This document is the essentially setup for cnn-facial-landmark program written by Yin Guobing.
original text link
This is a great implement about the facial-landmark detection and I show the way how I prepared the input data and the running process for the program. You can create the input data step by step by the following context, or download the input data already processed by myself in the following link:resource link
System: Ubuntu 18.04
Installation: python3.6.6, OpenCV(>= v3.4.2), FFmpeg, Jupyter Notebook
(Please refer to the Installation.md.)
The following link is the initial images and pts(contains 68 facial-landmark point).
300-W : In this link, I downloaded 300W,afw,helen,ibug and lfpw.
300-VW:This is .avi file and you can capture images by "transfer_vid_to_jpg.sh" and move all images to a folder(folder name: all-300vw-src) by "transfer_pic.sh".
step 1: Copy all scripts to 300VW folder.
step 2: Executes command "sh transfer_vid_to_jpg.sh" in terminal, and it creates "image folder" on all different folders.
step3: Executes command "sh transfer_pic.sh", and it transfers all pictures to the folder(all-300vw-src).
You can download the source code by git, and replace the "pts_tools.py" with which was modified by me:
$ git clone https://github.com/yinguobing/image_utility.git
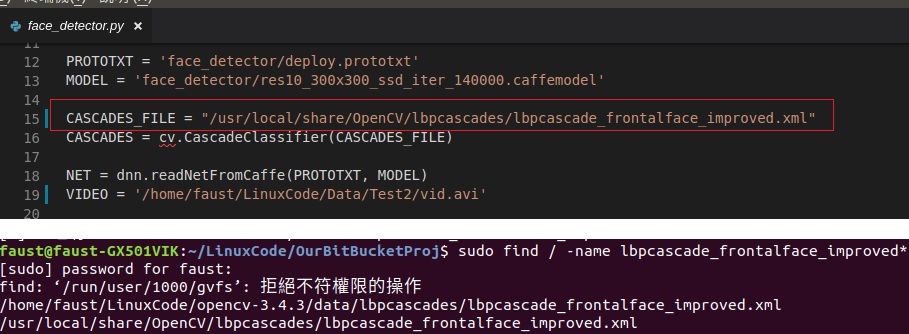
Before you execute "pts_tools.py", it can avoid some build fail that you need to set the "CASCADES_FILE" path for "face_detector.py". You can find your "CASCADES_FILE" path by the following command:
$ find / -name lbpcascade_frontalface_improved*
In my case, CASCADES_FILE = "/usr/local/share/OpenCV/lbpcascades/lbpcascade_frontalface_improved.xml" in face_detector.py.
face_detector:Copy "face_detector" to "image_utility", which can avoid the fail " Can't open "face_detector/deploy.prototxt" in function 'ReadProtoFromTextFile'".
[Fail log]:
It will happen the following if you use opencv under anaconda 3.6.6.
OpenCV(3.4.1) Error: Unspecified error (The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Carbon support. If you are on Ubuntu or Debian, install libgtk2.0-dev and pkg-config, then re-run cmake or configure script) in cvShowImage, file /opt/conda/conda-bld/opencv-suite_1530789967746/work/modules/highgui/src/window.cpp, line 636
[Fix]:
Install pip in anaconda and install opencv-python by pip.
(1) Enter your virtual environment of anaconda (with tensorflow).
$ conda activate tensorflow
(2) Install pip in anaconda
$ conda install pip
(3) Install open-cv by pip which under the anaconda.(Install on VM)
$ /home/faust/.conda/envs/tensorflow/bin/pip install opencv-python
(4) verified if installed successfully on virtual environment.
$ conda list
Name Version Build Channel
opencv-python 3.4.3.18 <pip>
(5) Now you can run python code under anaconda.
Ex:
$ conda activate tensorflow (Enter your python virtual environment.)
$ python3 pts_tool.py
count file: Calculates the total file number.

You can verify the resource by"pts_tool.py" and "extract_face_from_ibug.py" , and enable the red part in the following picture. After verify finished, you should disable this red part.
