Babar is a profiler for distributed applications developed to profile large-scale distributed applications such as Spark, Scalding, MapReduce or Hive programs.
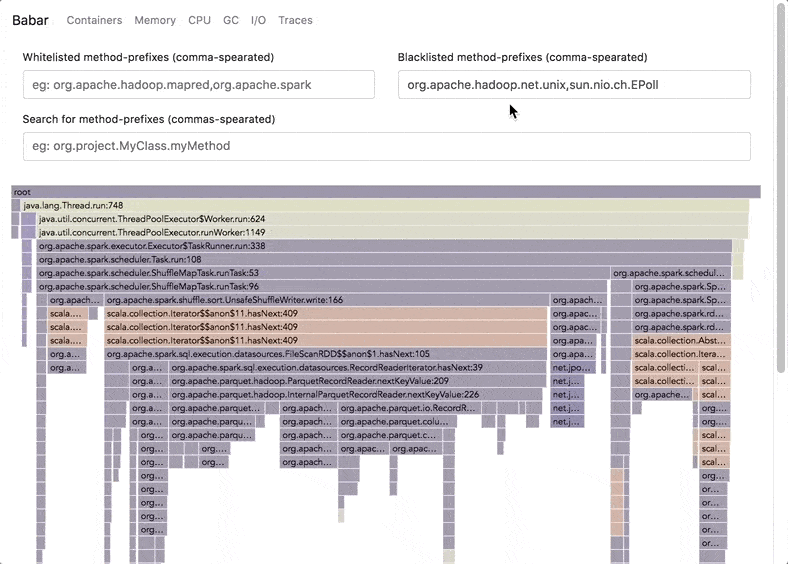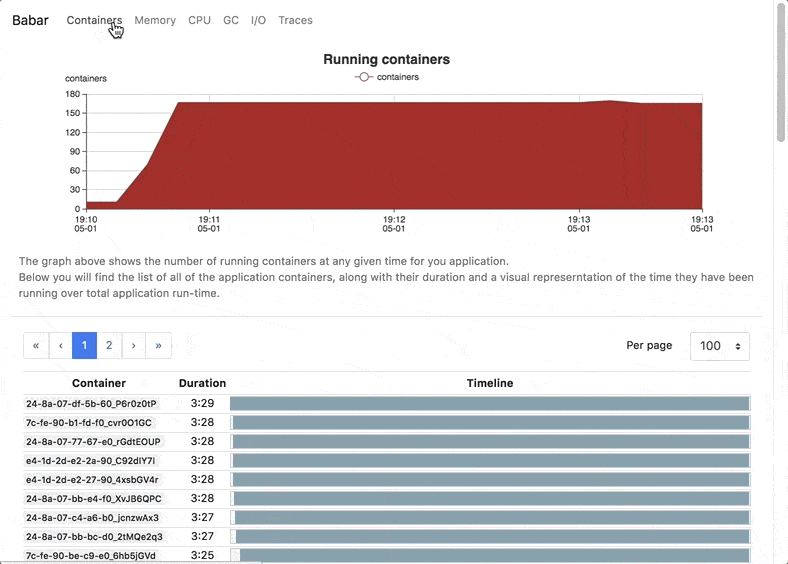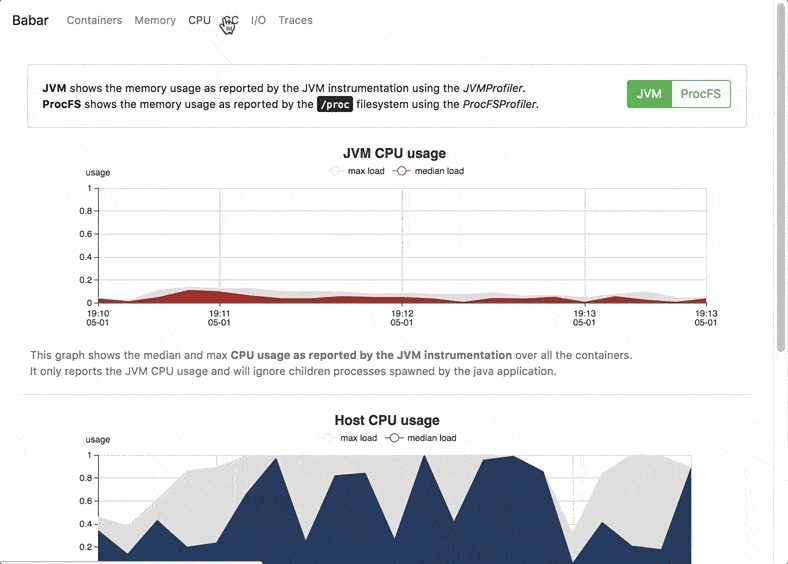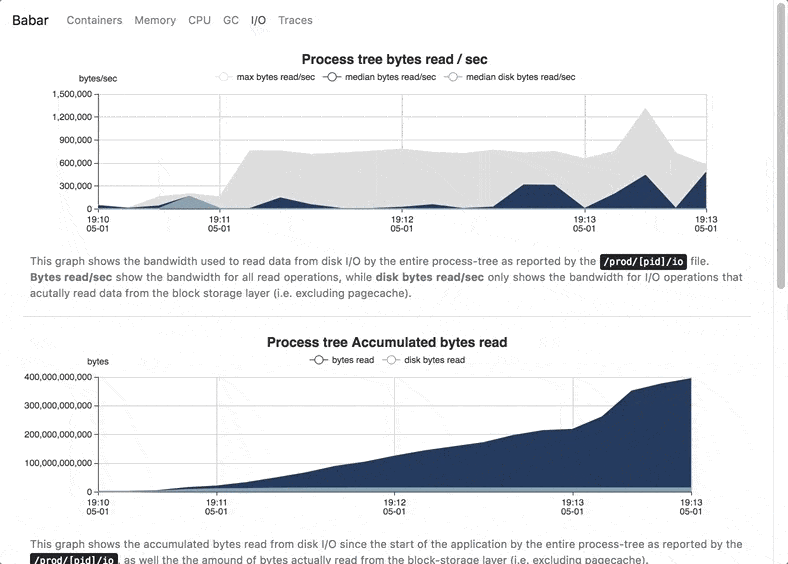
Babar registers metrics about memory, cpu, garbage collection usage, as well as method calls in each individual container and then aggregates them over the entire application to produce a ready-to-use report of the resource usage and method calls (as flame-graphs) of the program..
Currently babar is designed to profile YARN applications, but could be extended in order to profile other types of applications.
- Build
- Usage
- Profiling a Spark application
- Profiling a Scalding or MapReduce application
- Profiling a Hive application
- License
The following tools are required to build the project:
- maven (version 3 or greater)
- java (JDK) (version 1.8 or greater)
In order to build the project, run the following command at the root of the project:
mvn clean install
Babar is composed of three main components:
-
babar-agentThe babar-agent is a
java-agentprogram. An agent is a jar that can be attached to a JVM in order to instrument this JVM. The agent fetches, at regular interval, information on the resource consumption and logs the resulting metrics in a plain text file namedbabar.loginside the YARN log directory. YARN's log aggregation at the end of the application combines all the executors logs into a single log file available on HDFS. -
babar-processorThe babar-processor is the piece of software responsible for parsing the aggregated log file from the YARN application and aggregating the metrics to produce the report. The logs are parsed as streams which allows to aggregate large logs files (dozens of GB).
Once the babar-processor has run, a report HTML file is generated, containing all the graphs (memory, CPU usage, GC usage, executor counts, flame-graphs,...). This record can easily be shared by teams and saved for later use.
-
babar-reportThe babar-report is a VueJS project used as the template for the HTML file generated by the processor.
