Implementing #deepdream on video
Creative Request
It would be very helpful for other deepdream researchers, if you could include the used parameters in the description of your youtube videos. You can find the parameters in the image filenames.
Included experiment: Deep Dreaming Fear & Loathing in Las Vegas: the Great Fan Francisco Acid Wave
The results can be seen on youtube: https://www.youtube.com/watch?v=oyxSerkkP4o
Mp4 not yet destroyed by youtube compression also at mega.nz together with original video file.
All single processed + unprocessed frames are also at github


Advise also at https://github.com/graphific/DeepDreamVideo/wiki
##INSTALL Dependencies
A good overview (constantly being updated) on which software libraries to install & list of web resources/howto is at reddit: https://www.reddit.com/r/deepdream/comments/3cawxb/what_are_deepdream_images_how_do_i_make_my_own/
##On using a CPU as opposed to GPU
As there's been a lot of interest in using this code, and deepdream in general, on machines without a decent graphic card (GPU), heres a minor benchmark to let you decide if its worth the time on your pc:
(note that the timing also depends on how far down in the layers of the network you want to go: the deeper, the longer time it takes)
GPU K20 (amazon ec2 g2.2xlarge, 2x 4Gb GPU):
1 picture, 540x360px = 1 second = 60 min for 2 min video (3600 frames/framerate 30)
1 picture, 1024x768px = 3 seconds = 3h for 2 min video (3600 frames/framerate 30)
CPU (amazon ec2 g2.2xlarge, Intel Xeon E5-2670 (Sandy Bridge) Processor, 8 cores, 2.6 GHz, 3.3 GHz turbo ):
1 picture, 540x360px = 45 seconds = 1d 21h for 2 min video (3600 frames/framerate 30)
1 picture, 1024x768px = 144 seconds = 6d for 2 min video (3600 frames/framerate 30)
##Usage:
Extract frames from the source movie in the selected format (png or jpg).
./1_movie2frames.sh ffmpeg [original_video] [frames_directory] [png / jpg]
or
./1_movie2frames.sh avconv [original_video] [frames_directory] [png / jpg]
or
./1_movie2frames.sh mplayer [original_video] [frames_directory] [png / jpg]
Let a pretrained deep neural network dream on it frames, one by one, taking each new frame and adding 0-50% of the old frame into it for continuity of the hallucinated artifacts, and go drink your caffe
usage: 2_dreaming_time.py [-h] -i INPUT -o OUTPUT -it IMAGE_TYPE [--gpu GPU]
[-t MODEL_PATH] [-m MODEL_NAME] [-p PREVIEW]
[-oct OCTAVES] [-octs OCTAVESCALE] [-itr ITERATIONS]
[-j JITTER] [-z ZOOM] [-s STEPSIZE] [-b BLEND]
[-l LAYERS [LAYERS ...]] [-v VERBOSE]
[-gi GUIDE_IMAGE] [-sf START_FRAME] [-ef END_FRAME]
Dreaming in videos.
optional arguments:
-h, --help show this help message and exit
-i INPUT, --input INPUT
Input directory where extracted frames are stored
-o OUTPUT, --output OUTPUT
Output directory where processed frames are to be
stored
-it IMAGE_TYPE, --image_type IMAGE_TYPE
Specify whether jpg or png
--gpu GPU Switch for gpu computation.
-t MODEL_PATH, --model_path MODEL_PATH
Model directory to use
-m MODEL_NAME, --model_name MODEL_NAME
Caffe Model name to use
-p PREVIEW, --preview PREVIEW
Preview image width. Default: 0
-oct OCTAVES, --octaves OCTAVES
Octaves. Default: 4
-octs OCTAVESCALE, --octavescale OCTAVESCALE
Octave Scale. Default: 1.4
-itr ITERATIONS, --iterations ITERATIONS
Iterations. Default: 10
-j JITTER, --jitter JITTER
Jitter. Default: 32
-z ZOOM, --zoom ZOOM Zoom in Amount. Default: 1
-s STEPSIZE, --stepsize STEPSIZE
Step Size. Default: 1.5
-b BLEND, --blend BLEND
Blend Amount. Default: "0.5" (constant), or "loop"
(0.5-1.0), or "random"
-l LAYERS [LAYERS ...], --layers LAYERS [LAYERS ...]
