{kind=link}
Distributed Image Search with Hadoop
http://hiiamok.github.io/DISH/
DISH consists of 2 different parts
Generates a file including a list of all images and their imagefeatures (histogram)
Takes a local file, generates imagefeatures and compares them to all other images stored in the
ImageFeaturesGenerator generated file
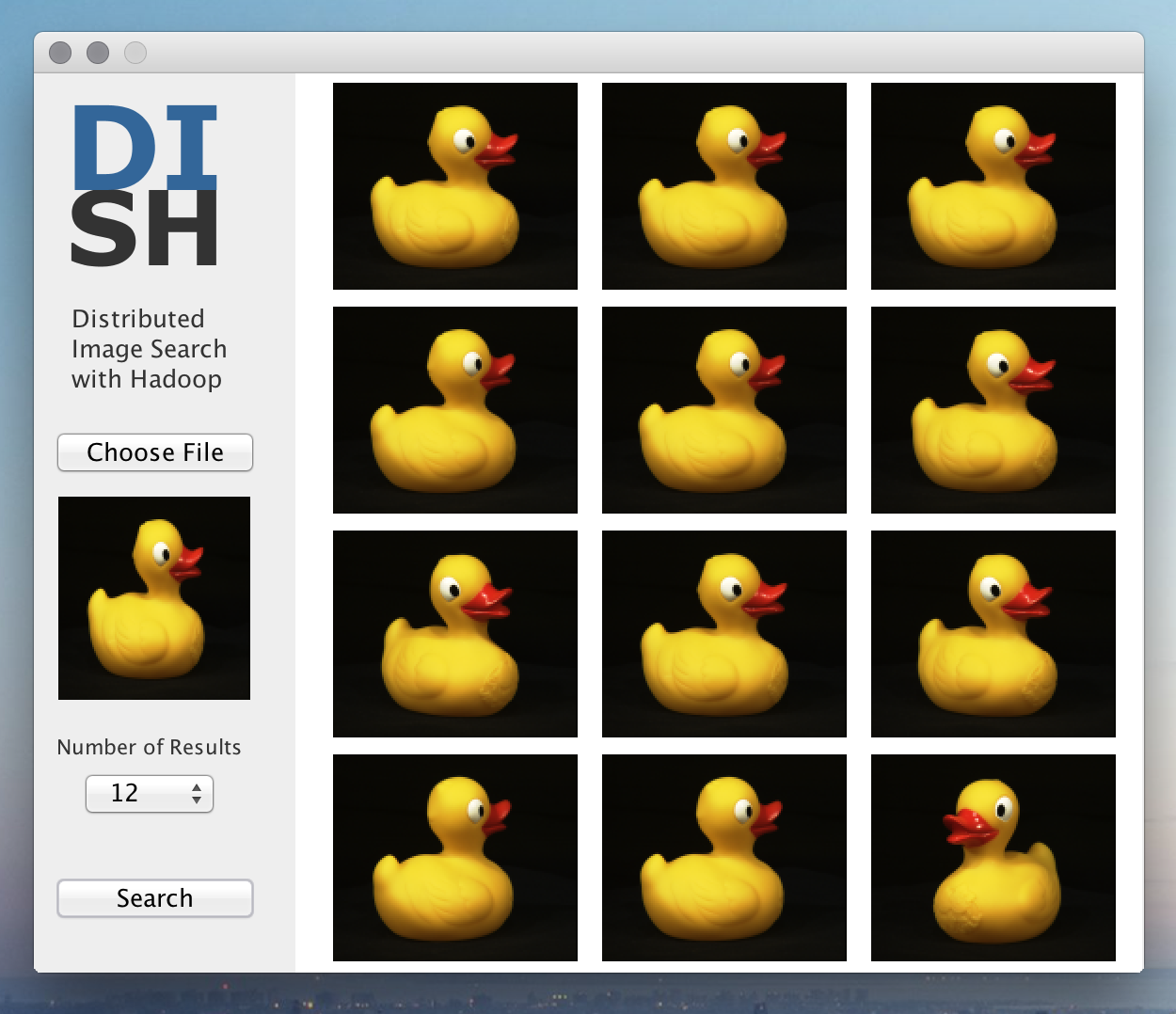
DISH was developed and tested on Mac OS X Yosemite running Java SDK 8.
The GUI might look different of other platforms.
hadoop jar ImageFeaturesGenerator.jar [options]
options:
-i, --images <path path hdfs image directory (default: /images)
-if, --imagefeatures <path> path to hdfs imagefeatures result (default: /imageFeatures)
-mb, --maxbytes max memory size of one split (default: 1GB)
-t, --time measure execution time
--help print usage information
hadoop jar ImageSearcher.jar [options]
options:
-s, --search <path> path to local query image
-i, --images <path> path hdfs image directory (default: /images)
-if, --imagefeatures <path> path to hdfs imagefeatures (default: /imageFeatures)
-r, --results n number of results (default: 1)
-o, --output <path> path to output (default: /DISH)
-l, --lines max number of lines each mapper reads (default: 10000)
-t, --time measure execution time
--help print usage information
--cli use commandline output instead of GUI
Note: By default the ImageSearcher is trying to open a GUI. If you are on a server or want to run it on the command line please use the parameter --cli
The ImageFeaturesGenerator takes an input directory of imagefiles, and generates
an indexfile of all existing images.
The generated file has the following format: filepath;imagefeatures;
where imagefeatures is a String representation of an image histogram.
(see SmallFileProblem.md for further information)
The ImageFeaturesGenerator is implemented as a MapReduce algorithm without Reducer.
For reading the image files saved on hdfs, a BinaryFileRecordReader was implemented.
To Combine several BinaryFiles a BinaryFileInputFormat was defined.
Info: The output of the ImageFeaturesGenerator will NOT be exactly one file.
Since it was written for distributed usage, each mapper will generate one result-file
in the defined output directory.
This is also useful for the ImageSearcher, because the ImageSearcher can split it's task
more easily. Still the ImageSearcher was designed in a way, that also 1 single input file
would result in several mappers. Therefore it is possible to change the number of lines
1 mapper process reads.
The ImageSearcher is implemented as a MapReduce algorithm with exactly one Reducer.
The input for the mapper is the the generated result of the ImageFeaturesGenerator.
To achieve a better performance of the mapper, not only one line is passed to one
mappertask. Each mapper receives several lines at once, and calculates the euclidian
distance for all of them. he top n results are passed on to the reducer.
For passing results from the mappers to the reducer a Writable
ImageDistanceMap was implemented.
It is only 1 reducer called! The reducer receives all top-lists of the mappers.
It then sorts this list, and gets the top n matching items, and writes them
into an output file.
In CLI mode the output file is read and printed. If the GUI is started,
the result file is read, and all result-images are loaded from hdfs displayed.