![]()
![]()




TRUNAJOD is a Python library for text complexity analysis build on the
high-performance spaCy library. With all the basic NLP capabilities provided by
spaCy (dependency parsing, POS tagging, tokenizing), TRUNAJOD focuses on extracting
measurements from texts that might be interesting for different applications and use cases.
While most of the indices could be computed for different languages, currently we mostly support
Spanish. We are happy if you contribute with indices implemented for your language!
- Utilities for text processing such as lemmatization, POS checkings.
- Semantic measurements from text such as average coherence between sentences and average synonym overlap.
- Giveness measurements such as pronoun density and pronoun noun ratio.
- Built-in emotion lexicon to compute emotion calculations based on words in the text.
- Lexico-semantic norm dataset to compute lexico-semantic variables from text.
- Type token ratio (TTR) based metrics, and tunnable TTR metrics.
- A built-in syllabizer (currently only for spanish).
- Discourse markers based measurements to obtain measures of connectivity inside the text.
- Plenty of surface proxies of text readability that can be computed directly from text.
- Measurements of parse tree similarity as an approximation to syntactic complexity.
- Parse tree correction to add periphrasis and heuristics for clause count, all based on linguistics experience.
- Entity Grid and entity graphs model implementation as a measure of coherence.
- An easy to use and user-friendly API.
TRUNAJOD can be installed by running pip install trunajod. It requires Python 3.6.2+ to run.
Using this package has some other pre-requisites. It assumes that you already have your model set up on spacy. If not, please first install or download a model (for Spanish users, a spanish model). Then you can get started with the following code snippet.
You can download pre-build TRUNAJOD models from the repo, under the models directory.
Below is a small snippet of code that can help you in getting started with this lib. Don´t forget to take a look at the documentation.
The example below assumes you have the es_core_news_sm spaCy Spanish model installed. You can install the model running: python -m spacy download es_core_news_sm. For other models, please check spaCy docs.
from TRUNAJOD import surface_proxies
from TRUNAJOD.entity_grid import EntityGrid
from TRUNAJOD.lexico_semantic_norms import LexicoSemanticNorm
import pickle
import spacy
import tarfile
class ModelLoader(object):
"""Class to load model."""
def __init__(self, model_file):
tar = tarfile.open(model_file, "r:gz")
self.crea_frequency = {}
self.infinitive_map = {}
self.lemmatizer = {}
self.spanish_lexicosemantic_norms = {}
self.stopwords = {}
self.wordnet_noun_synsets = {}
self.wordnet_verb_synsets = {}
for member in tar.getmembers():
f = tar.extractfile(member)
if "crea_frequency" in member.name:
self.crea_frequency = pickle.loads(f.read())
if "infinitive_map" in member.name:
self.infinitive_map = pickle.loads(f.read())
if "lemmatizer" in member.name:
self.lemmatizer = pickle.loads(f.read())
if "spanish_lexicosemantic_norms" in member.name:
self.spanish_lexicosemantic_norms = pickle.loads(f.read())
if "stopwords" in member.name:
self.stopwords = pickle.loads(f.read())
if "wordnet_noun_synsets" in member.name:
self.wordnet_noun_synsets = pickle.loads(f.read())
if "wordnet_verb_synsets" in member.name:
self.wordnet_verb_synsets = pickle.loads(f.read())
# Load TRUNAJOD models
model = ModelLoader("trunajod_models_v0.1.tar.gz")
# Load spaCy model
nlp = spacy.load("es_core_news_sm", disable=["ner", "textcat"])
example_text = (
"El espectáculo del cielo nocturno cautiva la mirada y suscita preguntas"
"sobre el universo, su origen y su funcionamiento. No es sorprendente que "
"todas las civilizaciones y culturas hayan formado sus propias "
"cosmologías. Unas relatan, por ejemplo, que el universo ha"
"sido siempre tal como es, con ciclos que inmutablemente se repiten; "
"otras explican que este universo ha tenido un principio, "
"que ha aparecido por obra creadora de una divinidad."
