

![]()
MiniHack is a sandbox framework for easily designing rich and diverse environments for Reinforcement Learning (RL). Based on the game of NetHack, MiniHack uses the NetHack Learning Environment (NLE) to communicate with the game and to provide a convenient interface for customly created RL training and test environments of varying complexity. Check out our NeurIPS 2021 paper and recent blogpost.
MiniHack comes with a large list of challenging environments. However, it is primarily built for easily designing new ones. The motivation behind MiniHack is to be able to perform RL experiments in a controlled setting while being able to increasingly scale the complexity of the tasks.

To do this, MiniHack leverages the so-called description files written using a human-readable probabilistic-programming-like domain-specific language. With just a few lines of code, people can generate a large variety of Gym environments, controlling every little detail, from the location and types of monsters, to the traps, objects, and terrain of the level, all while introducing randomness that challenges generalization capabilities of RL agents. For further details, we refer users to our brief overview, detailed tutorial, or interactive notebook.
Our documentation will walk you through everything you need to know about MiniHack, step-by-step, including information on how to get started, configure environments or design new ones, train baseline agents, and much more.

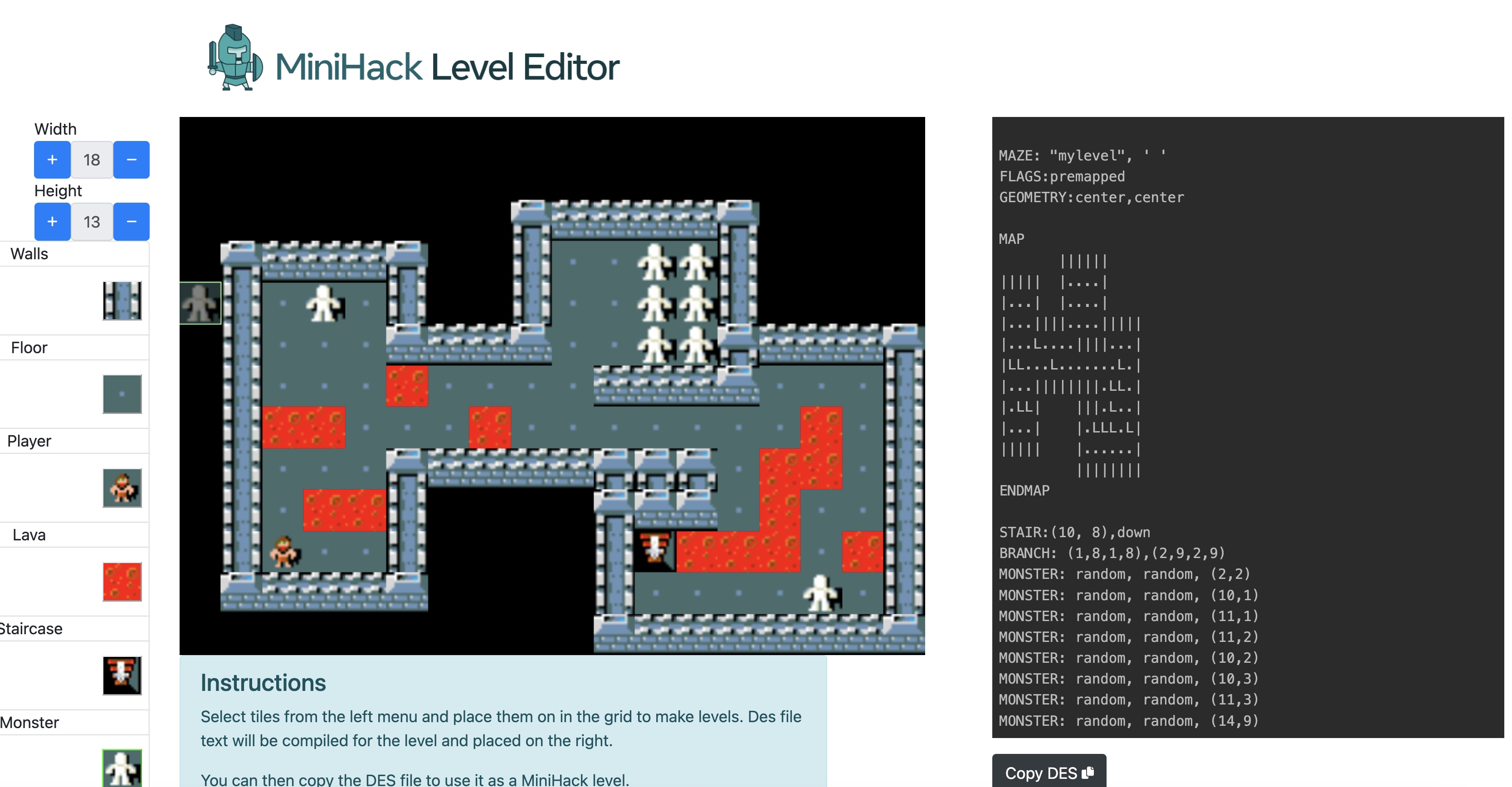
The MiniHack Level Editor allows to easily define MiniHack environments inside a browser using a convenient drag-and-drop functionality. The source code is available here.