Array of Layers to loop through. Default: [customloop]
- or choose ie [inception_4c/output] for that single
layer
-v VERBOSE, --verbose VERBOSE
verbosity [0-3]
-gi GUIDE_IMAGE, --guide_image GUIDE_IMAGE
path to guide image
-sf START_FRAME, --start_frame START_FRAME
starting frame nr
-ef END_FRAME, --end_frame END_FRAME
end frame nr
gpu:
python 2_dreaming_time.py -i frames_directory -o processed_frames_dir --gpu 0
cpu:
python 2_dreaming_time.py -i frames_directory -o processed_frames_dir
different models can be loaded with:
python 2_dreaming_time.py -i frames_directory -o processed_frames_dir --model_path ../caffe/models/Places205-CNN/ --model_name Places205.caffemodel --gpu 0
or
python 2_dreaming_time.py -i frames_directory -o processed_frames_dir --model_path ../caffe/models/bvlc_googlenet/ --model_name bvlc_googlenet.caffemodel --gpu 0
(again eat your heart out, Not a free lunch, but free models are here)
and sticking to one specific layer:
python 2_dreaming_time.py -i frames_directory -o processed_frames_dir -l inception_4c/output --gpu 0
(don't forget the --gpu 0 flag if you got a gpu to run on)
Once enough frames are processed (the script will cut the audio to the needed length automatically) or once all frames are done, put the frames + audio back together:
./3_frames2movie.sh [ffmpeg / avconv / mplayer] [processed_frames_dir] [original_video] [png / jpg]
##Guided Dreaming

command:
python 2_dreaming_time.py -i frames_directory -o processed_frames_dir -l inception_4c/output --guide-image image_file.jpg --gpu 0
or
python 2_dreaming_time.py -i frames_directory -o processed_frames_dir -l inception_4c/output --guide-image image_file.jpg if you're running cpu mode
##Batch Processing with different parameters
python 2_dreaming_time.py -i frames -o processed -l inception_4c/output --guide-image flower.jpg --gpu 0 --start-frame 1 --end-frame 100; python 2_dreaming_time.py -i frames -o processed -l inception_4b/output --guide-image disco.jpg --gpu 0 --start-frame 101 --end-frame 200
##Blending Options The best results come from a well selected blending factor, used to blend each frame into the next, keeping consitancy between the frames and the dreamed up artefacts, but without the added dreamed artefacts overruling the original scene, or in the opposite case, switching too rapidly.
blending can be set by
--blendand can be a float, default 0.5, "random" (a random float between 0.5 and 1., where 1 means disregarding all info from the old frame and starting from scratch with dreaming up artefacts), and "loop" which loops back and forth from 0.5 to 1.0, as originally done in the Fear and Loathing clip.