)
doc = nlp(example_text)
# Lexico-semantic norms
lexico_semantic_norms = LexicoSemanticNorm(
doc,
model.spanish_lexicosemantic_norms,
model.lemmatizer
)
# Frequency index
freq_index = surface_proxies.frequency_index(doc, model.crea_frequency)
# Clause count (heurístically)
clause_count = surface_proxies.clause_count(doc, model.infinitive_map)
# Compute Entity Grid
egrid = EntityGrid(doc)
print("Concreteness: {}".format(lexico_semantic_norms.get_concreteness()))
print("Frequency Index: {}".format(freq_index))
print("Clause count: {}".format(clause_count))
print("Entity grid:")
print(egrid.get_egrid())This should output:
Concreteness: 1.95
Frequency Index: -0.7684649336888104
Clause count: 10
Entity grid:
{'ESPECTÁCULO': ['S', '-', '-'], 'CIELO': ['X', '-', '-'], 'MIRADA': ['O', '-', '-'], 'UNIVERSO': ['O', '-', 'S'], 'ORIGEN': ['X', '-', '-'], 'FUNCIONAMIENTO': ['X', '-', '-'], 'CIVILIZACIONES': ['-', 'S', '-'], 'CULTURAS': ['-', 'X', '-'], 'COSMOLOGÍAS': ['-', 'O', '-'], 'EJEMPLO': ['-', '-', 'X'], 'TAL': ['-', '-', 'X'], 'CICLOS': ['-', '-', 'X'], 'QUE': ['-', '-', 'S'], 'SE': ['-', '-', 'O'], 'OTRAS': ['-', '-', 'S'], 'PRINCIPIO': ['-', '-', 'O'], 'OBRA': ['-', '-', 'X'], 'DIVINIDAD': ['-', '-', 'X']}
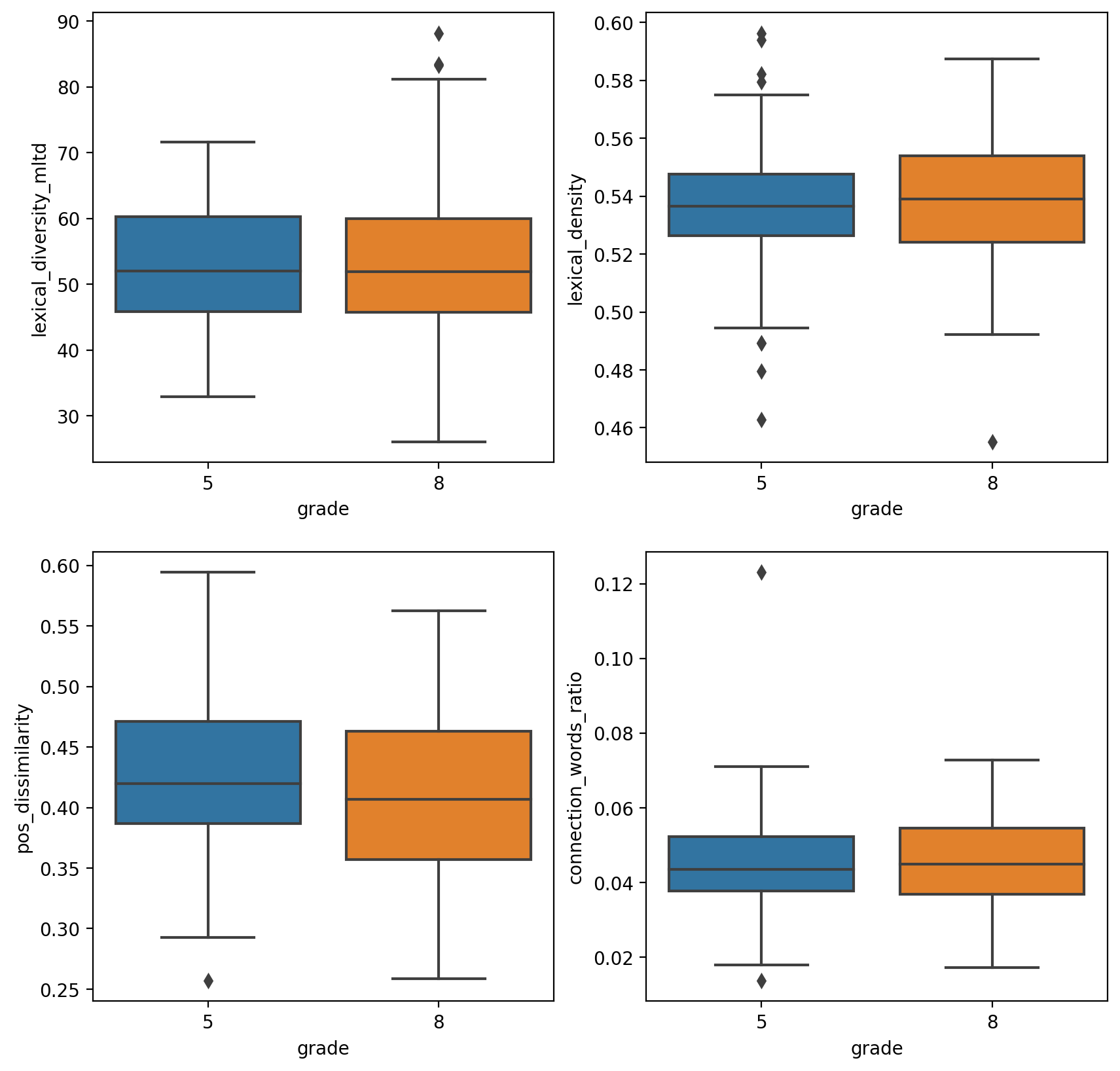
TRUNAJOD lib was used to make TRUNAJOD web app, which is an application to assess text complexity and to check the adquacy of a text to a particular school level. To achieve this, several TRUNAJOD indices were analyzed for multiple Chilean school system texts (from textbooks), and latent features were created. Here is a snippet:
"""Example of TRUNAJOD usage."""