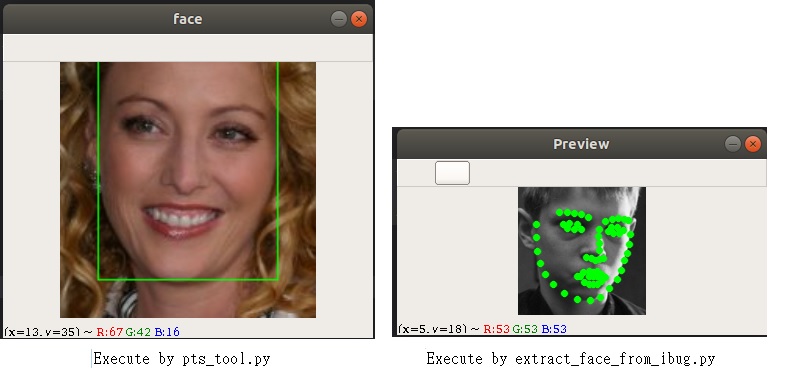
extract face from ibug:It can extract face region for all pictures, and you need to set the following two parameters in this file.
DATA_DIR:The input source file path
TARGET_DIR:The target file path where you want to store.
You can download the source code by git, and change to branch ibug:
$ git clone https://github.com/yinguobing/tfrecord_utility.git
$ git checkout ibug
generate csv:Generate the "data.csv"
Firstly, you should install pandas in anaconda.
$ conda install -c anaconda pandas
$ conda install -c anaconda pillow (Fix "ImportError: No module named PIL" while build generate_records.sh.)
$ cd tfrecord_utility
$ jupyter notebook (It will jump a browser after the command executes.)
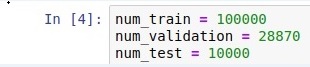
Browser to "split_data.ipynb" and set the value as the following in my case (training images=100000, validation images=28870, test images=10000). Runs all steps until the program runs successfully. Finally, it will split "data.csv" to "data_train.csv","data_validation.csv",and "data_test.csv".
Copy the three csv file to "data folder", and executes "generate_records.sh ". It will generate the three tfrecords:"train.record","validation.record",and " test.record".
You can download the source code by git, and change to branch master:
$ git clone https://github.com/yinguobing/cnn-facial-landmark.git
$ git checkout master
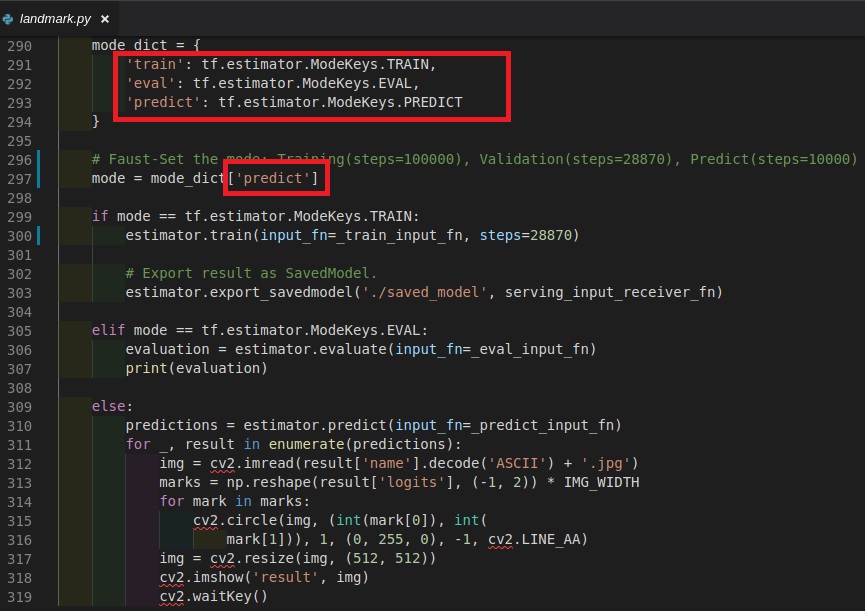
Copy three tfrecords to "cnn-facial-landmark", and set the "mode_dict" sequentially.
