The forecast assistant is a customizable application template for building AI-powered forecasts. In addition to creating a hosted and shareable user interface, the forecast assistant provides:
- Best-in-class predictive model training and deployment using DataRobot forecasting.
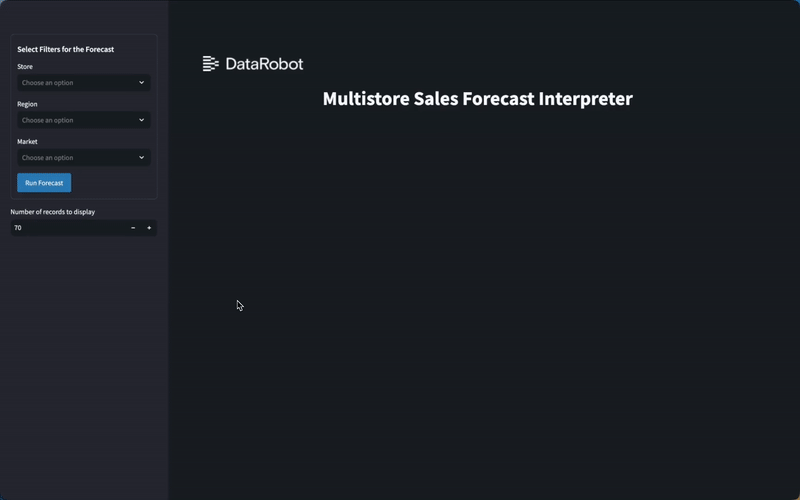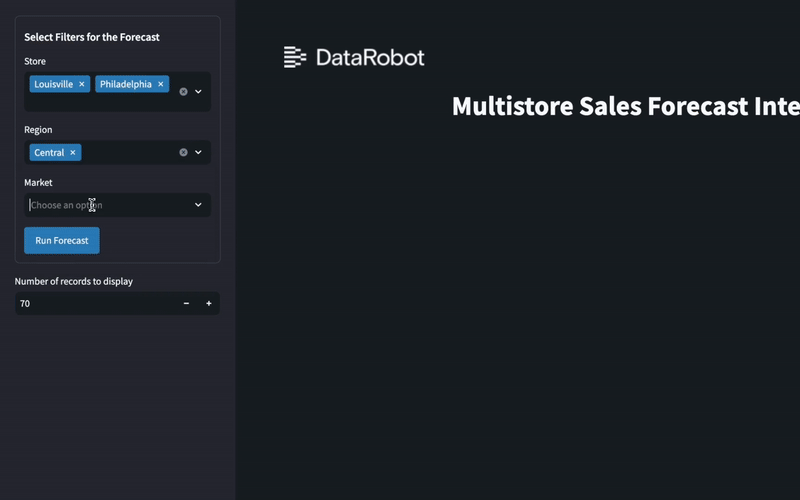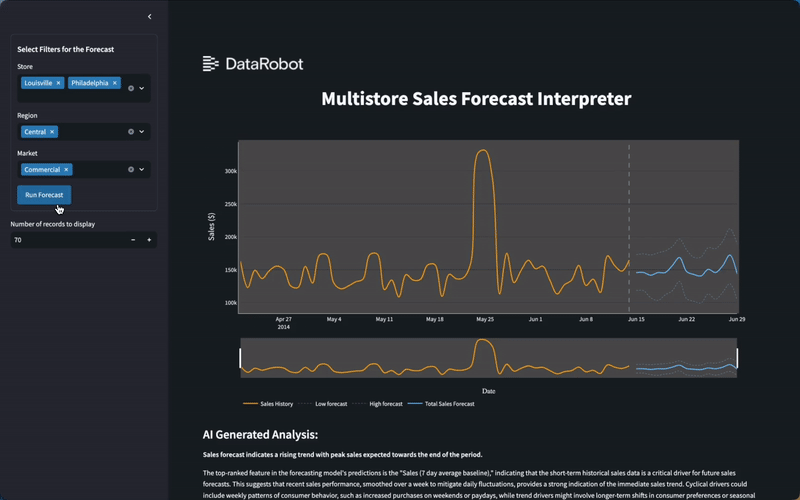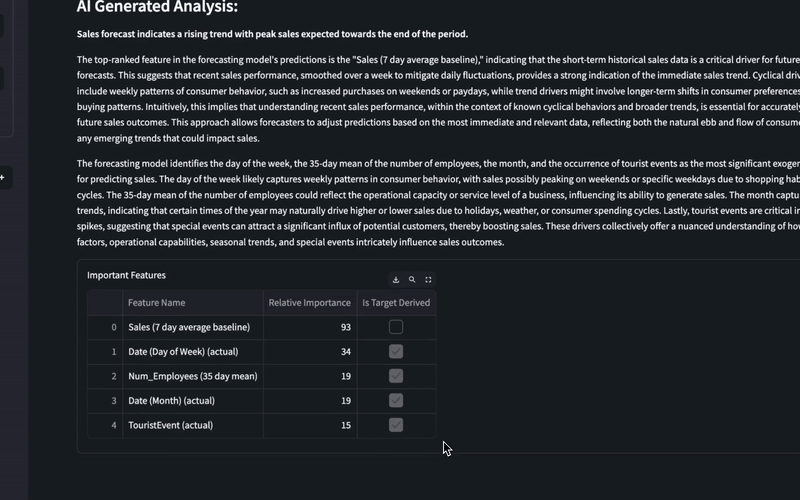
- An intelligent explanation of factors driving the forecast that are uniquely derived for any series at any time.
Warning
Application templates are intended to be starting points that provide guidance on how to develop, serve, and maintain AI applications. They require a developer or data scientist to adapt and modify them to meet business requirements before being put into production.
- Setup
- Architecture overview
- Why build AI Apps with DataRobot app templates?
- Make changes
- Share results
- Delete all resources
- Setup for advanced users
- Data privacy
Important
If you are running this template in a DataRobot codespace, pulumi is already configured and the repository is automatically cloned.
Skip to Step 3.
-
If
pulumiis not already installed, install the CLI following instructions here. After installingpulumifor the first time, restart your terminal and run:pulumi login --local # omit --local to use Pulumi Cloud (requires separate account) -
