-
Notifications
You must be signed in to change notification settings - Fork 56
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
999f869
commit 8b00cda
Showing
1 changed file
with
89 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,89 @@ | ||
| ## 背景 | ||
| 随着考拉服务化进程的推进,我们的应用架构逐步由集中式向分布式演进。这个时代的服务化调用往往带有以下特点: | ||
| 1. 一个完整的调用过程可能横跨多个服务; | ||
| 1. 服务提供方可能由不同团队、不同语言实现; | ||
| 1. 服务提供方本身是集群的方式支撑; | ||
|
|
||
|  | ||
|
|
||
| 在这种场景下,对于我们服务调用的性能监控和异常监控显得尤为重要。 | ||
|
|
||
| ## Trace 的目标 | ||
| 出于对服务调用的性能监控和异常监控的根本性诉求,Trace 便应运而生了,细化以后的目标大概有这些: | ||
| 1. 对应用运行时的服务调用,希望有一个直观的认识。 | ||
| 1. 当这些复杂的调用出现问题时,希望可以快速定位到是哪个服务出现了问题。 | ||
| 1. 当用户接口返回速度变慢时,希望可以快速得到出各个接口的耗时请情况。 | ||
|
|
||
| ## Trace 架构及流程 | ||
| 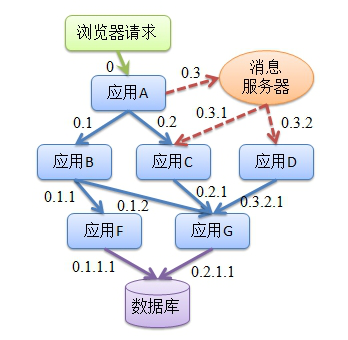 | ||
|
|
||
| 我们对以上调用关系进行分析,可以得到以下结论: | ||
| * 他是一个有向图,且顶点之间的边是单向的; | ||
| * 顶点 0 是这个图的入口; | ||
| * 服务调用存在发送方和接收方,使用深度优先遍历可以将边编号; | ||
|
|
||
| 我们可以有一个基础的 trace 设计思路了 | ||
|
|
||
| ### 流程 | ||
| Trace 想要正常运转,需要以下步骤: | ||
|
|
||
| 1. 上游服务接收到用户请求时,生成此次用户调用的唯一标示; | ||
| 1. 所有调用的发起和处理全部生成调用信息; | ||
| 1. 在当前端的所有调用都完成后,统一将生成的调用信息发送给消息队列; | ||
| 1. 消息中心分析处理日志,将来自不同分布式应用的日志串联成 Trace 日志,入库; | ||
| 1. 提供可视化界面,供用户查看数据; | ||
|
|
||
| ### 架构 | ||
| 完成以上的流程,通常来说,需要三个角色 | ||
|
|
||
|  | ||
|
|
||
| 1. trace 客户端,一般是 web server,也有可能是 service 服务提供方,负责生成调用信息,并往消息队列发送消息; | ||
| 1. 消息队列,接收来自 trace 客户端生产的消息,并提供给 trace 服务端消费 | ||
| 1. trace 服务端,消息队列的消费者,会将来自所有 trace 客户端的消息生成成调用链,并入库 | ||
|
|
||
| ### 数据结构 | ||
