{kind=link}
Implementation (with some experimentation) of the paper titled "VARIATIONAL DISCRIMINATOR BOTTLENECK: IMPROVING IMITATION LEARNING, INVERSE RL, AND GANS BY CONSTRAINING INFORMATION FLOW" (arxiv -> https://arxiv.org/pdf/1810.00821.pdf)
Implementation uses the PyTorch framework.
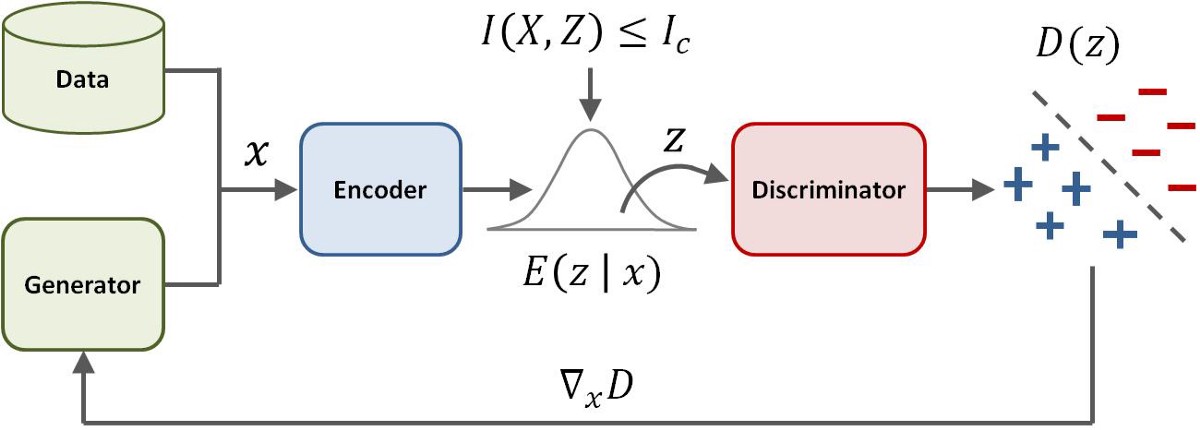
The core concept proposed by the paper is to enforce an Information Bottleneck between the Input images and the Discriminator’s internal representation of them.
As shown in the diagram, the Discriminator is divided into two parts now: An Encoder and the actual Discriminator. Note that the Generator is still the same. The Encoder is modelled using a ResNet similar in architecture to the Generator, while the Discriminator is a simple Linear classifier. Note that the Encoder doesn't output the internal codes of the images, but similar to a VAE’s encoder, gives the means and stds of the distributions from which samples are drawn and fed to discriminator.
I trained the VGAN-GP (just replace the normal GAN loss with WGAN-GP) on the CelebA dataset and the results are shown below.

The value for Ic that I used is 0.2 as described in the paper and the architectures for G and D are also as described in the paper. The authors trained the model for 300K iterations, but the results that I displayed are at 62K iterations which took me 22.5 hours to train. I will be training them further, but I would really like the readers and enthusiasts to take this forward as I have made the code open-source.
Running the training is actually very simple.
Just start the training by running the train.py script in the source/
directory. The test/ directory contains the unit tests if you would like
to change anything about the implementation
Refer to the following parameters for tweaking for your own use:
-h, --help show this help message and exit
--generator_file GENERATOR_FILE
pretrained weights file for generator
--gen_optim_file GEN_OPTIM_FILE
previously saved state of Generator Optimizer
--discriminator_file DISCRIMINATOR_FILE
pretrained_weights file for discriminator
--dis_optim_file DIS_OPTIM_FILE
previously saved state of Generator Optimizer
--images_dir IMAGES_DIR
path for the images directory
--folder_distributed_dataset FOLDER_DISTRIBUTED_DATASET
path for the images directory
--sample_dir SAMPLE_DIR
path for the generated samples directory
--model_dir MODEL_DIR
path for saved models directory
--loss_function LOSS_FUNCTION
loss function to be used: 'hinge', 'relativistic-
hinge', 'standard-gan', 'standard-gan_with-sigmoid',
'wgan-gp', 'lsgan'
--size SIZE Size of the generated image (must be a power of 2 and
>= 4)
--latent_distrib LATENT_DISTRIB
Type of latent distribution to be used 'uniform' or
'gaussian'
--latent_size LATENT_SIZE
latent size for the generator
--final_channels FINAL_CHANNELS
starting number of channels in the networks
--max_channels MAX_CHANNELS
maximum number of channels in the network
--init_beta INIT_BETA
initial value of beta
--i_c I_C value of information bottleneck
--batch_size BATCH_SIZE
batch_size for training
--start START starting epoch number
--num_epochs NUM_EPOCHS
number of epochs for training
--feedback_factor FEEDBACK_FACTOR
number of logs to generate per epoch
--num_samples NUM_SAMPLES
number of samples to generate for creating the grid
should be a square number preferably
--checkpoint_factor CHECKPOINT_FACTOR
save model per n epochs
--g_lr G_LR learning rate for generator
--d_lr D_LR learning rate for discriminator
--data_percentage DATA_PERCENTAGE
percentage of data to use
--num_workers NUM_WORKERS
number of parallel workers for reading files
Please Note that all the default values are tuned for the CelebA 128x128 experiment. Please refer to the paper for the CIFAR-10 and CelebA-HQ experiments.
Please refer to the shared drive for the saved weights for this model in PyTorch format.
medium blog -> https://medium.com/@animeshsk3/v-gan-variational-discriminator-bottleneck-an-unfair-fight-between-generator-and-discriminator-972563532dcc
Generated samples video -> https://www.youtube.com/watch?v=-0lBw9z8Ds0
My slack group -> https://join.slack.com/t/amlrldl/shared_invite/enQtNDcyMTIxODg3NjIzLTA3MTlmMDg0YmExYjY5OTgyZTg4MTg5ZGE1YzRlYjljZmM4MzI0MTg1OTcxOTc5NDQ4ZTcwMGVkZjBjZmU5ZWM
Please feel free to open Issues / PRs here
Cheers 🍻!
@akanimax :)