{kind=link}
{kind=link}
![]()
Schema discovery for JSON Schema draft 2020-12 using monoids. The goal of JSONoid is to produce a useful JSON Schema from a collection of JSON documents. For an idea of what JSONoid does, you can view example schemas with their corresponding datasets or see the example below.
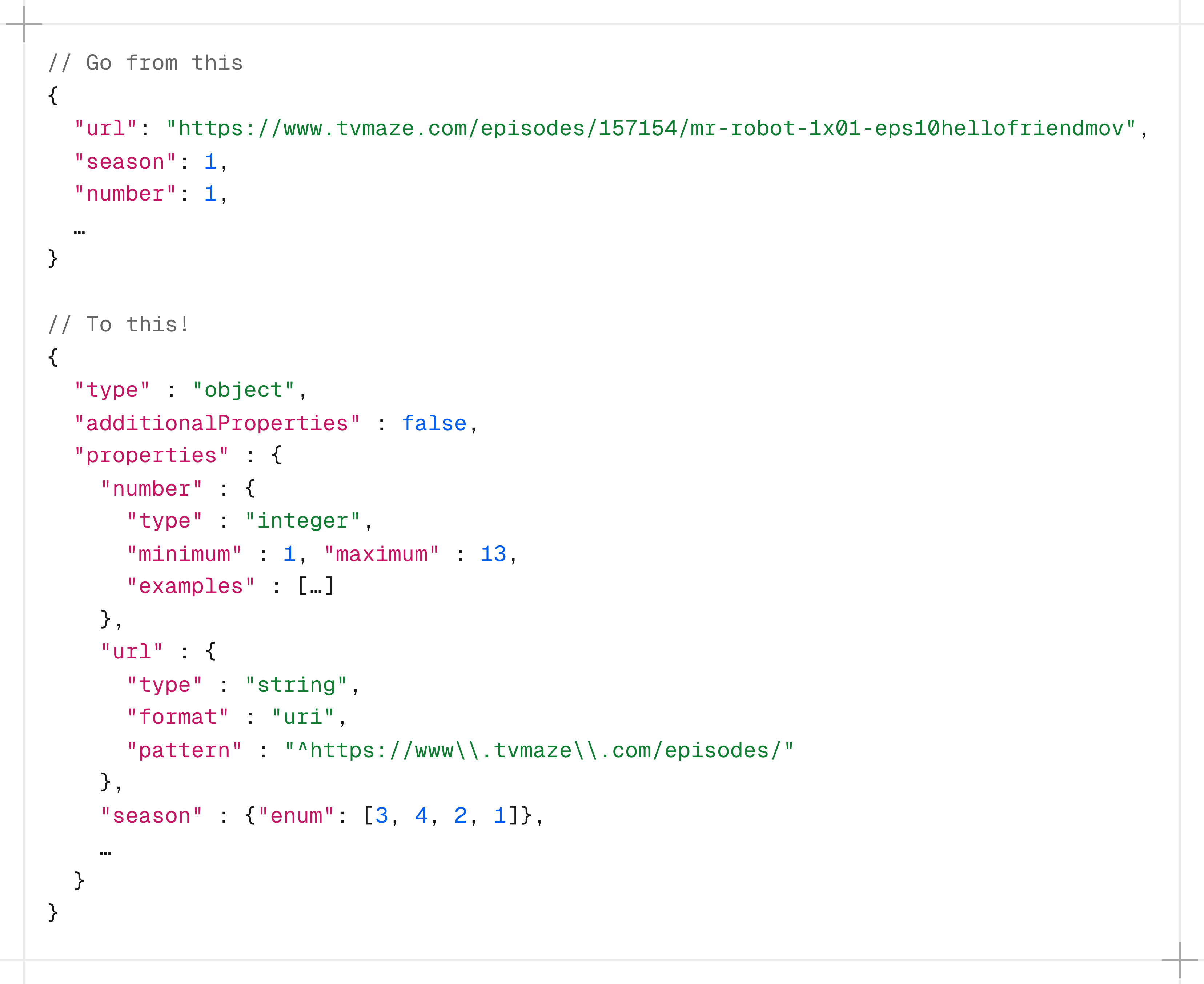
Table of Contents
JSONoid accepts newline-delimited JSON either from standard input or a file.
This means there should be exactly one JSON value per line in the input.
If your JSON is not formatted this way, one option is to use the -c option to jq which can convert files to the appropriate format.
Any invalid JSON will be skipped and not produce an error.
It is therefore recommended to validate the JSON before providing to JSONoid if handling invalid input is required.
The generated schema will be printed JSON Schema as output.
Note that depending on the configuration, JSONoid will add additional properties which are not part of the JSON Schema standard.
The format is described in the JSON Schema Profile draft and is subject to change.
To quickly run jsonoid, you can use the Docker image which is built from the latest commit on the main branch.
Note that by default, jsonoid accepts newline-delimited JSON on standard input, so it will hang waiting for input.
Add the --help option to see possible configuration options.
docker run -i --rm michaelmior/jsonoid-discovery
To simplify, you may wish to add a shell alias so jsonoid can be run directly as a command.
alias jsonoid='docker run -i --rm michaelmior/jsonoid-discovery'
jsonoid --help
To produce a JAR file which is suitable for running either locally or via Spark, run sbt assembly.
This requires an installation of sbt.
Alternatively, you can use ./sbtx assembly to attempt to automatically download install the appropriate sbt and Scala versions using sbt-extras.
This will produce a JAR file under target/scala-2.13/ which can either be run directly or passed to spark-submit to run via Spark.
In JSONoid, the primary way information is collected from a schema is using monoids. A monoid simply stores a piece of information extracted from a JSON document along with information on how to combine together information from all documents in a collection in a scalable way.