| 在分布式系统中,用户的一次URL请求在各个系统中调用,这个调用关系会呈现成树形调用链。 Span记录了调用信息,Trace客户端会把Span记录在日志中。散落在各个系统的Span按唯一标识组装起来变形成了一颗树。 | ||
|
|
||
| #### Trace | ||
| Trace 代表一个完整的调用链,对应到如图的 0 节点,往往是面向用户的顶层应用,具有唯一的 traceId,生成 Span 时需要用到。 | ||
|
|
||
| #### Span | ||
| Span记录了调用信息,散落在各个系统的Span按唯一标识组装起来变形成了一颗树。Span中主要信息包含: | ||
|
|
||
| * traceId 整个调用链唯一的traceId,traceId在root节点生成。在分布式调用用通过技术手段传递到下一个节点。 | ||
| * spanId 该节点的标识,在分布式调用用通过技术手段传递到下一个节点作为下一个节点的parentId。 | ||
| * parentId 调用链中父节点的spanId。 | ||
| * spanName 该节点的名字,如URL Pattern、Dubbo service name、sql | ||
| * 该节点的处理时间等 | ||
|
|
||
|
|
||
| 值得注意的是: | ||
| 1. 需要 Server Span 和 Client Span 都生成的情况下,才能记录为一次合法的调用; | ||
| 1. 同一次调用的 Client Span 和 Server Span 会拥有一致的 spanId 和 processId | ||
|
|
||
| ## 使用 node 实现 trace 客户端 | ||
| 有了以上知识作为基础后,我们来思考如何用 nodejs 来实现这个 trace 的客户端。 | ||
|
|
||
| 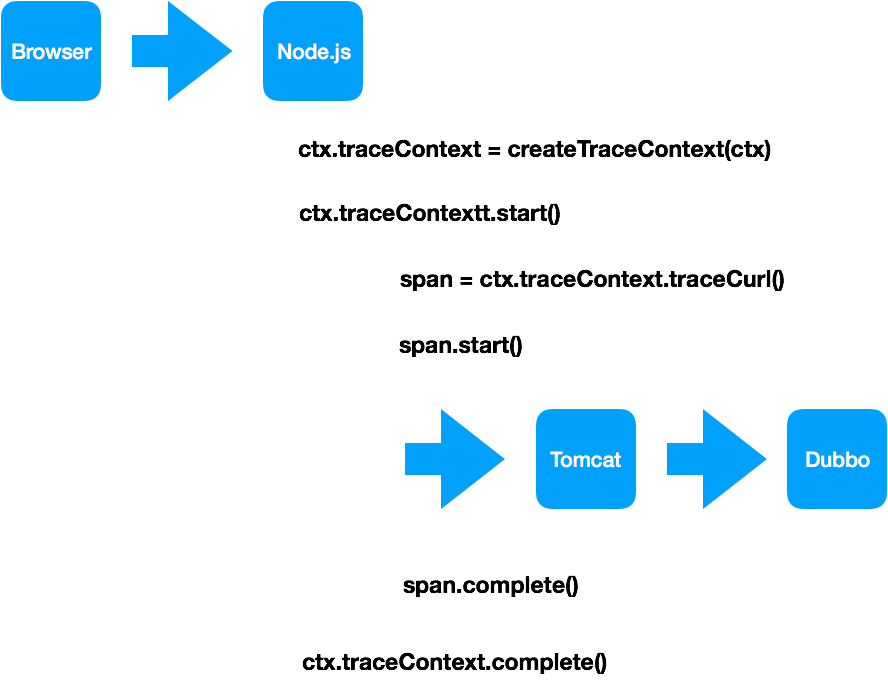 | ||
|
|
||
|
|
||
| 上图可以理解为一个 koa 的 middleware: | ||
|
|
||
| 1. 当用户请求达到时,初始化一个 traceContext | ||
| 1. 当前存在服务调用时,使用该 traceContext 去发起相关方法的调用操作,如: traceCurl、traceService 等等,当调用完成时手动执行 span.complete(),并将 error 信息传入 | ||
| 1. 当该用户请求完成时,调用 traceContext.complete() 终止此次 trace,并将该 traceContext 发送给消息队列 | ||
|
|
||
| ## 接入 Trace 后需要了解的 | ||
| ### 采样率 | ||
| 实际在生产环境,我们并不需要统计所有的服务调用,这会带来较高的统计成本,所以我们支持使用「采样率」来对一定比例的请求做跟踪。 | ||
|
|
||
| 比较优雅的方式是,你可能需要将这个「采样率」托管在 disconf 或者其他数据管理平台上 | ||
|
|
||
| ### 压测标识 | ||
| Trace 期望监测的是线上的真实调用情况,所以对于压测场景,期望能做区分以排除此类数据,所以较为通用的方式是如果在 cookie 上传入某个字段,则表示为压测数据。 | ||
|
|
||
| ## 总结 | ||
| 以上阐述的 Trace 方案其实最终灵感都是来自于 Google Dapper。 | ||
|
|
||
| 而如何更为优雅的统计应用的服务调用,可能还需要不断地探索 |