Librato now provides native support for Collectd via the Write HTTP plugin included in most distributions. This has many advantages over the legacy Python plugin including fewer dependencies (e.g. Python!) and much simpler configuration. It is now the recommended approach for system monitoring in Librato via Collectd. This plugin, while still functional, should be considered deprecated and not used in new deployments.
collectd-librato is a collectd plugin that publishes collectd values to Librato Metrics using the Librato Metrics API. Librato Metrics is a hosted, time-series data service.
Collectd-librato was largely influenced by collectd-carbon.
- Collectd versions 4.9.5, 4.10.3, and 5.0.0 (or later). Earlier versions of 4.9.x and 4.10.x may require a patch to fix the Python plugin in collectd (See below).
- Python 2.6 or later.
- An active Librato Metrics account (sign up here).
If you are using Chef, there is now a Chef cookbook available that will install and configure the collectd Librato plugin.
If you are using Ansible, Bruce Burgess has added Librato collectd integration to their ansible-pcd framework.
Eric-Olivier Lamey provides RPM packages for the collectd-librato plugin on RHEL/CentOS 5.x and 6.x distributions using his pakk repo.
To install collectd-librato from the pakk repo:
- Make sure you have the EPEL repository configured.
- Enable the pakk
repository. As root do:
wget -O /etc/yum.repos.d/pakk.repo http://pakk.96b.it/pakk.repo - Install the plugin. As root do:
yum install collectd-librato - Configure the
/etc/collectd.d/librato.conffile as described below.
If you have a /etc/collectd5.conf file it should probably contain something like the following:
BaseDir "/var/lib/collectd5"
PIDFile "/var/run/collectd5.pid"
TypesDB "/usr/share/collectd5/types.db"
LoadPlugin syslog
LoadPlugin cpu
LoadPlugin interface
LoadPlugin load
LoadPlugin memory
<LoadPlugin "python">
Globals true
</LoadPlugin>
<Plugin "python">
ModulePath "/usr/lib64/collectd/python"
Import "collectd-librato"
<Module "collectd-librato">
Email "LIBRATO_EMAIL_ADDRESS"
APIToken "LIBRATO_API_TOKEN"
</Module>
</Plugin>
Check the logs: /var/log/messages or /var/log/syslog, etc.
Starting collectd5: Could not find plugin rrdtool.
The collectd daemon has been configured to load the collectd plugin named "rrdtool" but it can't find it.
If you are only sending data to Librato this can be safely ignored and
the LoadPlugin rrdtool statement in the collectd configuration can be removed.
Unhandled python exception in init callback: Exception: Collectd-Librato.py: ERROR: Unable to open TypesDB file: /usr/share/collectd/types.db.
plugin_dispatch_values: No write callback has been registered. Please load at least one output plugin, if you want the collected data to be stored.
Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status 2 (ENOENT). Most likely this means you didn't load any write plugins.
The collectd daemon plugin for librato could not find a file that it needs. This file is probably present but in a different location. Try the following:
cd /usr/share
ln -s collectd5 collectd
Installation from source is provided by the Makefile included in the project.
Simply clone this repository and run make install as root:
$ git clone git://github.com/librato/collectd-librato.git
$ cd collectd-librato
$ sudo make install
Installed collected-librato plugin, add this
to your collectd configuration to load this plugin:
<LoadPlugin "python">
Globals true
</LoadPlugin>
<Plugin "python">
# collectd-librato.py is at /opt/collectd-librato-0.0.10/lib/collectd-librato.py
ModulePath "/opt/collectd-librato-0.0.10/lib"
Import "collectd-librato"
<Module "collectd-librato">
Email "[email protected]"
APIToken "1985481910fe29ab201302011054857292"
</Module>
</Plugin>
The output above includes a sample configuration file for the
plugin. Simply add this to /etc/collectd.conf or drop in the
configuration directory as /etc/collectd.d/librato.conf and restart
collectd. See the next section for an explanation of the plugin's
configuration variables.
The plugin requires some configuration. This is done by passing parameters via the config section in your Collectd config.
To control the frequency (resolution) of metrics sent by collectd to
Librato, you must update the collectd option
Interval specified
in the global collectd.conf file to the desired resolution in seconds.
