Reproducing Jeff Preshing's this is why they call it a weakly ordered CPU in Rust for fun, on an M1 (Pro).
Contents of the original below, minus the pictures, eventually adapted
for Rust. Aside from adaptations to the text (original content struck
out), and styllistic adaptations to Rust's coding conventions
(WHICH_WRITES_GLOBALS_LIKE_THIS), my notes are in footnotes.
The tone has been left in first-person, even though for pretty much all of the article it's really Jeff Preshing doing most of the talking.
On this blog, I’ve been rambling on about lock-free programming subjects such as acquire and release semantics and weakly-ordered CPUs. I've tried to make these subjects approachable and understandable, but at the end of the day, talk is cheap! Nothing drives the point home better than a concrete example.
If there’s one thing that characterizes a weakly-ordered CPU, it’s
that one CPU core can see values change in shared memory in a
different order than another core wrote them. That’s what I’d like to
demonstrate in this post using pure C++11 Rust.
For normal applications, the x86/64 processor families from Intel and
AMD do not have this characteristic. So we can forget about
demonstrating this phenomenon on pretty much every most modern
desktop or notebook computer in the world. What we really need is a
weakly-ordered multicore device. Fortunately, I happen to have one
right here in my pocket on my desk:

The iPhone 4S 2021 16" Macbook Pro fits the bill. It runs on a
dual 8+2-core ARM-based processor, and the ARM architecture
is, in fact, weakly-ordered.
Our experiment will consist of an single integer, SHARED_VALUE,
protected by a mutex. We’ll spawn two threads, and each thread will
run until it has incremented SHARED_VALUE 10000000 times.
We won’t let our threads block waiting on the mutex. Instead, each
thread will loop repeatedly doing busy work (ie. just wasting CPU
time) and attempting to lock the mutex at random moments. If the lock
succeeds, the thread will increment SHARED_VALUE, then unlock. If
the lock fails, it will just go back to doing busy work. Here’s some
pseudocode1:
count = 0
while count < 10_000_000:
do_random_amount_of_busy_work()
if try_lock_mutex():
// The lock succeeded
SHARED_VALUE += 1
unlock_mutex()
count += 1With each thread running on a separate CPU core, the timeline should look something like this. Each red section represents a successful lock and increment, while the dark blue ticks represent lock attempts which failed because the other thread was already holding the mutex.
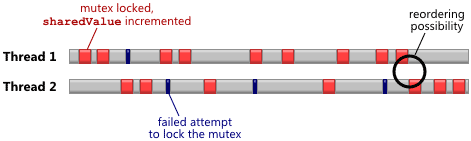
It bears repeating that a mutex is just a
concept,
and there are many ways to implement one. We could use the
implementation provided by std::mutexstd::sync::Mutex, and of
course, everything will function correctly. But then I’d have nothing
to show you. Instead, let’s implement a custom mutex — then let’s
break it to demonstrate the consequences of weak hardware
ordering. Intuitively, the potential for memory
reordering will be highest at those moments when there is a “close
shave” between threads – for example, at the moment circled in the
above diagram, when one thread acquires the lock just as the other
thread releases it.
The latest version of Xcode has terrific support for C++11 threads and
atomic types, so let’s use those. All C++11 identifiers are defined in
the std namespace, so let’s assume using namespace std; was placed
somewhere earlier in the code.
Our mutex will consist of a single integer boolean FLAG, where
true indicates that the mutex is held, and false means it
isn’t. To ensure mutual exclusivity, a thread can only set FLAG to
true if the previous value was false, and it must do so
atomically. To achieve this, we’ll define flag as a C++11 atomic
type, Rust atomic type, atomic<int>AtomicBool, and use a
read-modify-write operation:
if FLAG
.compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed)
.is_ok() {
// The lock succeeded
}The memory_order_acquireOrdering::Acquire argument used above
is considered an ordering constraint. We’re placing acquire
semantics on the operation, to help guarantee that we receive the
latest shared values from the previous thread which held the lock.
To release the lock, we perform the following:
FLAG.store(false, Ordering::Release);This sets FLAG back to false using the memory_order_releaseOrdering::Release ordering constraint, which applies release
semantics. Acquire and release semantics must be used as a pair to
ensure that shared values propagate completely from one thread to the
next.
