Here you'll find a basic python script to retrieve data behind the trajectories plotted on the Google Ngram Viewer. A Python script that creates XKCD style plots from the ngram CSV data is also included, making it simple to create some awesome looking plots!
- matplotlib >= 1.3.1
- pandas
- requests
Simply type the same query you would type at the Google Ngram Viewer and retrieve the data in csv format.

- By default, the data is printed on screen and saved to a file in the working directory.
- Add the
-plotoption to your query and an XKCD style plot like the one to the left will be saved in the working directory as well. - Searches are case-sensitive by default. To perform case-insenitive searches, pass the
-caseInsensitiveoption to your query. The result will be the sum of all common formats of the query (lowercase, uppercase, titlecase, etc). - The syntax for modifier and wildcard searches has been slightly modified in order to make the script work as a command line tool. See below for more information on these minor changes.
- corpus [default: eng_2012] This will run the query in CORPUS. Possible values are recapitulated below and here.
- startYear [default: 1800]
- endYear [default: 2000]
- smoothing [default: 3] Smoothing parameter (integer)
- caseInsensitive Return case-insensitive results
- plot Return an XKCD style plot as a .png file
- alldata Return every column of available data**
- nosave Results will not be saved to file
- noprint Results will not be printed on screen
- help Prints this screen
** This can be used with inflection, wildcard, and case-insensitive searches (otherwise it does nothing) where one column is the sum of some of the other columns (labeled with a column name ending in "(All)" or an asterisk for wildcard searches). In the Google Ngram Viewer, the columns whose sum makes up this column is viewable by right clicking on the ngram plot. In the getngrams.py script, these columns are dropped by default, but you can keep them by adding -alldata to your query.
There are tons of examples below that demonstrate of all kinds of available queries.
Here are some basic example uses of getngrams.py:
python getngrams.py Albert Einstein, Charles Darwin
python getngrams.py aluminum, copper, steel -noprint
python getngrams.py Pearl Harbor, Watergate -corpus=eng_2009
python getngrams.py bells and whistles -startYear=1900 -endYear=2001 -smoothing=2
python getngrams.py internet --startYear=1980 --endYear=2000 --corpus=eng_2012 -caseInsensitive
As in the full Google Ngram Viewer, you can also perform wildcard searches using getngrams.py.
When doing a wildcard search, use the ? character instead of the * character. Using an asterisk will cause the getngrams.py script to fail because your shell will expand the asterisk before Python has a chance to see it.
python getngrams.py United ? --startYear=1850 --endYear=2000 -alldata
python getngrams.py University of ?
python getngrams.py University of ?, ? State University -alldata
