-
🔭 I’m currently working on Data Science, Graph Models, Community Data Models
-
👨💻 All of my projects are available at https://github.com/drshyamsundaram
-
📝 I regularly write articles on linkedin.com/in/bioenable
-
📫 How to reach me [email protected]
-
📄 Know about my experiences linkedin.com/in/bioenable
![]()
![]()
Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves. Challenges in natural language processing frequently involve speech recognition, natural language understanding, and natural language generation. Reference
What is NLP ? Natural Language Processing(NLP), a field of AI, aims to understand the semantics and connotations of natural human languages. It focuses on extracting meaningful information from text and train data models based on the acquired insights. The primary NLP functions include text mining, text classification, text analysis, sentiment analysis, word sequencing, speech recognition & generation, machine translation, and dialog systems, to name a few.
The fundamental aim of NLP libraries is to simplify text preprocessing. A good NLP library should be able to correctly convert free text sentences into structured features (for example, cost per hour) that can easily be fed into ML or DL pipelines. Also, an NLP library should have a simple-to-learn API, and it must be able to implement the latest and greatest algorithms and models efficiently.
Libraries Reference
Natural Language Toolkit (NLTK) Gensim CoreNLP spaCy TextBlob Pattern PyNLPl
NLTK is one of the leading platforms for building Python programs that can work with human language data. It presents a practical introduction to programming for language processing. NLTK comes with a host of text processing libraries for sentence detection, tokenization, lemmatization, stemming, parsing, chunking, and POS tagging.
Gensim is a Python library designed specifically for “topic modeling, document indexing, and similarity retrieval with large corpora.” All algorithms in Gensim are memory-independent, w.r.t., the corpus size, and hence, it can process input larger than RAM. With intuitive interfaces, Gensim allows for efficient multicore implementations of popular algorithms, including online Latent Semantic Analysis (LSA/LSI/SVD), Latent Dirichlet Allocation (LDA), Random Projections (RP), Hierarchical Dirichlet Process (HDP) or word2vec deep learning.
Gensim features extensive documentation and Jupyter Notebook tutorials. It largely depends on NumPy and SciPy for scientific computing. Thus, you must install these two Python packages before installing Gensim.
spaCy is an open-source NLP library in Python. It is designed explicitly for production usage – it lets you develop applications that process and understand huge volumes of text.
spaCy can preprocess text for Deep Learning. It can be be used to build natural language understanding systems or information extraction systems. spaCy is equipped with pre-trained statistical models and word vectors. It can support tokenization for over 49 languages. spaCy boasts of state-of-the-art speed, parsing, named entity recognition, convolutional neural network models for tagging, and deep learning integration.
TextBlob is a Python (2 and 3) library for processing textual data. It provides a simple API for diving into common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more. Reference
iNLTK aims to provide out of the box support for various NLP tasks that an application developer might need for Indic languages. Paper for iNLTK library has been accepted at EMNLP-2020's NLP-OSS workshop. Reference Github
The Stanford NLP Group's official Python NLP library. It contains support for running various accurate natural language processing tools on 60+ languages and for accessing the Java Stanford CoreNLP software from Python. For detailed information please visit our official website. Reference Github
Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Google T5, and MarianMT not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively. Reference Github
BERT (Bidirectional Encoder Representations from Transformers) is a recent paper published by researchers at Google AI Language. It has caused a stir in the Machine Learning community by presenting state-of-the-art results in a wide variety of NLP tasks, including Question Answering (SQuAD v1.1), Natural Language Inference (MNLI), and others. Reference Reference
Hugging Face Reference JohnSnowlabs NLP Models Repo Reference OpenAI GPT3 Reference
NLP is hard because natural languages evolved without a standard rule/logic. They were developed in response to the evolution of the human brain: in its ability to understand signs, voice, and memory. With NLP, we are now trying to “discover rules” for something (language) that evolved without rules.
NLP is hard because natural languages evolved without a standard rule/logic. They were developed in response to the evolution of the human brain: in its ability to understand signs, voice, and memory. With NLP, we are now trying to “discover rules” for something (language) that evolved without rules.
Elements of Text Let us now understand various elements of textual data and see how we can extract these using the NLTK library. Now we shall discuss the following elements of the text:
Tokens Vocabulary Punctuation Part of speech Root of a word Base of a word Stop words
A meaningful unit of text is a token. Words are usually considered tokens in NLP. The process of breaking a text based on the token is called tokenization.
The vocabulary of a text is the set of all unique tokens used in it
Punctuation refers to symbols used to separate sentences and their elements and to clarify meaning.
