This repo is to demonstrate development of two-tower models using gcs and BigQuery for data prep and tf.data with Tensorflow Recommenders. This repo reflects the development process that later feeds into a hardened ML Ops process. For more detail on enabling Vertex Pipelines and deployment to the Matching Engine for recommendations, see this repo.
The end to end example (with public data) follows this architecture:

-
00-load-core-data-to-bq Extract from the zip file and upload to BQ. This notebook then enriches features for the playlist songs
-
01-bq-data-prep Join the features and unpack the BQ data then use BQ to cross-joins songs with features (expected rows = n_songs x n_playlists). Additional preprocessing to remove after-the-fact (later position songs) from the newly generated samples, then create a clean train table, and flatten structs or use arrays
-
02-tfrecord-beam-pipeline uses beam to download the training tables to gcs and serialize the data into tfrecords. This notebook calls on
beam_trainingandbeam_candidatesmodule for the Dataflow job -
03-build-model this reads the tfrecords created from Dataflow and constructs a Tensorflow Recommender model for training on a single machine. Note settings tuned for a
high-gpusingle machine, single A100 gpu and may require different batch sizes for different configurations. Note many of the configurations were found by querying distinct counts for hashing functions and average/variance queries to get the settings for normalization. -
04-custom-train this shows how scale model training by submitting a training package to Vertex AI Training via the
vertex_ai.CustomJobAPI. -
05-candidate-generation This notebook covers how to manually make calls to the deployed query tower model. It covers how to generate embeddings that will be used for queries to the ANN Matching Engine service
-
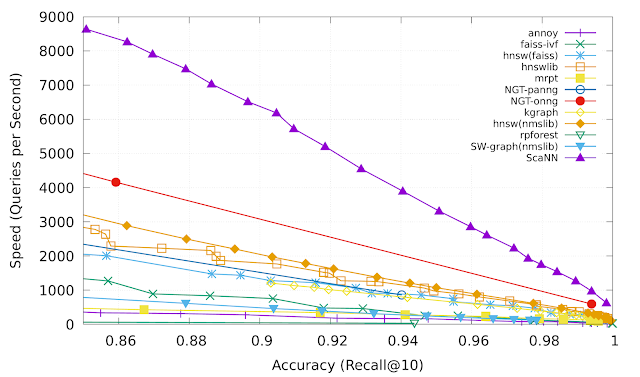
06-matching-engine this covers how to enable VPC network peering for Matching Engine, and shows how to set up different search indexes. It covers how to benchmark speed/recall tradeoff vs. brute force search queries. See more on Matching Engine speed/recall benchmarks here. Note that ScaNN is the algorithm Matching Engine uses
-
07-train-pipeline this shows how to orchestrate all the previous steps using Vertex Pipelines. Demonstrates how to build custom pipeline components and use them together with prebuilt components
-
08-recs-for-your-spotify This final notebook lets you use the recommender model to recommend tracks for your Spotify playlists. This uses the
spotipylibrary to get the features of songs you listen to to validate the results.
Before you begin, it is recommended to create a new Google Cloud project so that the activities from this lab do not interfere with other existing projects.
If you are using a provided temporary account, please just select an existing project that is pre-created before the event as shown in the image below.

It is not uncommon for the pre-created project in the provided temporary account to have a different name. Please check with the account provider if you need more clarifications on which project to choose.
If you are NOT using a temporary account, please create a new Google Cloud project and select that project. You may refer to the official documentation (Creating and Managing Projects) for detailed instructions.
To run the notebooks successfully, follow the steps below.
-
Please make sure that you have selected a Google Cloud project as shown in the Creating a Google Cloud project section previously.
-
Activate Cloud Shell in your project by clicking the
Activate Cloud Shellbutton as shown in the image below.
-
Once the Cloud Shell has activated, copy the following codes and execute them in the Cloud Shell to enable the necessary APIs, and create Pub/Sub subscriptions to read streaming transactions from public Pub/Sub topics.
gcloud services enable notebooks.googleapis.com gcloud services enable cloudresourcemanager.googleapis.com gcloud services enable aiplatform.googleapis.com gcloud services enable run.googleapis.com gcloud services enable cloudbuild.googleapis.com gcloud services enable dataflow.googleapis.com gcloud services enable bigquery.googleapis.com # Run the following command to grant the Compute Engine default service account access to read and write pipeline artifacts in Google Cloud Storage. PROJECT_ID=$(gcloud config get-value project) PROJECT_NUM=$(gcloud projects list --filter="$PROJECT_ID" --format="value(PROJECT_NUMBER)") gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:${PROJECT_NUM}[email protected]"\ --role='roles/storage.admin'
-
Authorize the Cloud Shell if it prompts you to. Please note that this step may take a few minutes. You can navigate to the Pub/Sub console to verify the subscriptions.