import glob
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import spacy
import textract # To read .docx files
import TRUNAJOD.givenness
import TRUNAJOD.ttr
from TRUNAJOD import surface_proxies
from TRUNAJOD.syllabizer import Syllabizer
plt.rcParams["figure.figsize"] = (11, 4)
plt.rcParams["figure.dpi"] = 200
nlp = spacy.load("es_core_news_sm", disable=["ner", "textcat"])
features = {
"lexical_diversity_mltd": [],
"lexical_density": [],
"pos_dissimilarity": [],
"connection_words_ratio": [],
"grade": [],
}
for filename in glob.glob("corpus/*/*.docx"):
text = textract.process(filename).decode("utf8")
doc = nlp(text)
features["lexical_diversity_mltd"].append(
TRUNAJOD.ttr.lexical_diversity_mtld(doc)
)
features["lexical_density"].append(surface_proxies.lexical_density(doc))
features["pos_dissimilarity"].append(
surface_proxies.pos_dissimilarity(doc)
)
features["connection_words_ratio"].append(
surface_proxies.connection_words_ratio(doc)
)
# In our case corpus was organized as:
# corpus/5B/5_2_55.docx where the folder that
# contained the doc, contained the school level, in
# this example 5th grade
features["grade"].append(filename.split("/")[1][0])
df = pd.DataFrame(features)
fig, axes = plt.subplots(2, 2)
sns.boxplot(x="grade", y="lexical_diversity_mltd", data=df, ax=axes[0, 0])
sns.boxplot(x="grade", y="lexical_density", data=df, ax=axes[0, 1])
sns.boxplot(x="grade", y="pos_dissimilarity", data=df, ax=axes[1, 0])
sns.boxplot(x="grade", y="connection_words_ratio", data=df, ax=axes[1, 1])Which yields:
TRUNAJOD web app backend was built using TRUNAJOD lib. A demo video is shown below (it is in Spanish):
Bug reports and fixes are always welcome! Feel free to file issues, or ask for a feature request. We use Github issue tracker for this. If you'd like to contribute, feel free to submit a pull request. For more questions you can contact me at dipalma (at) udec (dot) cl.
More details can be found in CONTRIBUTING.
If you find anything of this useful, feel free to cite the following papers, from which a lot of this python library was made for (I am also in the process of submitting this lib to an open software journal):
- Palma, D., & Atkinson, J. (2018). Coherence-based automatic essay assessment. IEEE Intelligent Systems, 33(5), 26-36.
- Palma, D., Soto, C., Veliz, M., Riffo, B., & Gutiérrez, A. (2019, August). A Data-Driven Methodology to Assess Text Complexity Based on Syntactic and Semantic Measurements. In International Conference on Human Interaction and Emerging Technologies (pp. 509-515). Springer, Cham.
@article{Palma2021,
doi = {10.21105/joss.03153},
url = {https://doi.org/10.21105/joss.03153},
year = {2021},
publisher = {The Open Journal},
volume = {6},
number = {60},
pages = {3153},
author = {Diego A. Palma and Christian Soto and Mónica Veliz and Bruno Karelovic and Bernardo Riffo},
title = {TRUNAJOD: A text complexity library to enhance natural language processing},
journal = {Journal of Open Source Software}
}
@article{palma2018coherence,
title={Coherence-based automatic essay assessment},
author={Palma, Diego and Atkinson, John},
journal={IEEE Intelligent Systems},
volume={33},
number={5},
pages={26--36},
year={2018},
publisher={IEEE}
}
@inproceedings{palma2019data,
title={A Data-Driven Methodology to Assess Text Complexity Based on Syntactic and Semantic Measurements},
author={Palma, Diego and Soto, Christian and Veliz, M{\'o}nica and Riffo, Bernardo and Guti{\'e}rrez, Antonio},
booktitle={International Conference on Human Interaction and Emerging Technologies},
pages={509--515},
year={2019},
organization={Springer}
}