Part of speech(POS) refers to the category to which a word is assigned based on its function. You may recall that the English language has 8 parts of speech – noun, verb, adjective, adverb, pronoun, determiner, preposition, conjunction, and interjection. Different POS taggers are available that classify words into POS. A popular one is the Penn treebank, which has the following parts of speech. POS Image
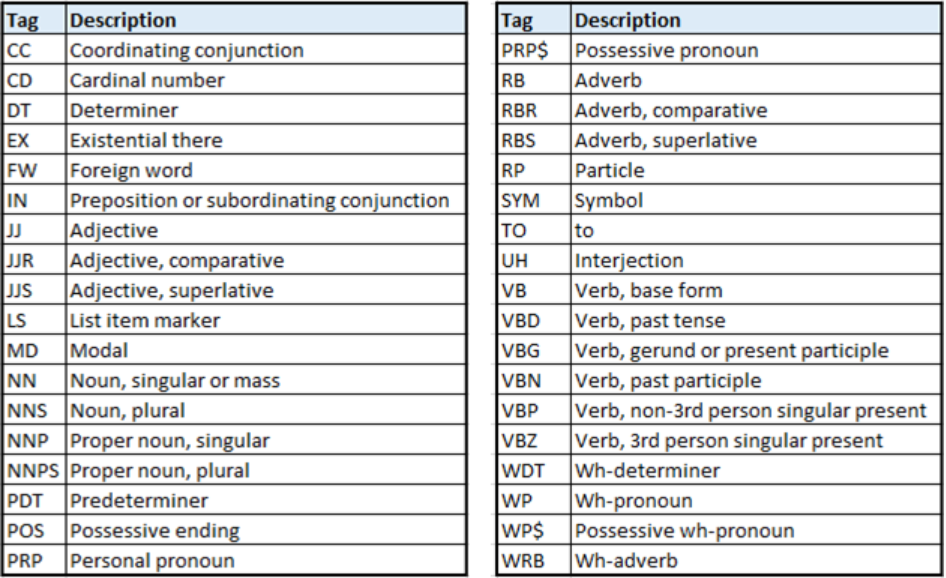{kind=link}
Stemming is a technique used to find the root form of a word. In the root form, a word is devoid of any affixes (suffixes and prefixes)
Lemmatization removes inflection and reduces the word to its base form
Stop words are typically the most commonly occurring words in text like ‘the’, ‘and’, ‘is’, etc. NLTK provides a pre-defined set of stopwords for English, as shown
Frequency distribution helps understand which words are commonly used and which are not. These can help refine stop words in a given text.
Conditional Frequency Distributions can help in identifying differences in the usage of words in different texts. For example, commonly used words in books/articles on the “romance” genre could be different from words used in books/articles of the “news” genre. An example with nltk library to get the conditional frequency distribution of words. Here we use the Brown corpus. Reference
N-gram is a contiguous sequence of n items from a given sample of text or speech. NLTK provides methods to extract n-grams from text
How it works A-Z Searches in the input string for characters that exist between A and Z a-z Searches in the input string for characters that exist between a and z ? Number of occurrences of the character preceding the? can be 0 or 1 . Denotes any character either alphabet or number or special characters The number of occurrences of the character preceding the + can be at least 1 or more w Denotes a set of alphanumeric characters(both upper and lower case) and ‘_’ s Denotes a set of all space-related characters
Named-entity recognition is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc. Reference
Refers to locating and identifying key entities (e.g., company names, product names, location names) within text. NER is an important component of many language applications and is usually the first step in information extraction projects. Reference 2021 NLP Survey Report By Ben Lorica and Paco Nathan
The Corpus of Linguistic Acceptability (CoLA) in its full form consists of 10657 sentences from 23 linguistics publications, expertly annotated for acceptability (grammaticality) by their original authors. The public version provided here contains 9594 sentences belonging to training and development sets, and excludes 1063 sentences belonging to a held out test set. Contact alexwarstadt [at] gmail [dot] com with any questions or issues. Read the paper or check out the source code for baselines. Reference Reference
Transformers (Reference
A transformer is a deep learning model that adopts the mechanism of self-attention, differentially weighting the significance of each part of the input data. It is used primarily in the field of natural language processing (NLP) and in computer vision (CV).
Like recurrent neural networks (RNNs), transformers are designed to handle sequential input data, such as natural language, for tasks such as translation and text summarization. However, unlike RNNs, transformers do not necessarily process the data in order. Rather, the attention mechanism provides context for any position in the input sequence. For example, if the input data is a natural language sentence, the transformer does not need to process the beginning of the sentence before the end. Rather, it identifies the context that confers meaning to each word in the sentence. This feature allows for more parallelization than RNNs and therefore reduces training times.
Since their debut in 2017, transformers are increasingly the model of choice for NLP problems, replacing RNN models such as long short-term memory (LSTM). The additional training parallelization allows training on larger datasets than was once possible. This led to the development of pretrained systems such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), which were trained with large language datasets, such as the Wikipedia Corpus and Common Crawl, and can be fine-tuned for specific tasks.
BERT Reference
Bidirectional Encoder Representations from Transformers (BERT) is a transformer-based machine learning technique for natural language processing (NLP) pre-training developed by Google. BERT was created and published in 2018 by Jacob Devlin and his colleagues from Google. In 2019, Google announced that it had begun leveraging BERT in its search engine, and by late 2020 it was using BERT in almost every English-language query. A 2020 literature survey concluded that "in a little over a year, BERT has become a ubiquitous baseline in NLP experiments", counting over 150 research publications analyzing and improving the model.
The original English-language BERT has two models: (1) the BERTBASE: 12 Encoders with 12 bidirectional self-attention heads, and (2) the BERTLARGE: 24 Encoders with 16 bidirectional self-attention heads. Both models are pre-trained from unlabeled data extracted from the BooksCorpus with 800M words and English Wikipedia with 2,500M words.
A Primer in BERTology: What we know about how BERT works| Rogers, Anna; Kovaleva, Olga; Rumshisky, Anna (2020) Reference
DIY Practical guide on Transformer. Hands-on proven PyTorch code for Intent Classification in NLU with BERT fine-tuned. Reference