The following parameters are required:
-
Email- The email address associated with your Librato Metrics account. -
APIToken- The API token for you Librato Metrics account. This value can be found your account page.
The following parameters are optional:
-
TypesDB- file(s) defining your Collectd types. This should be the sames as your TypesDB global config parameters, but multiple values should be separated by commas instead of spaces:TypesDB "/usr/share/collectd/types.db,/my/custom/collectd_type.db"This will default to the file/usr/share/collectd/types.db. NOTE: This plugin will not work if it can't find the types.db file. -
LowercaseMetricNames- If preset, all metric names will be converted to lower-case (default no lower-casing). -
MetricPrefix- If present, all metric names will contain this string prefix. Do not include a trailing period or separation character (seeMetricSeparator). Set to the empty string to disable any prefix. Defaults to "collectd". -
MetricSeparator- String to separate the components of a metric name when combining the plugin name, type, and instance name. Defaults to a period ("."). -
IncludeSingleValueNames- Normally, any metric type listed intypes.dbthat only has a single value will not have the name of the value suffixed onto the metric name. For most single value metrics the name is simply a placeholder like "value" or "count", so adding it to the metric name does not add any particular value. IfIncludeSingleValueNamesis set however, these value names will be suffixed onto the metric name regardless. -
Source- By default the source name is taken from the configured collectd hostname. If you want to override the source name that is used with Librato Metrics you can set theSourcevariable to a different source name. -
IncludeRegex- This option can be used to control the metrics that are sent to Librato Metrics. It should be set to a comma-separated list of regular expression patterns to match metric names against. If a metric name does not match one of the regex's in this variable, it will not be sent to Librato Metrics. By default, all metrics in collectd are sent to Librato Metrics. For example, the following restricts the set of metrics to CPU and select df metrics:IncludeRegex "collectd.cpu.*,collectd.df.df.dev.free,collectd.df.df.root.free" -
FloorTimeSecs- Set the time interval (in seconds) to floor all measurement times to. This will ensure that the real-time samples on graphs will align on the time interval boundary across multiple collectd hosts. By default, measurement times are not floored and use the exact timestamp emitted from collectd. This value should be set to the sameIntervaldefined in the main collectd.conf.
The following is an example Collectd configuration for this plugin:
<LoadPlugin "python">
Globals true
</LoadPlugin>
<Plugin "python">
# collectd-librato.py is at /opt/collectd-librato-0.0.10/lib/collectd-librato.py
ModulePath "/opt/collectd-librato-0.0.10/lib"
Import "collectd-librato"
<Module "collectd-librato">
Email "[email protected]"
APIToken "1985481910fe29ab201302011054857292"
</Module>
</Plugin>
Collectd-Librato currently supports the following collectd metric types:
- GAUGE - Reported as a Librato Metric gauge.
- COUNTER - Reported as a Librato Metric counter.
- DERIVE - Reported as a Librato Metric counter.
Other metric types are currently ignored. This list will be expanded in the future.
Collectd's CPU plugin will, by default, break out each CPU's individual user, system, wait, etc. time as an individual metric. In total there are eight different CPU times, so for a box with 24 cores there will be 24 * 8 => 192 metrics published. In most cases you don't actually need the granularity that the breakout provides, you simply want to know user time vs. idle time, etc.
With collectd release 5.2 there is now an aggregation plugin that can aggregate across collectd metrics before they are sent on to the write plugins (and on to Librato). To use this plugin we follow the example configuration for aggregating CPU metrics across a host. Add the following to your collectd.conf:
LoadPlugin aggregation
<Plugin "aggregation">
<Aggregation>
Plugin "cpu"
Type "cpu"
GroupBy "Host"
GroupBy "TypeInstance"
CalculateSum true
CalculateAverage true
</Aggregation>
</Plugin>
This will compute the sum and average of each CPU timing metric across all CPUs. The metrics will be sent as: collectd.aggregation.cpu-sum.cpu.idle, collectd.aggregation.cpu-sum.cpu.wait, etc.
