.py. This is applied in order to extract tokens and then even more abstract concepts like text lines or table columns.
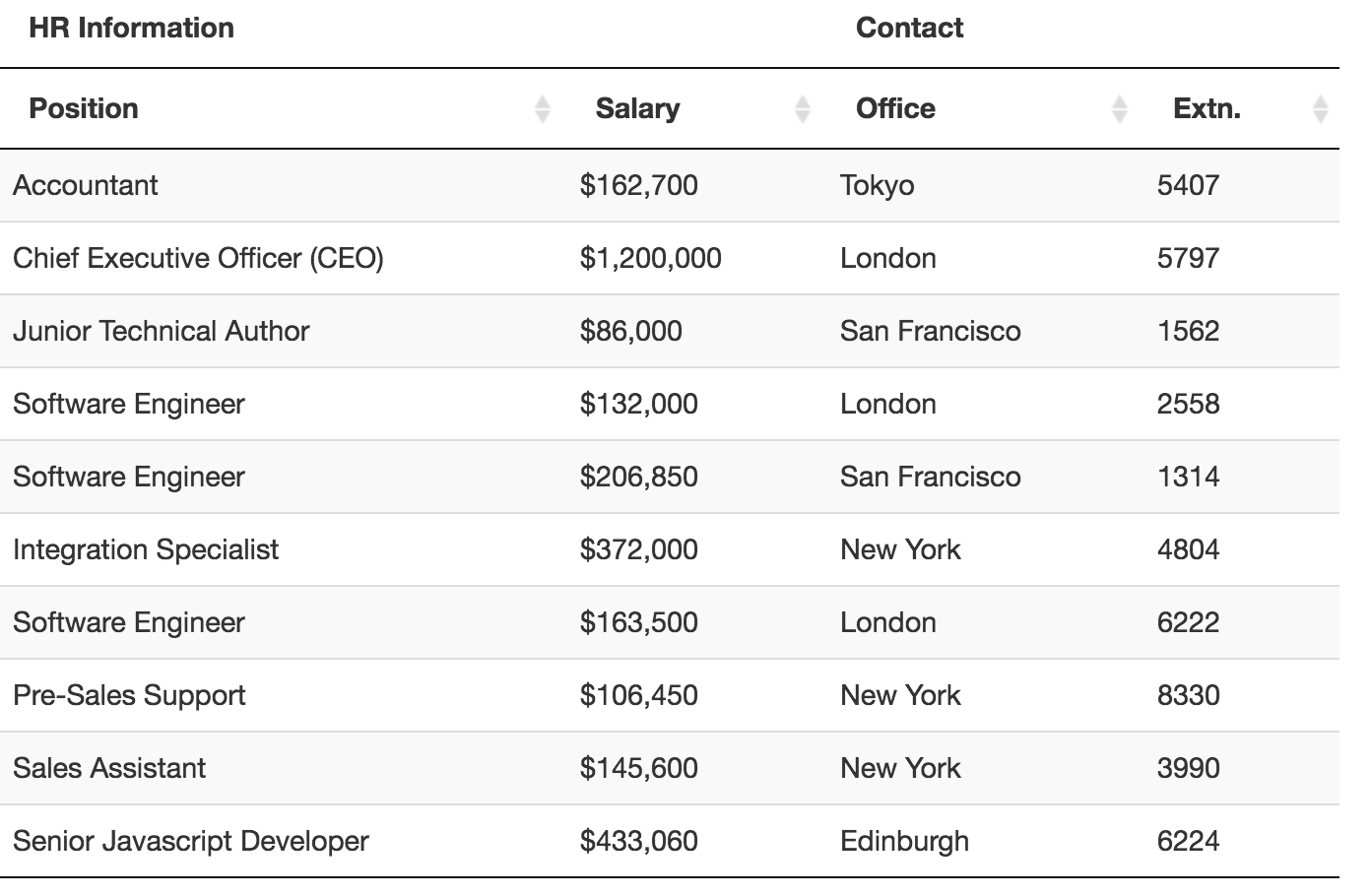
HR Information Contact
Position Salary Office Extn.
Accountant $162,700 Tokyo 5407
Chief Executive Officer (CEO) $1,200,000 London 5797
Junior Technical Author $86,000 San Francisco 1562
Software Engineer $132,000 London 2558
Software Engineer $206,850 San Francisco 1314
Integration Specialist $372,000 New York 4804
Software Engineer $163,500 London 6222
Pre-Sales Support $106,450 New York 8330
Sales Assistant $145,600 New York 3990
Senior Javascript Developer $433,060 Edinburgh 6224
- python 3
- python libraries (Try something like:
pip install -r requirements.txt)
On the src folder there is an usage example at table_example.py, where the tokenization is used to parse the image of a table.
python table_example.py sample/input/sample.png
Note: For this to work you need to load your google credentials. You just need to replace credential.json with your service account key file. Check this link for more details.
Here is a list of similar products that you might try too
- https://aws.amazon.com/es/textract/
- https://tabula.technology/ (Extracts tables from text PDFs, not images)