The set of monoids (also referred as properties) used for discovery can be controlled using the --prop command line option.
The Min set of monoids will produce only simple type information and nothing more.
Simple extends this set of monoids to cover a large set of keywords supported by JSON Schema.
Finally, All monoids can be enabled to discover the maximum amount of information possible.
Note that for large collections of documents, there may be a performance penalty for using all possible monoids in the discovery process.
For each primitive type, the following monoids are defined.
BloomFilter- A Bloom filter allows for approximate membership testing. The Bloom filters generated are a Base64 encoded serialized library object.Examples- Corresponding to theexamplesJSON Schema keyword, a number of example values will be randomly sampled from the observed documents.HyperLogLog- HyperLogLog allows estimates of the number of unique values of a particular key. As with Bloom filters, the generated value is a Base64 encoded library object.
Histogram,MaxItems,MinItems- Produces a histogram of array size and the maximum and minimum number of elements.Unique- Detects whether elements of an array are unique corresponding to theuniqueItemsJSON Schema keyword.
Histogram,MaxValue,MinValue- A histogram of all values and the maximum and minimum values.MultipleOf- If all numerical values are a multiple of a particular constant, this will be detected using Euclid's GCD algorithm. The corresponds to the JSON SchemamultipleOfkeyword.Stats- Several statistical properties including mean, standard deviation, skewness, and kurtosis are calculated.
Dependencies- In some schemas, a key must exist an object if some other key exists, as in the JSON SchemadependentRequiredkeyword. For example, if acityis provided, it may also be necessary to provide astate.FieldPresence- For keys which are not required, this tracks the percentage of objects which contain this property.Required- This tracks which keys are always present in a schema, suggesting that they are required.
Format- This attempts to infer a value for theformatkeyword. Formats are semantic types of strings such as URLs or email addresses. A string will be labelled with the most common format detected.LengthHistogram,MaxLength,MinLength- Both the minimum and maximum length of strings as well as a histogram of all string lengths will be included.Format- This attempts to infer a value for thepatternkeyword. A pattern is a regular expression which all string values must match. Currently this property simply finds common prefixes and suffixes of strings in the schema.
The concept of equivalence relations was first introduced by Baazizi et al. in Parametric schema inference for massive JSON datasets The idea is that some JSON Schemas may contain some level of variation such as optional values and multiple possible types for a given key. Whether any particular schemas should be considered equivalent is dependent on the particular dataset in question, so this equivalence is configurable.
JSONoid currently supports four equivalence relations (which can be specified using the --equivalence-relation command line option):
-
Kind equivalence (the default) will combine schemas when they are of the same kind, e.g. both objects, regardless of the contents of the objects.
-
Label equivalence will combine object schemas only if they have the same keys, regardless of the value of the key.
-
IntersectingLabel equivalence will combine object schemas if they have any keys in common. This can be helpful when some keys are optional since label equivalence would consider two schemas as different if one is missing an optional key.
-
TypeMatch equivalence will combine object schemas if any keys that they have in common have the same type. Note that this equivalence is shallow, meaning that two values are considered the same type if they are both objects or arrays, without considering the contained types (similar to kind equivalence).
Some useful transformations of schemas can only be applied after the entire schema has been computed. The transformations currently implemented in JSONoid are detailed below.
This transformer will attempt to discover common substructures present in the schema for the purpose of creating reusable definitions.
The transformer will consider common sets of keys which occur across objects in the schema and try to find those which are similar and group them together into adefinition.
This experimental feature is disabled by default and can be enabled with the --add-definitions command line option.
The disjoint object transformer attempts to identify cases in a schema where there are multiple objects at the same location in the schema, but with different sets of keys. Consider for example the set of documents below:
{"a: 1, b: 2"}
{"c: 5, d: 6"}
{"a: 3, b: 4"}
{"c: 7, d: 8"}
In this case, we can see there are two types of objects: those with keys a and b and those with keys c and d.
The disjoint object transformer will attempt to identify these two types of objects and instead of creating a single object schema with multiple keys, create a schema that uses oneOf and includes each option.
This feature is not currently available via the CLI.
This transformer will attempt to identify cases when the keys for an object in the schema are not fixed, but the values have a common schema.
This is commonly implemented using the additonalProperties keyword.
This transformer implements the approach described in the paper Reducing Ambiguity in Json Schema Discovery by Spoth et al.
This is also disabled by default and can be enabled with the --detect-dynamic command line option.
This transformer will attempt to infer a value for the enum keyword.
This is based on examples which were found in the schema.
If only a small number of examples are found, then the set of examples is transformed into an enum.
This transformer is always enabled.
This transformer will find cases in a schema where allOf is used and merge all the schemas together.
This will remove the use of allOf but produce a schema which should accept the same documents.
This is only useful for schemas not generated by JSONoid since JSONoid does not currently generate schemas with allOf.
Accordingly, there is no option for this transformer in the CLI, but may be useful via the API.
JSONoid also supports distributed schema discovery via Apache Spark.
There are two options for running JSONoid on Spark.
The first is to the JsonoidSpark class as your main class when running Spark.
You can either use the JAR file produced via sbt assembly or download from the latest release.
In this case, you can pass a path file path as input and the schema will be written to standard output.
Alternatively, you can use the JsonoidRdd#fromString method to convert an RDD of strings to an RDD of schemas that supports schema discovery via the reduceSchemas or treeReduceSchemas method.
The result of the reduction will be a JsonSchema object.
Tests can be run via ScalaTest via sbt test.
It is also possible to run fuzz tests via Jazzer with ./run-fuzzer.sh.
If you encounter any issues, please open an issue on the GitHub repository. Any potential security vulnerabilities should be reported privately.
JSONoid also contains a partial implementation of a JSON Schema validator. More details on validation can be found in this repository.