-
Browse to Vertex AI Workbench page, Click on "USER-MANAGED NOTEBOOKS" and Click on "+ NEW NOTEBOOK"
-
Please make sure you have selected the correct project when creating a new notebook. Upon clicking the "+ NEW NOTEBOOK", you will be presented with a list of notebook instance options. Select
Tensorflow Enterprise 2.8
-
Pick a name (or leave it default), select a location, and then click "CREATE" to create the notebook instance.
-
The instance will be ready when you see a green tick and can click on "OPEN JUPYTERLAB" on the User-Managed Notebooks page. It may take a few minutes for the instance to be ready.

- Click on "OPEN JUPYTERLAB", which should launch your Managed Notebook in a new tab.
- Open a terminal via the file menu: File > New > Terminal.




-
Run the following code to clone this repo:
git clone https://github.com/jswortz/spotify_mpd_two_tower.git -
You can also navigate to the menu on the top left of the Jupyter Lab environment and click on Git > Clone a repository.
-
Once cloned, you should now see the spotify_mpd_two_tower folder in your main directory.
-
Open the first notebook:
00-bq-data-prep.ipynb -
Follow the instructions in the notebook, and continue through the remaining notebooks.
(TODO) General:
python-decouple
Tensorflow:
tensorflow==2.11.0
tensorflow-cloud==0.1.16
tensorflow-datasets==4.8.2
tensorflow-estimator==2.11.0
tensorflow-hub==0.12.0
tensorflow-io==0.27.0
tensorflow-io-gcs-filesystem==0.27.0
tensorflow-metadata==1.11.0
tensorflow-probability==0.19.0
tensorflow-recommenders==0.7.2
tensorflow-serving-api==2.10.1
tensorflow-transform==1.11.0
nvtop is recommended to monitor GPU usage when tuning settings. See here for instructions
(Documentation updated Aug 5, 2020)
The Million Playlist Dataset contains 1,000,000 playlists created by users on the Spotify platform. It can be used by researchers interested in exploring how to improve the music listening experience.
The MPD contains a million user-generated playlists. These playlists were created during the period of January 2010 through October 2017. Each playlist in the MPD contains a playlist title, the track list (including track metadata) editing information (last edit time, number of playlist edits) and other miscellaneous information about the playlist. See the Detailed Description section for more details.
Usage of the Million Playlist Dataset is subject to these license terms
To use this dataset, please cite the following paper:
Ching-Wei Chen, Paul Lamere, Markus Schedl, and Hamed Zamani. Recsys Challenge 2018: Automatic Music Playlist Continuation. In Proceedings of the 12th ACM Conference on Recommender Systems (RecSys ’18), 2018.
The dataset is available at https://www.aicrowd.com/challenges/spotify-million-playlist-dataset-challenge
You can validate the dataset by checking the md5 hashes of the data. From the top level directory of the MPD:
% md5sum -c md5sums
This should print out OK for each of the 1,000 slice files in the dataset.
You can also compute a number of statistics for the dataset as follows:
% python src/stats.py data
The output of this program should match what is in 'stats.txt'. Depending on how fast your computer is, stats.py can take 30 minutes or more to run.
The Million Playlist Dataset consists of 1,000 slice files. These files have the naming convention of:
mpd.slice.STARTING_PLAYLIST_ID_-_ENDING_PLAYLIST_ID.json
For example, the first 1,000 playlists in the MPD are in a file called
mpd.slice.0-999.json and the last 1,000 playlists are in a file called
mpd.slice.999000-999999.json.
Each slice file is a JSON dictionary with two fields: info and playlists.
The info field is a dictionary that contains general information about the particular slice:
- slice - the range of slices that in in this particular file - such as 0-999
- version - - the current version of the MPD (which should be v1)
- description - a description of the MPD
- license - licensing info for the MPD
- generated_on - a timestamp indicating when the slice was generated.