Clone the template repository.
git clone https://github.com/datarobot-community/forecast-assistant.git cd forecast-assistant -
Rename the file
.env.templateto.envin the root directory of the repo and populate your credentials. This template is pre-configured to use an Azure OpenAI endpoint. If you wish to use a different LLM provider, modifications to the code will be necessary.DATAROBOT_API_TOKEN=... DATAROBOT_ENDPOINT=... # e.g. https://app.datarobot.com/api/v2 # [Optional]: Provide an ID of a dedicated prediction environment - otherwise we create a new serverless prediction environment # DATAROBOT_PREDICTION_ENVIRONMENT_ID=... # dedicated prediction server id from https://app.datarobot.com/console-nextgen/prediction-environments OPENAI_API_KEY=... OPENAI_API_VERSION=... # e.g. 2024-02-01 OPENAI_API_BASE=... # e.g. https://your_org.openai.azure.com/ OPENAI_API_DEPLOYMENT_ID=... # e.g. gpt-4 PULUMI_CONFIG_PASSPHRASE=... # required, choose an alphanumeric passphrase to be used for encrypting pulumi config
Use the following resources to locate the required credentials:
- DataRobot API Token: Refer to the Create a DataRobot API Key section of the DataRobot API Quickstart docs.
- DataRobot Endpoint: Refer to the Retrieve the API Endpoint section of the same DataRobot API Quickstart docs.
- LLM Endpoint and API Key: Refer to the Azure OpenAI documentation.