Once you have that working, the next step is to drop the breakout CPU metrics from posting to your account. You can use the collectd chains feature to filter out the CPU metrics by adding the following to your collectd.conf:
LoadPlugin match_regex
<Chain "PostCache">
<Rule "ignore_cpu" > # Send "cpu" values to the aggregation plugin.
<Match "regex">
Plugin "^cpu$"
</Match>
<Target "write">
Plugin "aggregation"
</Target>
Target stop
</Rule>
Target "write"
</Chain>
Once you have this setup, create an instrument that stacks the eight aggregated CPU timing metrics to get a break out of CPU performance:
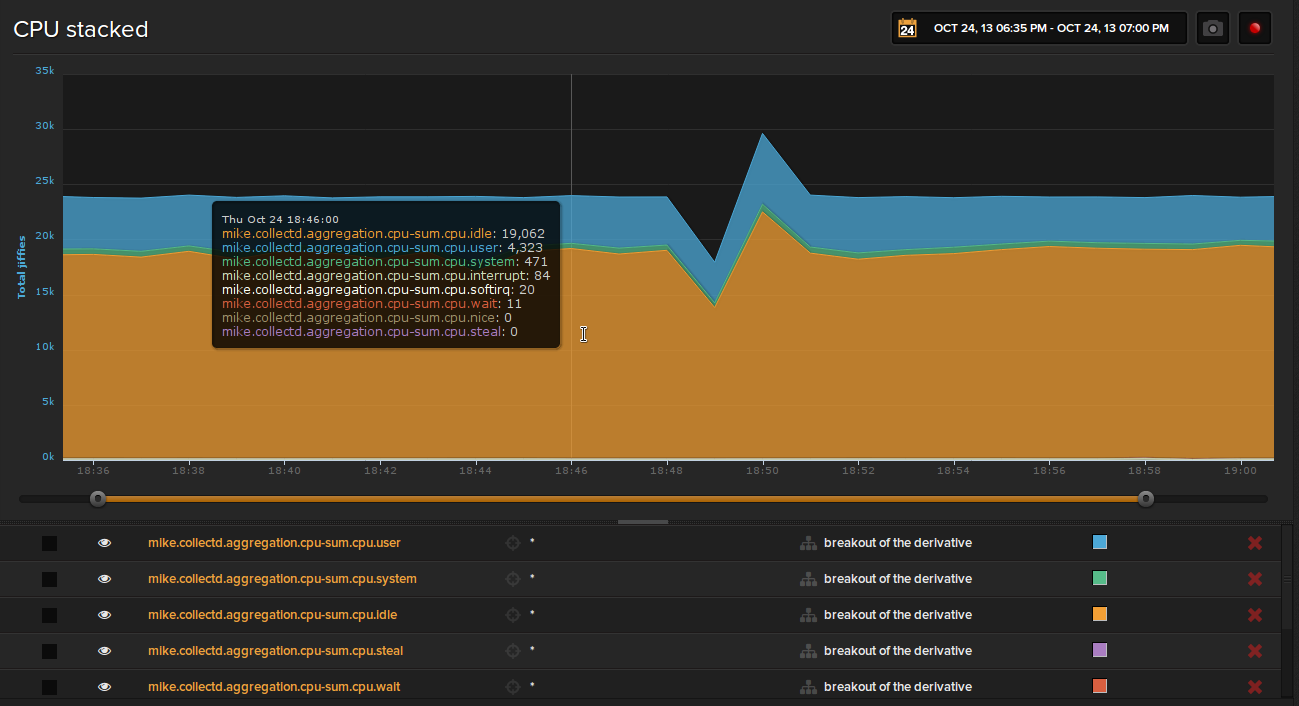
This plugin uses a best-effort attempt to deliver metrics to Librato Metrics. If a flush fails to POST metrics to Librato Metrics the flush will not currently be retried, but instead dropped. In most cases this should not happen, but if it does the plugin will continue to flush metrics after the failure. So in the worst case there may appear a short gap in your metric graphs.
The plugin needs to parse Collectd type files. If there was an error parsing a specific type (look for log messages at Collectd startup time), the plugin will fail to write values for this type. It will simply skip over them and move on to the next value. It will write a log message every time this happens so you can correct the problem.