This is an array that typically contains 1,000 playlists. Each playlist is a dictionary that contains the following fields:
- pid - integer - playlist id - the MPD ID of this playlist. This is an integer between 0 and 999,999.
- name - string - the name of the playlist
- description - optional string - if present, the description given to the playlist. Note that user-provided playlist descrptions are a relatively new feature of Spotify, so most playlists do not have descriptions.
- modified_at - seconds - timestamp (in seconds since the epoch) when this playlist was last updated. Times are rounded to midnight GMT of the date when the playlist was last updated.
- num_artists - the total number of unique artists for the tracks in the playlist.
- num_albums - the number of unique albums for the tracks in the playlist
- num_tracks - the number of tracks in the playlist
- num_followers - the number of followers this playlist had at the time the MPD was created. (Note that the follower count does not including the playlist creator)
- num_edits - the number of separate editing sessions. Tracks added in a two hour window are considered to be added in a single editing session.
- duration_ms - the total duration of all the tracks in the playlist (in milliseconds)
- collaborative - boolean - if true, the playlist is a collaborative playlist. Multiple users may contribute tracks to a collaborative playlist.
- tracks - an array of information about each track in the playlist. Each element in the array is a dictionary with the following fields:
- track_name - the name of the track
- track_uri - the Spotify URI of the track
- album_name - the name of the track's album
- album_uri - the Spotify URI of the album
- artist_name - the name of the track's primary artist
- artist_uri - the Spotify URI of track's primary artist
- duration_ms - the duration of the track in milliseconds
- pos - the position of the track in the playlist (zero-based)
Here's an example of a typical playlist entry:
{
"name": "musical",
"collaborative": "false",
"pid": 5,
"modified_at": 1493424000,
"num_albums": 7,
"num_tracks": 12,
"num_followers": 1,
"num_edits": 2,
"duration_ms": 2657366,
"num_artists": 6,
"tracks": [
{
"pos": 0,
"artist_name": "Degiheugi",
"track_uri": "spotify:track:7vqa3sDmtEaVJ2gcvxtRID",
"artist_uri": "spotify:artist:3V2paBXEoZIAhfZRJmo2jL",
"track_name": "Finalement",
"album_uri": "spotify:album:2KrRMJ9z7Xjoz1Az4O6UML",
"duration_ms": 166264,
"album_name": "Dancing Chords and Fireflies"
},
{
"pos": 1,
"artist_name": "Degiheugi",
"track_uri": "spotify:track:23EOmJivOZ88WJPUbIPjh6",
"artist_uri": "spotify:artist:3V2paBXEoZIAhfZRJmo2jL",
"track_name": "Betty",
"album_uri": "spotify:album:3lUSlvjUoHNA8IkNTqURqd",
"duration_ms": 235534,
"album_name": "Endless Smile"
},
{
"pos": 2,
"artist_name": "Degiheugi",
"track_uri": "spotify:track:1vaffTCJxkyqeJY7zF9a55",
"artist_uri": "spotify:artist:3V2paBXEoZIAhfZRJmo2jL",
"track_name": "Some Beat in My Head",
"album_uri": "spotify:album:2KrRMJ9z7Xjoz1Az4O6UML",
"duration_ms": 268050,
"album_name": "Dancing Chords and Fireflies"
},
// 8 tracks omitted
{
"pos": 11,
"artist_name": "Mo' Horizons",
"track_uri": "spotify:track:7iwx00eBzeSSSy6xfESyWN",
"artist_uri": "spotify:artist:3tuX54dqgS8LsGUvNzgrpP",
"track_name": "Fever 99\u00b0",
"album_uri": "spotify:album:2Fg1t2tyOSGWkVYHlFfXVf",
"duration_ms": 364320,
"album_name": "Come Touch The Sun"
}
],
}There are some tools in the src/ directory that you can use with the dataset:
- check.py - checks to se that the MPD is correct
- deeper_stats.py - shows deep stats for the MPD
- descriptions.py - surfaces the most common descriptions in the MPD
- print.py - prints the full MPD
- show.py - shows playlists by id or id range in the MPD
- stats.py - iterates over the million playlist dataset and outputs info about what is in there.