train: training mode
eval: validation mode
predict: predict mode
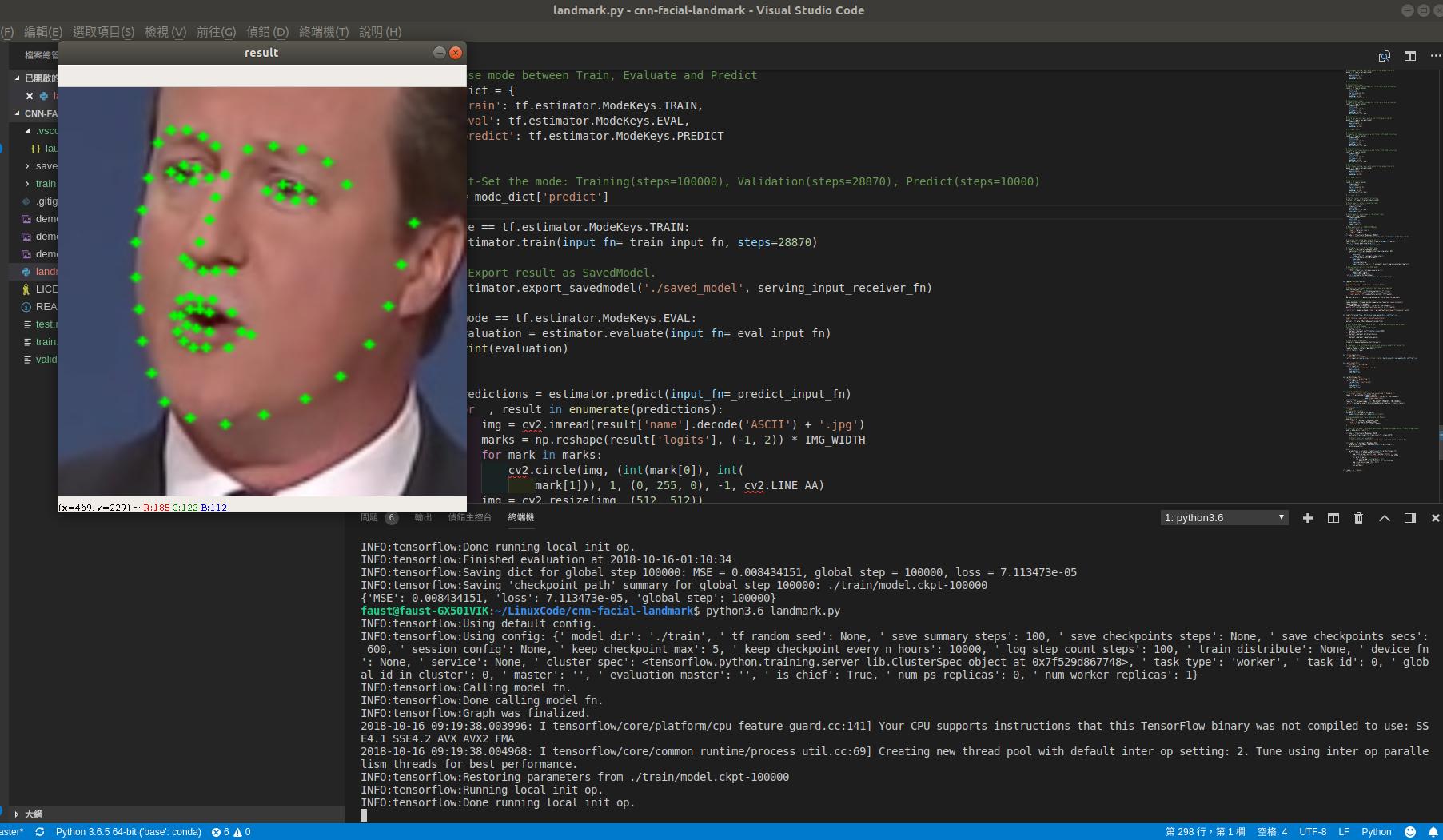
BTW,if it shows the following error during training period, don't care it. It won't affect your result.
......model_fn_results = self._model_fn(features=features, **kwargs) File "landmark.py", line 27, in cnn_model_fn inputs = tf.to_float(features['x'], name="input_to_float") KeyError: 'x'