1712.09184
[arxiv 1712.09184] Detect-and-Track: Efficient Pose Estimation in Videos [PDF] [notes]
Rohit Girdhar, Georgia Gkioxari, Lorenzo Torresani, Manohar Paluri, Du Tran
Perform 3D pose-estimation and tracking on human body keypoints
Build upon Mask-RCNN, which itself builds upon Faster-RCNN.
Inflate (as described in i3d) the base part of Mask-RCNN ResNet network.
Clips instead of frames are therefore used as input.
The Region Proposal Network outputs tube posposals that allow to extract instance-specific features through RegionOfInterestAlign operations (matching feature spatially to matching locations in initial input)
A 3D CNN then outputs heatmap activations for all keypoints accross all frames, conditionned on the initial "tube hypothesis" (locations of the detections).
ResNet is inflated by replacing all 2D convolutions with 3D convolutions, the temporal extent of the kernels is set to match the spatial width, except for the first convolutional layer, for which the temporal kernel size is 3 vs 7 for the spatial dimensions.
A padding of 1 is added in temporal dimension for temporal kernel of size 3. Temporal strides are set to 1 (because increased strides decreased performance empirically).
Weights are initialized from ImageNet pretrained weights. Unlike i3d, which uses mean initialization (replication of weights in temporal dimension), they use a central initialization scheme. The central (in the temporal dimension) weights are set to be the same as the 2D weights, and the rest is initialized to 0. This leads, empirically, to better performances.
The tubes are predicted in Faster-RCNN fashion: two fully connected networks predict for 12 anchor boxes the class score and the regression parameters (which encodes spatial deformation and translation with relation to the anchor box).
RoIAlign was introduced in Mask-RCNN and is an improvement over RoIPooling which uses bilinear interpolation between feature map values to extract a fixed-size representation that matches a given location. RoIAlign avoids the loss of spatial accuracy involved by the quantization used in RoIPooling.
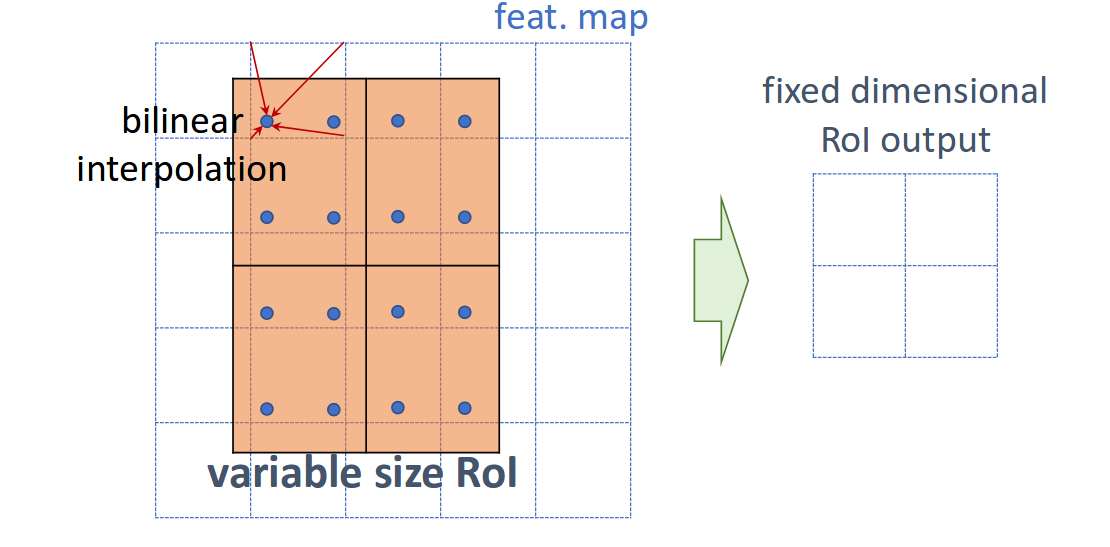
For each temporal slice of the tupe, RoIAlign is used to extract a fixed-size feature which are concatenated, generating a TxRxR map where T is the temporal duration, and R is the final spatial dimension.
They view the tracking problem as a bipartite matching problem from one frame to the next.
To assign the weights to the detections, they experimented with IoU and cosine distance between features as well as learned LSTM metrics, however, the simple metrics performed best, with the IoU one performing best in their case.
Their method obtains SOTA results on human pose keypoint tracking on the PoseTrack dataset according to the multi object tracking Accuracy MOTA metric.