
This package is used by ClusOpt for it's CPU intensive tasks, but it can be easily imported in any python data stream clustering project, it is coded mainly in C/C++ with bindings for python, and features:
- CluStream (based on MOA implementation)
- StreamKM++ (wrapped around the original paper authors implementation)
- Distance Matrix computation (in place implementation using boost threads)
- Silhouette score (custom in place implementation inspired by BIRCH clustering vector)
- python >= 3.6
- pip
- boost-thread
- gcc >= 6
boost-thread can be installed in Debian based systems with :
apt install libboost-thread-devSee examples folder for more.
from clusopt_core.cluster import CluStream
from sklearn.datasets import make_blobs
import numpy as np
import matplotlib.pyplot as plt
k = 32
dataset, _ = make_blobs(n_samples=64000, centers=k, random_state=42, cluster_std=0.1)
model = CluStream(
m=k * 10, # no microclusters
h=64000, # horizon
t=2, # radius factor
)
chunks = np.split(dataset, len(dataset) / 4000)
model.init_offline(chunks.pop(0), seed=42)
for chunk in chunks:
model.partial_fit(chunk)
clusters, _ = model.get_macro_clusters(k, seed=42)
plt.scatter(*dataset.T, marker=",", label="datapoints")
plt.scatter(*model.get_partial_cluster_centers().T, marker=".", label="microclusters")
plt.scatter(*clusters.T, marker="x", label="macro clusters", color="black")
plt.legend()
plt.show()output:

Some functions in clusopt_core are faster than scikit learn implementations, see the benchmark folder for more info.
Each bar have a tuple of (no_samples,dimension,no_groups), so independently of those 3 factors, clusopt implementation is faster.
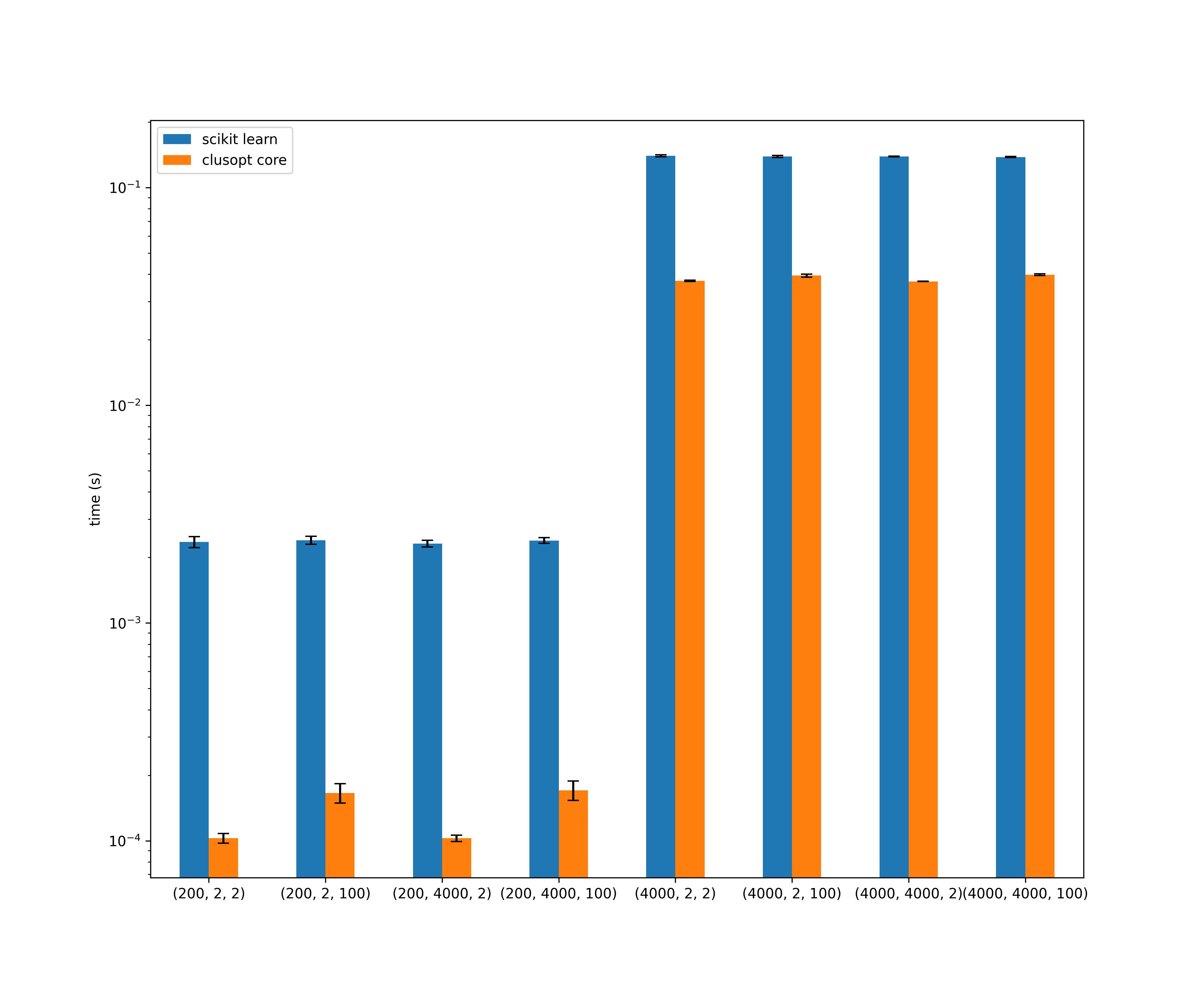
Each bar shows the dataset dimension, so clusopt_core implemetation is faster when the dataset dimension is small (<~150), even when using 4 processes in scikit-learn.

You can install it directly from pypi with
pip install clusopt-coreor you can clone this repo and install from the directory
pip install ./clusopt_core