Tone Group Correlation
This page describes one step in the overall process overview for A-Z+T work. But this important step can be difficult to understand, so I'll try to lay out what is going on here, for those interested.
After A-Z+T divides your data into slices (all words with the same lexical category and syllable profile),
And after you define at least one tone frame,
And after you sort a data slice into a tone frame,
You have a set of surface sort groups, which are valid for a given tone frame, in a given slice of data. That is, these groups represent the words that sound the same as each other (and different from others) in that one context.
If you do this three times (e.g., for tone frames called 'isolation', 'plural', and 'accusative'), you would end up with three sets of surface sort groups, that might look like this (this shows sorting on the CVC noun data slice):
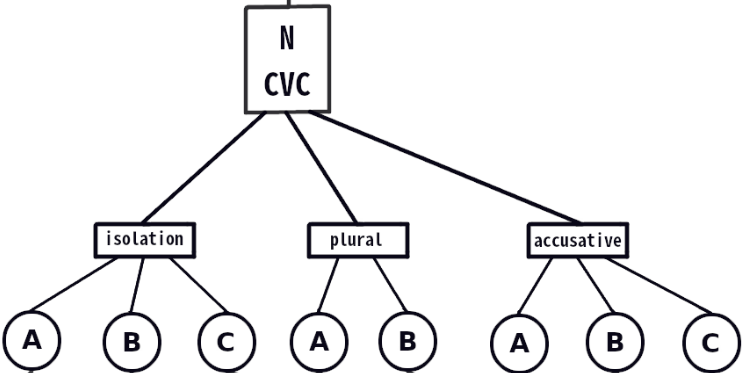
You may have more or fewer sort groups in one tone frame than in another; that is OK. We expect some contexts to neutralize an underlying tone contrast; this is one reason we sort in multiple frames.
It is critical to understand that the groups from sorting in one tone frame have no relationship to the groups from sorting in another frame; it is coincidental if they are named with the same letter. These names are just there at this point to distinguish one group from another —within a data slice and tone frame. You will ultimately want to give meaningful transcriptions of these surface groups, but that won't change the basic logic described on this page.
To draft underlying tone groups (which should be relevant across tone frames), A-Z+T looks through each word in the slice, and collects sort values for each frame. It then group words according to this collection of surface sort values. This results in a grouping of words which have the same sort values across frames.
The surface sort groups in the above image might correlate like this:
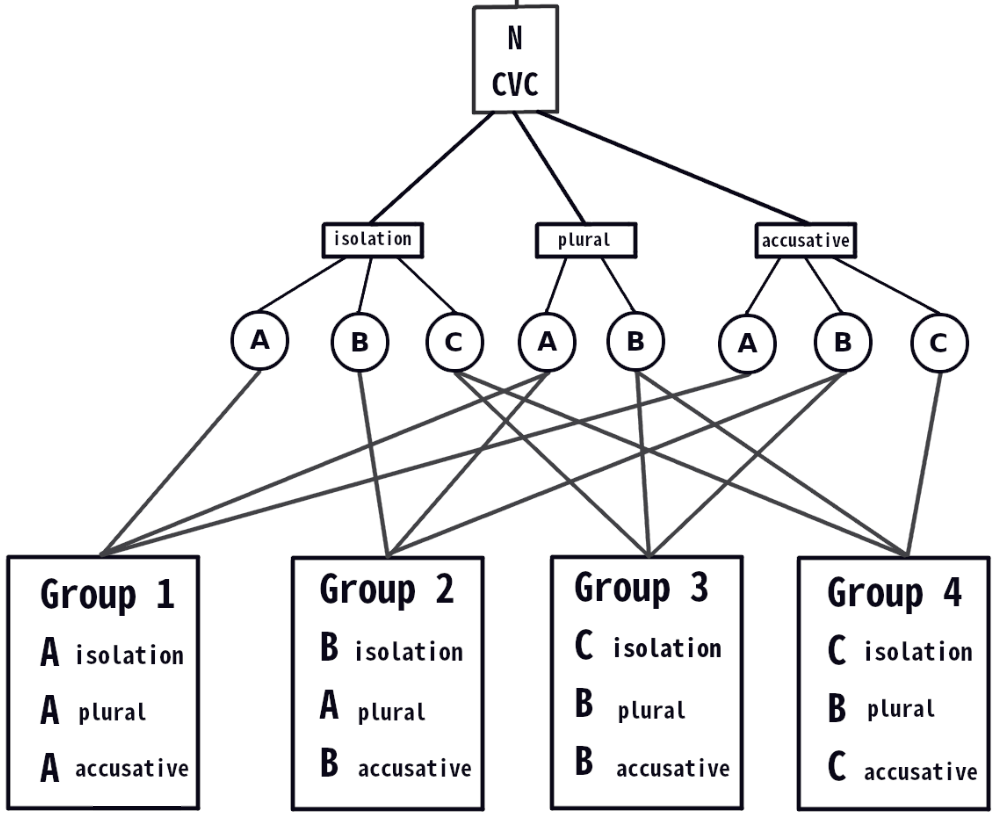
Because a draft UF group is defined by the set of surface sort values across frames, you will have at least as many draft UF groups as your largest number of sort groups in one frame. You may well have more.
It is also important to understand that this process automates a good deal of the legwork done by a linguist, but cannot replace the judgment of a human analyst. These groups are split by any difference, even ones that you might decide are unimportant. There is a Join UF groups task to help you make more appropriate groupings, but these groups are ultimately the responsability of the analyst(s).