The Million Playist Dataset is created by sampling playlists from the billions of playlists that Spotify users have created over the years. Playlists that meet the following criteria are selected at random:
- Created by a user that resides in the United States and is at least 13 years old
- Was a public playlist at the time the MPD was generated
- Contains at least 5 tracks
- Contains no more than 250 tracks
- Contains at least 3 unique artists
- Contains at least 2 unique albums
- Has no local tracks (local tracks are non-Spotify tracks that a user has on their local device)
- Has at least one follower (not including the creator)
- Was created after January 1, 2010 and before December 1, 2017
- Does not have an offensive title
- Does not have an adult-oriented title if the playlist was created by a user under 18 years of age
Additionally, some playlists have been modified as follows:
- Potentially offensive playlist descriptions are removed
- Tracks added on or after November 1, 2017 are removed
Playlists are sampled randomly, for the most part, but with some dithering to disguise the true distribution of playlists within Spotify. Paper tracks may be added to some playlists to help us identify improper/unlicensed use of the dataset.
- Male: 45%
- Female: 54%
- Unspecified: 0.5%
- Nonbinary: 0.5%
- 13-17: 10%
- 18-24: 43%
- 25-34: 31%
- 35-44: 9%
- 45-54: 4%
- 55+: 3%
- US: 100%
The million playlist dataset was built by the following researchers @ Spotify:
- Cedric De Boom
- Paul Lamere
- Ching-Wei Chen
- Ben Carterette
- Christophe Charbuillet
- Jean Garcia-Gathright
- James Kirk
- James McInerney
- Vidhya Murali
- Hugh Rawlinson
- Sravana Reddy
- Marc Romejin
- Romain Yon
- Yu Zhao
UI Endpoint formatting for predicting via instance format on Vertex Endpoint (query model):
{"instances": [{
"album_name_can":"We Just Havent Met Yet",
"album_name_pl":[
"There's Really A Wolf",
"Late Nights: The Album",
"American Teen",
"Crazy In Love",
"Pony"
],
"album_uri_can":"spotify:album:5l83t3mbVgCrIe1VU9uJZR",
"artist_followers_can":4339757.0,
"artist_genres_can":"'hawaiian hip hop', 'rap'",
"artist_genres_pl":[
"'hawaiian hip hop', 'rap'",
"'chicago rap', 'dance pop', 'pop', 'pop rap', 'r&b', 'southern hip hop', 'trap', 'urban contemporary'",
"'pop', 'pop r&b'",
"'dance pop', 'pop', 'r&b'",
"'chill r&b', 'pop', 'pop r&b', 'r&b', 'urban contemporary'"
],
"artist_name_can":"Russ",
"artist_name_pl":[
"Russ",
"Jeremih",
"Khalid",
"Beyonc\\xc3\\xa9",
"William Singe"
],
"artist_pop_can":82.0,
"artist_pop_pl":[
82.0,
80.0,
90.0,
87.0,
65.0
],
"artist_uri_can":"spotify:artist:1z7b1Pr1rSlvWRzsW3HOrS",
"artists_followers_pl":[
4339757.0,
5611842.0,
15046756.0,
30713126.0,
603837.0
],
"collaborative":"false",
"description_pl":"",
"duration_ms_can":237322.0,
"duration_ms_songs_pl":[
237506.0,
217200.0,
219080.0,
226400.0,
121739.0
],
"n_songs_pl":8.0,
"name":"Lit Tunes ",
"num_albums_pl":8.0,
"num_artists_pl":8.0,
"track_name_can":"We Just Havent Met Yet",
"track_name_pl":[
"Losin Control",
"Paradise",
"Location",
"Crazy In Love - Remix",
"Pony"
],
"track_pop_can":57.0,
"track_pop_pl":[
79.0,
58.0,
83.0,
71.0,
57.0
],
"track_uri_can":"spotify:track:0VzDv4wiuZsLsNOmfaUy2W",
"track_uri_pl":[
"spotify:track:4cxMGhkinTocPSVVKWIw0d",
"spotify:track:1wNEBPo3nsbGCZRryI832I",
"spotify:track:152lZdxL1OR0ZMW6KquMif",
"spotify:track:2f4IuijXLxYOeBncS60GUD",
"spotify:track:4Lj8paMFwyKTGfILLELVxt"
]
}]}