The babar-agent instruments the JVM to register and log the resource usage metrics. It is a standard java-agent component (see the instrumentation API doc for more information).
In order to add the agent to a JVM, add the following arguments to the java command line used to start your application:
-javaagent:/path/to/babar-agent-0.2.0-SNAPSHOT.jar=StackTraceProfiler,JVMProfiler[reservedMB=1024],ProcFSProfiler
You will need to replace /path/to/babar-agent-0.2.0-SNAPSHOT.jar with the actual path of the agent jar on your system. This jar must be locally accessible to your JVM (i.e. distributed on all your YARN nodes).
The profilers can be set and configured using this command line by adding parameters within brackets as shown in the following example:
-javaagent:./babar-agent-0.2.0-SNAPSHOT.jar=StackTraceProfiler[profilingMs=1000,reportingMs=600000],JVMProfiler[profilingMs=1000,reservedMB=2560],ProcFSProfiler[profilingMs=1000]
The available profilers and their configuration are described below. They can be used together or independently of each other.
The JVMProfiler registers metrics related to the resource usage of the JVM such as memory (heap and off-heap), host and JVM CPU usage, and minor and major GC ratio. Because it uses the JVM instrumentation (see the MXBean documentation), it will only work inside the hotspot JVM (the most commonly used) and will not register metrics for processes ran outside the JVM even if started by it.
This profiler accepts the following parameters:
| reservedMB (optional) | The amount of memory reserved in megabytes for the container in which the JVM runs. This value allows Babar to plot the reserved memory despite not having access to it (as it is managed by the resource allocator, i.e. YARN). |
| profilingMs (optional) | The interval in milliseconds between each sample (default 1000ms). |
The ProcFSProfiler logs OS-level metrics that are retrieved using the proc file system. This profiler is able to get metrics for the entire process tree, including processes started by the JVM but ran outside of it.
Because the proc filesystem is only available on unix-like systems and its implementation is platform dependent, this profiler will only run on linux systems. You may find more information on the proc filesystem in the official man page.