Constant (default):
python 2_dreaming_time.py -i frames_directory -o processed_frames_dir -b 0.5

Loop:
python 2_dreaming_time.py -i frames_directory -o processed_frames_dir -b loop

Random:
python 2_dreaming_time.py -i frames_directory -o processed_frames_dir -b random
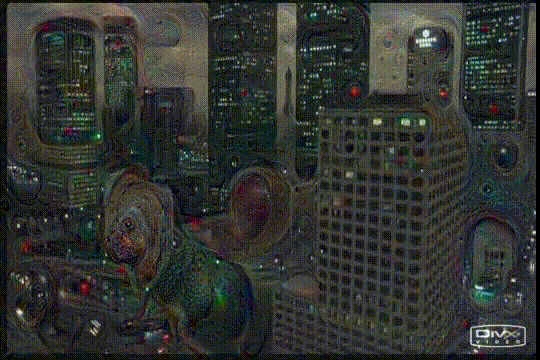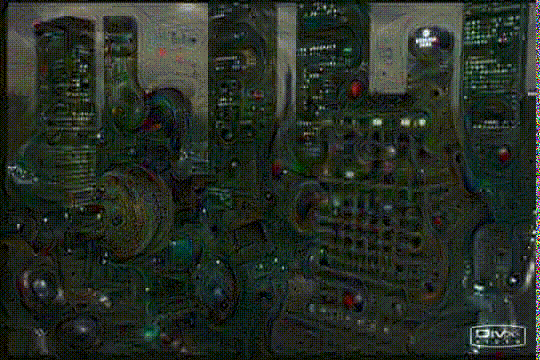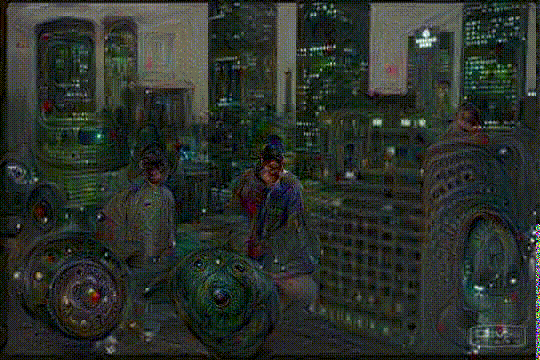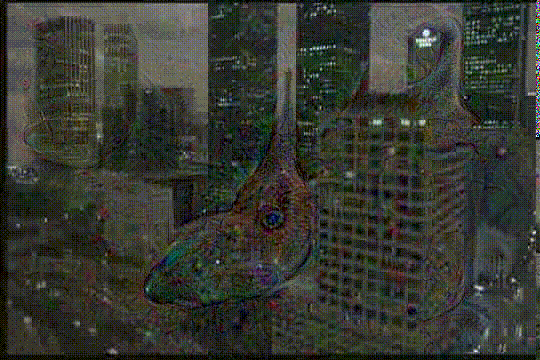
##More information:
This repo implements a deep neural network hallucinating Fear & Loathing in Las Vegas. Visualizing the internals of a deep net we let it develop further what it think it sees.
We're using the #deepdream technique developed by Google, first explained in the Google Research blog post about Neural Network art.
Code:
-
network: standard reference GoogLeNet model trained on ImageNet from the Caffe Model Zoo (https://github.com/BVLC/caffe/wiki/Model-Zoo)
-
iterations: 5
-
jitter: 32 (default)
-
octaves: 4 (default)
-
layers locked to moving upwards from inception_4c/output to inception_5b/output (only the output layers, as they are most sensitive to visualizing "objects", where reduce layers are more like "edge detectors") and back again
-
every next unprocessed frame in the movie clip is blended with the previous processed frame before being "dreamed" on, moving the alpha from 0.5 to 1 and back again (so 50% previous image net created, 50% the movie frame, to taking 100% of the movie frame only). This takes care of "overfitting" on the frames and makes sure we don't iteratively build more and more "hallucinations" of the net and move away from the original movie clip.
https://www.youtube.com/watch?v=6IgbMiEaFRY
-
original Google code is relatively straightforward to use: https://github.com/google/deepdream/blob/master/dream.ipynb
-
gist for osx: https://gist.github.com/robertsdionne/f58a5fc6e5d1d5d2f798
-
docker image: https://registry.hub.docker.com/u/mjibson/deepdream/
-
booting preinstalled ami + installing caffe at amazon: https://github.com/graphific/dl-machine
-
general overview of convolutinal nets using Caffe: https://github.com/graphific/DL-Meetup-intro/blob/master/PyConSe15-cat-vs-dog.ipynb
-
or using lasagne: http://www.slideshare.net/roelofp/python-for-image-understanding-deep-learning-with-convolutional-neural-nets
Roelof | KTH & Graph Technologies | @graphific