We thank ngoodger for implementing the NLE Language Wrapper that translates the non-language observations from Net/MiniHack tasks into similar language representations. Actions can also be optionally provided in text form which are converted to the Discrete actions of the NLE.
- Raparthy et al. Learning to Solve New sequential decision-making Tasks with In-Context Learning (Meta AI, UCL, FMDM 2023)
- Nottingham et al. Selective Perception: Learning Concise State Descriptions for Language Model Actors (UC Irvine, FMDM 2023)
- Prakash et al. LLM Augmented Hierarchical Agents (Maryland, JHU, LangRob 2023)
- Castanyer et al. Improving Intrinsic Exploration by Creating Stationary Objectives (Mila, Ubisoft, Nov 2023)
- Henaff et al. A Study of Global and Episodic Bonuses for Exploration in Contextual MDPs (Meta AI, UCL, ICML 2023)
- Bagaria et al. Scaling Goal-based Exploration via Pruning Proto-goals (Brown, DeepMind, Feb 2023)
- Carvalho et al. Composing Task Knowledge with Modular Successor Feature Approximators (UMich, Oxford, LGAI, ICLR 2023)
- Kessler et al. The Surprising Effectiveness of Latent World Models for Continual Reinforcement Learning (Oxford, Polish Academy of Sciences, DeepRL Workshop 2022)
- Wagner et al. Cyclophobic Reinforcement Learning (HHU Düsseldorf, TU Dortmund, DeepRL Workshop 2022)
- Henaff et al. Integrating Episodic and Global Bonuses for Efficient Exploration (Meta AI, UCL, DeepRL Workshop 2022)
- Jiang et al. Grounding Aleatoric Uncertainty in Unsupervised Environment Design (FAIR, UCL, Berkeley, Oxford, NeurIPS 2022)
- Henaff et al. Exploration via Elliptical Episodic Bonuses (Meta AI, UCL, NeurIPS 2022)
- Mu et al. Improving Intrinsic Exploration with Language Abstractions (Stanford, UW, Meta AI, UCL, NeurIPS 2022)
- Chester et al. Oracle-SAGE: Planning Ahead in Graph-Based Deep Reinforcement Learning (RMIT University, Sept 2022)
- Walker et al. Unsupervised representational learning with recognition-parametrised probabilistic models (UCL, Sept 2022)
- Matthews et al. Hierarchical Kickstarting for Skill Transfer in Reinforcement Learning (UCL, Meta AI, Oxford, CoLLAs 2022)
- Powers et al. CORA: Benchmarks, Baselines, and a Platform for Continual Reinforcement Learning Agents (CMU, Georgia Tech, AI2, CoLLAs 2022)
- Nottingham et al. Learning to Query Internet Text for Informing Reinforcement Learning Agents (UC Irvine, May 2022)
- Matthews et al. SkillHack: A Benchmark for Skill Transfer in Open-Ended Reinforcement Learning (UCL, Meta AI, Oxford, April 2022)
- Parker-Holder et al. Evolving Curricula with Regret-Based Environment Design (Oxford, Meta AI, UCL, Berkeley, ICML 2022)
- Parker-Holder et al. That Escalated Quickly: Compounding Complexity by Editing Levels at the Frontier of Agent Capabilities (Oxford, FAIR, UCL, Berkeley, DeepRL Workshop 2021)
- Samvelyan et al. MiniHack the Planet: A Sandbox for Open-Ended Reinforcement Learning Research (FAIR, UCL, Oxford, NeurIPS 2021)
Open a pull request to add papers.