Now, let’s write the experiment in C++11 Rust, but instead of
specifying the correct ordering constraints, let’s put
memory_order_relaxedOrdering::Relaxed in both places. This
means no particular memory ordering will be enforced by the C++11
Rust compiler, and any kind of reordering is permitted.
fn increment_shared_value {
let mut count = 0usize;
while count < 10_000_000 {
do_busy_work();
if FLAG.compare_exchange(false, true, Relaxed, Relaxed).is_ok() {
// Lock was successful
unsafe {SHARED_VALUE += 1;}
FLAG.store(false, Relaxed);
count += 1;
}
}
}At this point, it’s informative to look at the resulting ARM assembly
code generated by the compiler, in Release, using the Disassembly
view in Xcode cargo asm crate::increment_shared_value:
;; FLAG.compare_exchange(
mov w8, #0
casb w8, w20, [x22]
;; )
cmp w8, #0
b.ne LBB37_1
;; SHARED_VALUE += 1
ldr w8, [x22, #4]
add w8, w8, #1
str w8, [x22, #4]
;; FLAG.store(false)
strb wzr, [x22]If you aren’t very familiar with assembly language, don’t
worry2. All we want to know is whether the compiler has
reordered any operations on shared variables. This would include the
two operations on FLAG, and the increment of SHARED_VALUE in
between. Above, I’ve annotated the corresponding sections of assembly
code. As you can see, we got lucky: the compiler chose not to reorder
those operations, even though the memory_order_relaxedOrdering::Relaxed argument means that, in all fairness, it could
have3.
I’ve put together a sample application which repeats this experiment
indefinitely, printing the final value of SHARED_VALUE at the end of
each trial run. It’s available on GitHub if you’d like
to view the source code or run it yourself4.
And here’s the output from the Output panel in Xcode in a
terminal:
shared value = 19986277
shared value = 19986728
shared value = 19986589
shared value = 19985949
shared value = 19987019
shared value = 19986667
shared value = 19986352
Check it out! The final value of SHARED_VALUE is consistently less
than 20000000, even though both threads perform exactly 10000000
increments, and the order of assembly instructions exactly matches the
order of operations on shared variables as specified in C++ Rust.
As you might have guessed, these results are entirely due to memory
reordering on the CPU. To point out just one possible reordering – and
there are several – the memory interaction of str.w r0, [r11]str w8, [x22, #4] (the store to SHARED_VALUE) could be reordered
with that of str r5, [r6]strb wzr, [x22] (the store of
false to FLAG). In other words, the mutex could be effectively
unlocked before we’re finished with it! As a result, the other thread
would be free to wipe out the change made by this one, resulting in a
mismatched SHARED_VALUE count at the end of the experiment, just as
we’re seeing here.
Fixing our sample application, of course, means putting the correct
C++11 memory ordering constraints back in place:
fn increment_shared_value {
let mut count = 0usize;
while count < 10_000_000 {
do_busy_work();
if FLAG.compare_exchange(false, true, Acquire, Relaxed).is_ok() {
// Lock was successful
unsafe {SHARED_VALUE += 1;}
FLAG.store(false, Release);
count += 1;
}
}
}As a result, the compiler now inserts a couple of dmb ish
instructions, which act as memory barriers in the ARMv7 instruction
set. I’m not an ARM expert – comments are welcome – but it’s safe to
assume this instruction, much like lwsync on PowerPC, provides all
the [memory barrier types][source control analoty] needed for acquire
semantics on compare_exchange, and release semantics on store.
As a result, the compiler now uses casab and stlrb, which have
acquire and release semantics 5.
mov w8, #0
;; Compare-And-Swap, Acquire, Byte
casab w8, w20, [x22]
cmp w8, #0
b.ne LBB37_1
ldr w8, [x22, #4]
add w8, w8, #1
str w8, [x22, #4]
;; STore, reLease, Register, Byte
stlrb wzr, [x22]This time, our little home-grown mutex really does protect
SHARED_VALUE, ensuring all modifications are passed safely from one
thread to the next each time the mutex is locked.
shared value = 20000000
shared value = 20000000
shared value = 20000000
shared value = 20000000
shared value = 20000000
shared value = 20000000
If you still don’t grasp intuitively what’s going on in this
experiment, I’d suggest a review of my source control analogy
post6. In terms of that analogy, you can imagine two workstations
each having local copies of SHARED_VALUE and FLAG, with some
effort required to keep them in sync. Personally, I find visualizing
it this way very helpful.