Modifier searches let you see how often one more modifies another word. The usual syntax for doing a modifier search is by using the => operator. For example, running the query dessert=>tasty would match all instances of when the word tasty was used to modify the word dessert.
Modifier searches can be done using getngrams.py, but you must replace the => operator with the @ character.
python getngrams.py car@fast -startYear=1900 -endYear=2000
python getngrams.py car@fast -startYear=1900 -endYear=2000 -alldata
python getngrams.py drink@?_NOUN -startYear=1900 -endYear=2000 -alldata
For more information on wildcard and modifier searches, take a look at the About Ngram Viewer page for more in depth documentation.
python getngrams.py book ? hotel, book_INF a hotel --startYear=1920 --endYear=2000 -alldata
python getngrams.py read ?_DET book
python getngrams.py _DET_ bright_ADJ rainbow
python getngrams.py _START_ President ?_NOUN
python getngrams.py _ROOT_@will
eng_2012, eng_2009, eng_us_2012, eng_us_2009, eng_gb_2012, eng_gb_2009, chi_sim_2012, chi_sim_2009, fre_2012,
fre_2009, ger_2012, ger_2009, spa_2012, spa_2009, rus_2012, rus_2009, heb_2012, heb_2009, ita_2012,
eng_fiction_2012, eng_fiction_2009, eng_1m_2009
There are 2 easy ways to create your own plots using a CSV file produced by running a query with getngrams.py. To demonstrate the 2 methods, we'll run the following query:
python getngrams.py railroad,radio,television,internet -startYear=1900 -endYear=2000 -caseInsensitiveThe first way to create a plot is to use the supplied xkcd.py script to generate awesome XKCD style charts. However, there are two ways to use the script:
- Add the
-plotoption to your command when runninggetngrams.py:
python getngrams.py railroad,radio,television,internet -startYear=1900 -endYear=2000 -plot -caseInsensitive- You can also use
xkcd.pydirectly by passing the CSV file as an argument:
python xkcd.py railroad_radio_television_internet-eng_2012-1900-2000-3-caseInsensitive.csvBoth methods produce the same chart:

Another way to plot data from an ngram CSV file is to read the file into a pandas DataFrame object and call the .plot() option on it. Here we do that, but also convert the data to percentages first and add a title to the plot:
from pandas import read_csv
df = read_csv('railroad_radio_television_internet-eng_2012-1900-2000-3-caseInsensitive.csv',
index_col=0,
parse_dates=True)
for col in df.columns:
df[col] = [i*100 for i in df[col]]
df.plot(title='Railroad, Radio, Television, and Internet')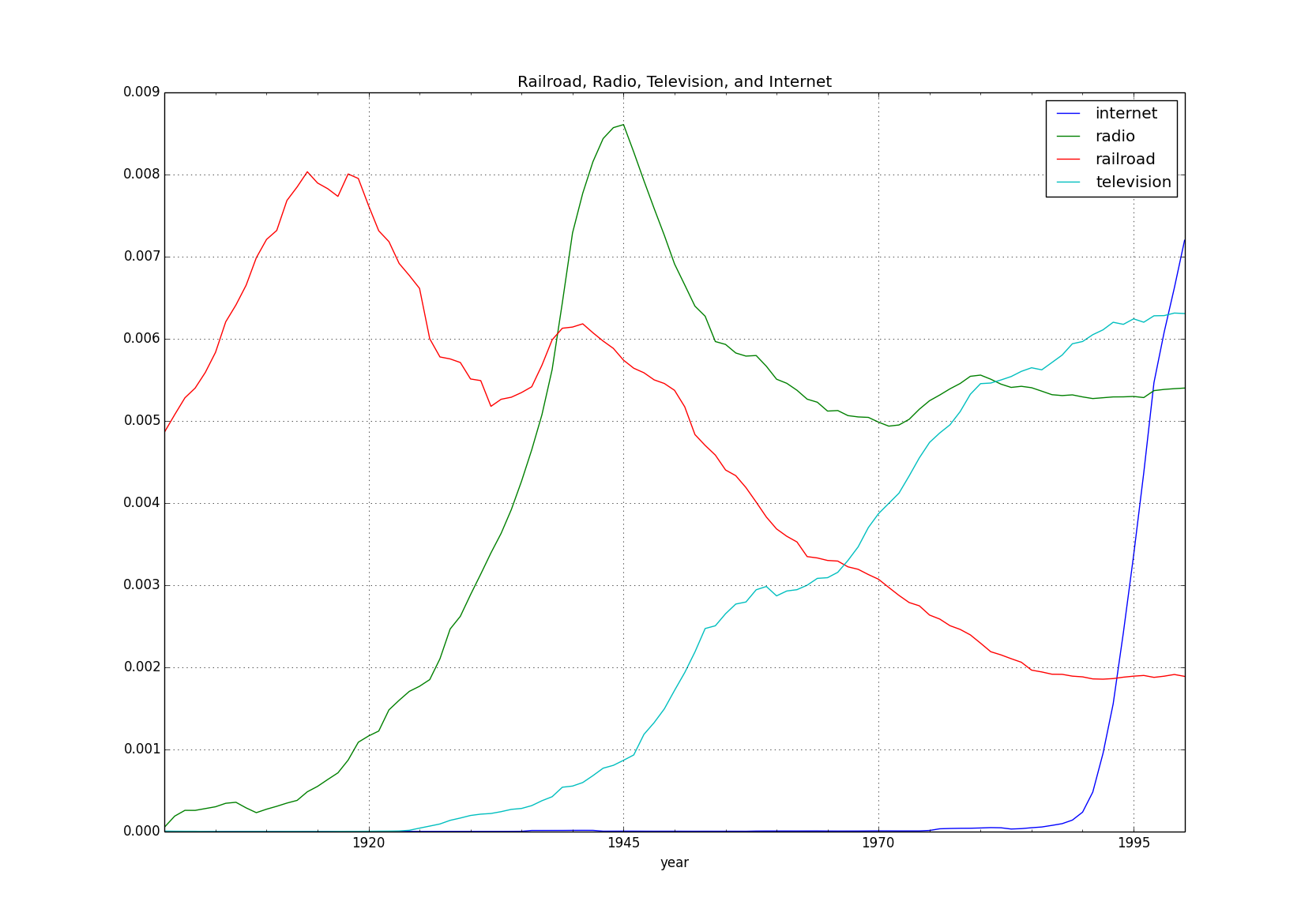
MIT License
Moreover, PLEASE do respect the terms of service of the Google Ngram Viewer while using this code. This code is meant to help viewers retrieve data behind a few queries, not bang at Google's servers with thousands of queries. The complete dataset can be freely downloaded here. This code is not a Google product and is not endorsed by Google in any way.
With this in mind... happy plotting!