This profiler accepts the following parameters:
| profilingMs (optional) | The interval in milliseconds between each sample (default 1000ms). |
The StackTraceProfiler profiler registers the stack traces of all RUNNABLE JVM threads at regular intervals in order to build flame graphs of the time spent by all your JVMs in method calls.
The graphs are built by sampling the stack traces of the JVM at a regular interval (the profilingMs options). The traces are logged at another interval (the reportingMs option) in order to aggregate multiple traces before logging them to save space in the logs, which could otherwise takes hundreds of gigabytes. The traces are always logged on the JVM shutdown, so one can set the reporting interval at a very high value in order to save the most space in the logs if they are not interested in having traces logged in case the JVM is abruptly killed (they will still be logged if an exception is raised by the application code but the JVM is allowed to go through the shutdown hooks).
This profiler accepts the following parameters:
| profilingMs (optional) | The interval in milliseconds between each sample (default 100ms). |
| reportingMs (optional) | The interval in milliseconds before logging the aggregated traces (default 10min). |
The babar-processor is the piece of software that parses the logs and aggregates the metrics into graphs.
The processor aggregates stack traces as flame graphs flame graphs. Other metrics are aggregated using a given time-precision, which means they are aggregated in time-buckets to aggregate metrics of different container in buckets as all containers will log metrics at a different time. This also allows to significantly reduce the size of the resulting HTML file so that it can easily be shared and exploited. This time-precision is user-adjustable but should always be at least twice the profiling interval set in the profilers.
-
aggregating the logs
The processor needs to parse the application log aggregated by YARN (or any other log aggregation mechanism), either from HDFS or from a local log file that has been fetched using the following command (replace the application id with yours):
yarn logs --applicationId application_1514203639546_124445 > myAppLog.log -
parsing the logs to generate the HTML report
To run the babar-processor, the following command can be used:
java -jar /path/to/babar-processor.jar myAppLog.logThe processor accepts the following arguments:
-c, --containers <arg> if set, only metrics of containers matching these prefixes are aggregated (comma-separated) -d, --max-traces-depth <arg> max depth of stack traces -r, --min-traces-ratio <arg> min ratio of occurences in profiles for traces to be kept -o, --output-file <arg> path of the output file (default: ./babar_{date}.html) -t, --time-precision <arg> time precision (in ms) to use in aggregations --help Show help message trailing arguments: log-file (required) the log file to openUpon completion, the report HTML file is generated with a name such as
babar_2018-04-29_12-04-12.html. This file contains all the aggregated measurements.
No code changes are required to instrument a Spark job since Spark allows to distribute the agent jar archive to all containers using the --files command argument.
In order to instrument your Spark application, simply add these arguments to your spark-submit command:
--files ./babar-agent-0.2.0-SNAPSHOT.jar
--conf spark.executor.extraJavaOptions="-javaagent:./babar-agent-0.2.0-SNAPSHOT.jar=StackTraceProfiler,JVMProfiler[reservedMB=2560],ProcFSProfiler"
You can adjust the reserved memory setting (reservedMB) according to spark.executor.memory + spark.yarn.executor.memoryOverhead.
You can then use the yarn logs command to get the aggregated log file and process the logs using the babar-processor.
No code change is required to instrument a MapReduce, Cascading or Scalding application as MapReduce allows distributing jars to the containers from HDFS using the -files argument.
In order to instrument your MapReduce job, use the following arguments:
-files hdfs:///path/to/babar-agent-0.2.0-SNAPSHOT.jar \
-Dmapreduce.map.java.opts="-javaagent:./babar-agent-0.2.0-SNAPSHOT.jar=StackTraceProfiler,JVMProfiler[reservedMB=2560],ProcFSProfiler" \
-Dmapreduce.reduce.java.opts="-javaagent:./babar-agent-0.2.0-SNAPSHOT.jar=StackTraceProfiler,JVMProfiler[reservedMB=3584],ProcFSProfiler"
You can adjust the reserved memory values for mappers and reducers independently. These values can also be automatically set by instrumenting the jobs programmatically.
Similarly to Spark and MapReduce, Hive allows to easily distribute a jar from HDFS to the executors. To profile an Hive application, simply execute the following commands in Hive before your query:
ADD FILE /path/to/babar-agent-0.2.0-SNAPSHOT.jar;
SET mapreduce.map.java.opts="-javaagent:./babar-agent-0.2.0-SNAPSHOT.jar=StackTraceProfiler,JVMProfiler[reservedMB=2560],ProcFSProfiler";
SET mapreduce.reduce.java.opts="-javaagent:./babar-agent-0.2.0-SNAPSHOT.jar=StackTraceProfiler,JVMProfiler[reservedMB=3584],ProcFSProfiler";
As for other MapReduce applications, reserved memory values will need to be adjusted for mappers and reducers independently.
Copyright 2018 Criteo
Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance with the License. You may obtain a copy of the License at