-
In a terminal, run the following command:
python quickstart.py YOUR_PROJECT_NAME # Windows users may have to use `py` instead of `python`Python 3.9+ is required.
Advanced users who want to control virtual environment creation, dependency installation, environment variable setup
and pulumi invocation, see the advanced setup instructions.

App Templates contain three families of complementary logic. For this template, you can opt-in to fully custom AI logic and a fully custom front-end or utilize DataRobot's off-the-shelf offerings:
- AI logic: Necessary to service AI requests, generate predictions, and manage predictive models.
notebooks/ # Model training logic, scoring data prep logic - App logic: Necessary for user consumption, whether via a hosted front-end or integrating into an external consumption layer.
frontend/ # Streamlit frontend forecastic/ # App biz logic & runtime helpers - Operational logic: Necessary to turn on all DataRobot assets.
__main__.py # Pulumi program for configuring DataRobot to serve and monitor AI & App logic infra/ # Settings for resources and assets created in DataRobot
App templates transform your AI projects from notebooks to production-ready applications. Too often, getting models into production means rewriting code, juggling credentials, and coordinating with multiple tools and teams just to make simple changes. DataRobot's composable AI apps framework eliminates these bottlenecks, letting you spend more time experimenting with your ML and app logic and less time wrestling with plumbing and deployment.
- Start building in minutes: Deploy complete AI applications instantly, then customize AI logic or front-end independently - no architectural rewrites needed.
- Keep working your way: Data scientists keep working in notebooks, developers in IDEs, and configs stay isolated - update any piece without breaking others.
- Iterate with confidence: Make changes locally and deploy with confidence - spend less time writing and troubleshooting plumbing, more time improving your app.
Each template provides an end-to-end AI architecture, from raw inputs to deployed application, while remaining highly customizable for specific business requirements.
-
Edit the following two notebooks:
notebooks/train_model.ipynb: Handles training data ingest and preparation and model training settings.notebooks/prep_scoring_data.ipynb: Handles scoring data preparation (the data used to show forecasts in the front-end).
The last cell of each notebook is required, as it writes outputs needed for the rest of the pipeline.
-
Run the revised notebooks.
-
Run
pulumi upto update your stack with these changes.
source set_env.sh # On windows use `set_env.bat`
pulumi up- For a forecasting app that is continuously updated, consider running
prep_scoring_data.ipynbon a schedule.
- Ensure you have already run
pulumi upat least once (to provision the time series deployment). - Streamlit assets are in
frontend/and can be edited. After provisioning the stack at least once, you can also test the front-end locally usingstreamlit run app.pyfrom thefrontend/directory (don't forget to initialize your environment usingsource set_env.sh).
source set_env.sh # On windows use `set_env.bat`
cd frontend
streamlit run app.py- Run
pulumi upagain to update your stack with the changes.
source set_env.sh # On windows use `set_env.bat`
pulumi upOptionally, you can set the application locale in forecastic/i18n.py, e.g. APP_LOCALE = LanguageCode.JA. Supported locales are Japanese and English, with English set as the default.
- Log into the DataRobot application.
- Navigate to Registry > Applications.
- Navigate to the application you want to share, open the actions menu, and select Share from the dropdown.
pulumi downThen run the jupyter notebook notebooks/delete_non_pulumi_assets.ipynb.
For manual control over the setup process, adapt the following steps for MacOS/Linux to your environent:
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
source set_env.sh
pulumi stack init YOUR_PROJECT_NAME
pulumi up e.g., for Windows/conda/cmd.exe the previous example would change to the following:
conda create --prefix .venv pip
conda activate .\.venv
pip install -r requirements.txt
set_env.bat
pulumi stack init YOUR_PROJECT_NAME
pulumi up For projects that will be maintained, DataRobot recommends forking the repo so upstream fixes and improvements can be merged in the future.
Your data privacy is important to DataRobot. Data handling is governed by the DataRobot Privacy Policy. Review the policy before using your own data with DataRobot.