The plugin needs to perform redundant parsing of the type files because the Collectd Python API does not provide an interface to the types information (unlike the Perl and Java plugin APIs). Hopefully this will be addressed in a future version of Collectd.
Collectd data is collected/written in discrete tuples having the following:
(host, plugin, plugin_instance, type, type_instance, time, interval, metadata, values)
values is itself a list of { counter, gauge, derive, absolute } (numeric) values. To further complicate things, each distinct type has its own definition corresponding to what's in the values field.
Librato Metrics, by contrast, deals with tuples of:
(source, metric_name, value, measurement_time)
So we effectively have to mangle the collectd tuple down to the fields above.
The source is simply set to the host field of the collectd
tuple. The plugin mangles the remaining fields of the collectd tuple
to the following Librato Metrics metric_name:
[metric_prefix.]plugin[.plugin_instance].type[.type_instance].data_source
Where data_source is the name of the data source (i.e. ds_name) in
the type being written. In the case that the plugin data source only
has a single value, the data_source is not included in the name
(unless IncludeSingleValueNames is set).
For example, the Collectd distribution has a built-in df type:
df used:GAUGE:0:1125899906842623, free:GAUGE:0:1125899906842623
The data_source values for this type would be used and free yielding the metric names (along the lines of) collectd.df.df.root.used and collectd.df.df.root.free for the root file-system.
Collectd versions through 4.10.2 and 4.9.4 have a bug in the Python plugin where Python would receive bad values for certain data sets. The bug would typically manifest as data values appearing to be 0. The collectd-carbon author identified the bug and sent a fix to the Collectd development team.
Collectd versions 4.9.5, 4.10.3, and 5.0.0 are the first official versions with a fix for this bug. If you are not running one of these versions or have not applied the fix (which can be seen at https://github.com/indygreg/collectd/commit/31bc4bc67f9ae12fb593e18e0d3649e5d4fa13f2), you will likely dispatch wrong values to Librato Metrics.
Using the plugin with collectd on Redhat-based distributions (RHEL, CentOS, Fedora) may produce the following error:
Jul 20 14:54:38 mon0 collectd[2487]: plugin_load_file: The global flag is not supported, libtool 2 is required for this.
Jul 20 14:54:38 mon0 collectd[2487]: python plugin: Error importing module "collectd_librato".
Jul 20 14:54:38 mon0 collectd[2487]: Unhandled python exception in importing module: ImportError: /usr/lib64/python2.4/lib-dynload/_socketmodule.so: undefined symbol: PyExc_ValueError
Jul 20 14:54:38 mon0 collectd[2487]: python plugin: Found a configuration for the "collectd_librato" plugin, but the plugin isn't loaded or didn't register a configuration callback.
Jul 20 14:54:38 mon0 collectd[2488]: plugin_dispatch_values: No write callback has been registered. Please load at least one output plugin, if you want the collected data to be stored.
Jul 20 14:54:38 mon0 collectd[2488]: Filter subsystem: Built-in target `write': Dispatching value to all write plugins failed with status 2 (ENOENT). Most likely this means you didn't load any write plugins.
This may also occur on other operating systems and collectd versions. It is caused by a libtool/libltdl quirk described in this mailing list thread. As per the workarounds detailed there, you may either:
-
Modify the init script
/etc/init.d/collectdto preload the libpython shared library:@@ -25,7 +25,7 @@ echo -n $"Starting $prog: " if [ -r "$CONFIG" ] then - daemon /usr/sbin/collectd -C "$CONFIG" + LD_PRELOAD=/usr/lib64/libpython2.4.so daemon /usr/sbin/collectd -C "$CONFIG" RETVAL=$? echo [ $RETVAL -eq 0 ] && touch /var/lock/subsys/$prog -
Modify the RPM and rebuild.
@@ -182,7 +182,7 @@ %build -%configure \ +%configure CFLAGS=-"DLT_LAZY_OR_NOW='RTLD_LAZY|RTLD_GLOBAL'" \ --disable-static \ --disable-ascent \ --disable-apple_sensors \
If you would like to contribute a fix or feature to this plugin please feel free to fork this repo, make your change and submit a pull request!