I’d just like to reiterate that the memory reordering we saw here can
only be observed on a multicore or multiprocessor
device7. If you take the same compiled application and run it on
an iPhone 3GS or first-generation iPad8, which use the same ARMv7
architecture but have only a single CPU core, you won’t see any
mismatch in the final count of SHARED_VALUE.
You can build and run this sample application on any Windows, MacOS or Linux machine with a x86/64 CPU, but unless your compiler performs reordering on specific instructions, you won’t witness any memory reordering at runtime – even on a multicore system! Indeed, when I tested it using Visual Studio 2012, no memory reordering occurred. That’s because x86/64 processors are what is usually considered strongly-ordered: when one CPU core performs a sequence of writes, every other CPU core sees those values change in the same order that they were written.
This goes to show how easy it is to use C++11 Rust atomics
incorrectly without knowing it9, simply because it appears
to work correctly on a specific processor and toolchain.
Replaces the final section about outdated Visual Studio version with cross-compiling and running (via Rosetta) under x86/64:
> rustup target add x86_64-apple-darwin
> cargo r --release --target=x86_64-apple-darwinDespite this using the incorrect ordering (Relaxed), as noted
initially the results are still "correct":
shared value = 20000000
shared value = 20000000
shared value = 20000000
shared value = 20000000
shared value = 20000000
That is because in x86(/64) very few operations can be reordered10, and thus here:
xor eax, eax
;; set FLAG (atomically)
lock cmpxchg byte ptr [rip + __ZN14weakly_ordered4FLAG17hf6b97f5e9423a14bE], r15b
jne LBB36_2
;; increment SHARED_VALUE
inc dword ptr [rip + __ZN14weakly_ordered12SHARED_VALUE17ha04c2bdb9f06cda3E]
;; reset FLAG
mov byte ptr [rip + __ZN14weakly_ordered4FLAG17hf6b97f5e9423a14bE], 0the stores to SHARED_VALUE and FLAG can not be reordered, thus
SHARED_VALUE is necessarily incremented only when "holding the
lock"11.
Because the compiler is aware of that property, there is no difference between the "relaxed" and "acquire/release" versions of the program.
Footnotes
-
#pythonismypseudocode ↩
-
I'm not either, and /u/torne kindly helped me understand what was happening ↩
-
It makes sense though, because the LLVM documentation notes that while "it is legal to reorder non-atomic and Unordered loads around Monotonic loads", "Monotonic operations are unlikely to be used in ways which would make those optimizations useful". Combined with how tricky atomic operations can be, optimizer implementors would likely not waste time on optimisations around atomic operations. ↩
-
Here the original essay includes a picture of "the iPhone, hard at work, running the experiment", however including such a caption would feel contemptuous and insulting for the poor phone, the MBP is not hard at work when running this12. ↩
-
If you read the original essay, or the struck out part, you'll see ARMv7 only provided memory barriers and exclusive load/stores, so CAS operations had to be implemented manually; in ARMv8.1 atomic semantics (memory ordering) were added to the ISA, no doubt due to the rise of multicore ARM devices. ↩
-
Or Jon Gjengset's Crust of Rust: Atomics and Memory Ordering. ↩
-
But what device is not, in 2022? ↩
-
Good luck finding one in running conditions, and onto which you can still load code... ↩
-
Not actually that easy, because Rust gets very unhappy when sharing state without proper synchronisation ↩
-
x86 is not sequentially consistent though, Jeff Preshing has an other article on the subject: memory reordering caught in the act. ↩
-
That does not mean
incis atomic, it's not (although it might look that way on a single-core machine, much like an iPhone 3GS that assumes you can still find one though) ↩ -
When compiling in
--releaseanyway, compiling in debug is a very different story and very very slow. Don't do it. For reference, this machine takes 1mn 8 seconds wallclock to complete one iteration in debug, in release the first iteration completes in under 1.2s. ↩