The simplest way to install MiniHack is through pypi:
pip install minihackIf you wish to extend MiniHack, please install the package as follows:
git clone https://github.com/facebookresearch/minihack
cd minihack
pip install -e ".[dev]"
pre-commit installSee the full installation guide for further information on installing and extending MiniHack on different platforms, as well as pre-installed Dockerfiles.
For submitting your own MiniHack-based environment to our zoo of public environments, please follow the instructions here.
MiniHack uses the popular Gym interface for the interactions between the agent and the environment. A pre-registered MiniHack environment can be used as follows:
import gym
import minihack
env = gym.make("MiniHack-River-v0")
env.reset() # each reset generates a new environment instance
env.step(1) # move agent '@' north
env.render()To see the list of all MiniHack environments, run:
python -m minihack.scripts.env_listThe following scripts allow to play MiniHack environments with a keyboard:
# Play the MiniHack in the Terminal as a human
python -m minihack.scripts.play --env MiniHack-River-v0
# Use a random agent
python -m minihack.scripts.play --env MiniHack-River-v0 --mode random
# Play the MiniHack with graphical user interface (gui)
python -m minihack.scripts.play_gui --env MiniHack-River-v0NOTE: If the package has been properly installed one could run the scripts above with mh-envs, mh-play, and mh-guiplay commands.
In order to get started with MiniHack environments, we provide a variety of baselines agent integrations.
A TorchBeast agent is
bundled in minihack.agent.polybeast together with a simple model to provide
a starting point for experiments. To install and train this agent, first
install torchbeast by following the instructions here,
then use the following commands:
pip install -e ".[polybeast]"
python -m minihack.agent.polybeast.polyhydra env=MiniHack-Room-5x5-v0 total_steps=100000More information on running our TorchBeast agents, and instructions on how to reproduce the results of the paper, can be found here. The learning curves for all of our polybeast experiments can be accessed in our Weights&Biases repository.
An RLlib agent is
provided in minihack.agent.rllib, with a similar model to the torchbeast agent.
This can be used to try out a variety of different RL algorithms. To install and train an RLlib agent, use the following
commands:
pip install -e ".[rllib]"
python -m minihack.agent.rllib.train algo=dqn env=MiniHack-Room-5x5-v0 total_steps=1000000More information on running RLlib agents can be found here.
MiniHack also enables research in Unsupervised Environment Design, whereby an adaptive task distribution is learned during training by dynamically adjusting free parameters of the task MDP.
Check out the ucl-dark/paired repository for replicating the examples from the paper using the PAIRED.
If you use MiniHack in your work, please cite:
@inproceedings{samvelyan2021minihack,
title={MiniHack the Planet: A Sandbox for Open-Ended Reinforcement Learning Research},
author={Mikayel Samvelyan and Robert Kirk and Vitaly Kurin and Jack Parker-Holder and Minqi Jiang and Eric Hambro and Fabio Petroni and Heinrich Kuttler and Edward Grefenstette and Tim Rockt{\"a}schel},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1)},
year={2021},
url={https://openreview.net/forum?id=skFwlyefkWJ}
}
If you use our example ported environments, please cite the original papers: MiniGrid (see license, bib), Boxoban (see license, bib).
MiniHack was built and is maintained by Meta AI (FAIR), UCL DARK and University of Oxford. We welcome contributions to MiniHack. If you are interested in contributing, please see this document. Our maintenance plan can be found here.









