Automatic Playlist Recommender.
We studied and implemented some algorithms to deal with the playlist continuation problem. Check out our website with the report of this work and our screencast.
This is our final project for Foundations of Data Science, a Mathematical Modelling Master's subject at Getulio Vargas Foundation (FGV).
Group: Lucas Emanuel Resck Domingues and Lucas Machado Moschen. Professor: Dr. Jorge Poco.
This repository contains our approach to the playlist continuation problem. We scraped data from Spotify and Last.fm and we made an exploratory data analysis. We also implemented models of playlist continuation and we saw good results. We develop a website to expose our work.
├─ documents -------------------- Deliverables of our project
├─ images ----------------------- Images for our deliverables and README
├─ notebooks
│ ├─ data_scrapping ------------ Notebooks to scrap data
│ ├─ eda ----------------------- Notebooks of EDA
│ ├─ playlist_similarity_model - Model based on playlist similarity
│ └─ track_similarity_model ---- Model based on track similarity
├─ report ----------------------- Our website documents
└─ scripts ---------------------- Scripts to generate data
You can:
- Get a list of Last.fm users
- Scrap their public data in Last.fm and Spotify
- Make an exploratory data analysis of these datasets
- Analyse both recommendation models
All notebooks are very well documented and the models are explained in them.
In a network propagation fashion, users are gathered from Last.fm. To do this, run:
python generate_lastfm_users.py -hTo scrap data from Spotify and Last.fm, run the notebooks of the folder notebooks/data_scraping/.
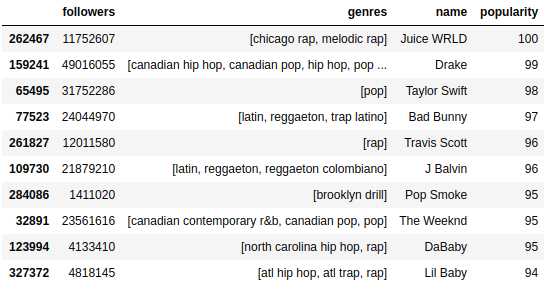
The template for an EDA of both datasets are inside the folder notebooks/eda/. Fell free to edit and addapt it to your own needs.
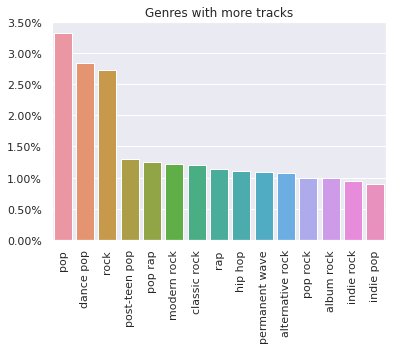
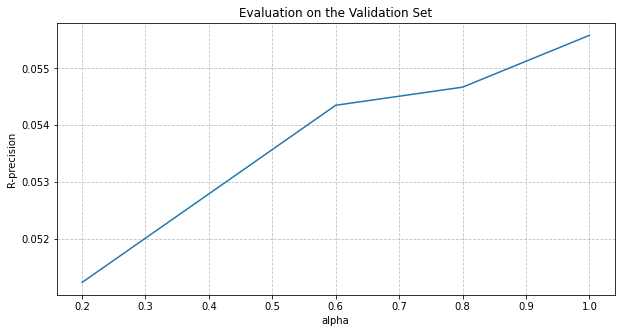
Three models are implemented and documented inside notebooks/.
The first is baseline model, with a random walk in a bipartite graph (simplest similarity matrix). The second is a model based on track similarity, and the third is based on playlist similarity. Each model has its notebook detailing the math behind it, as well as the code.
We used the packages Spotipy and Pylast to scrap data from Spotify and Last.fm. Just install the requirements:
pip install -r requirements.txt