 This work was mainly done in the Omni Lab for Intelligent Visual Engineering and Science (OLIVES) @ Georgia Tech.
This work was mainly done in the Omni Lab for Intelligent Visual Engineering and Science (OLIVES) @ Georgia Tech.
Feel free to check our lab's Website and GitHub for other interesting work!!!
This is the official PyTorch implementation of our papers:
Temporal Attentive Alignment for Large-Scale Video Domain Adaptation
Min-Hung Chen, Zsolt Kira, Ghassan AlRegib (Advisor), Jaekwon Yoo, Ruxin Chen, Jian Zheng
International Conference on Computer Vision (ICCV), 2019 [Oral (acceptance rate: 4.6%)]
[arXiv][Project][Blog][Presentation (officially recorded)][Oral][Poster][Slides][Open Access][IEEE Xplore]
Temporal Attentive Alignment for Video Domain Adaptation
Min-Hung Chen, Zsolt Kira, Ghassan AlRegib (Advisor)
CVPR Workshop (Learning from Unlabeled Videos), 2019
[arXiv]

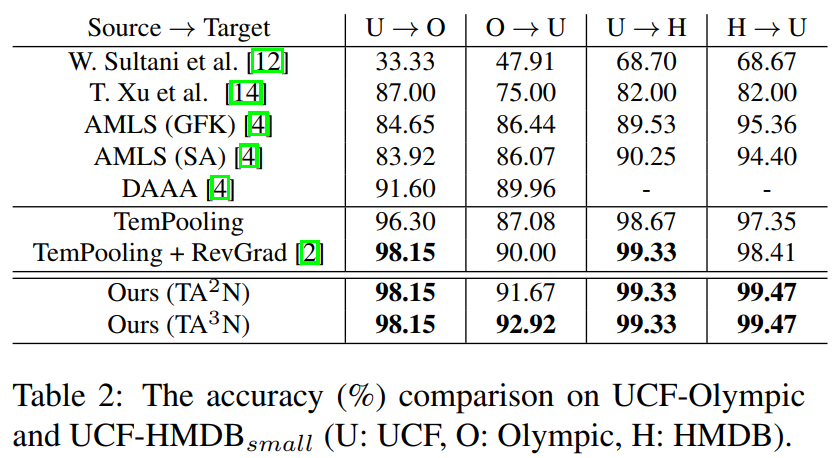
Although various image-based domain adaptation (DA) techniques have been proposed in recent years, domain shift in videos is still not well-explored. Most previous works only evaluate performance on small-scale datasets which are saturated. Therefore, we first propose two largescale video DA datasets with much larger domain discrepancy: UCF-HMDBfull and Kinetics-Gameplay. Second, we investigate different DA integration methods for videos, and show that simultaneously aligning and learning temporal dynamics achieves effective alignment even without sophisticated DA methods. Finally, we propose Temporal Attentive Adversarial Adaptation Network (TA3N), which explicitly attends to the temporal dynamics using domain discrepancy for more effective domain alignment, achieving state-of-the-art performance on four video DA datasets.

- support Python 3.6, PyTorch 0.4, CUDA 9.0, CUDNN 7.1.4
- install all the library with:
pip install -r requirements.txt
You need to extract frame-level features for each video to run the codes. To extract features, please check dataset_preparation/.
Folder Structure:
DATA_PATH/
DATASET/
list_DATASET_SUFFIX.txt
RGB/
CLASS_01/
VIDEO_0001.mp4
VIDEO_0002.mp4
...
CLASS_02/
...
RGB-Feature/
VIDEO_0001/
img_00001.t7
img_00002.t7
...
VIDEO_0002/
...
RGB-Feature/ contains all the feature vectors for training/testing. RGB/ contains all the raw videos.
There should be at least two DATASET folders: source training set and validation set. If you want to do domain adaption, you need to have another DATASET: target training set.
The file list list_DATASET_SUFFIX.txt is required for data feeding. Each line in the list contains the full path of the video folder, video frame number, and video class index. It looks like:
DATA_PATH/DATASET/RGB-Feature/VIDEO_0001/ 100 0
DATA_PATH/DATASET/RGB-Feature/VIDEO_0002/ 150 1
......
To generate the file list, please check dataset_preparation/.
Here we provide pre-extracted features and data list files, so you can skip the above two steps and directly try our training/testing codes. You may need to manually edit the path in the data list files.
-
Features
- UCF: download
- HMDB: download
- Olympic: training | validation
-
Data lists
- UCF-Olympic
- UCF: training list | validation list
- Olympic: training list | validation list
- UCF-HMDBsmall
- UCF: training list | validation list
- HMDB: training list | validation list
- UCF-HMDBfull
- UCF: training list | validation list
- HMDB: training list | validation list
- UCF-Olympic
-
Kinetics-Gameplay: please fill this form to request the features and data lists.
The Kinetics-Gameplay dataset is licensed under CC BY-NC-SA 4.0 for non-commercial purposes only.

- training/validation: Run
./script_train_val.sh
All the commonly used variables/parameters have comments in the end of the line. Please check Options.
All the outputs will be under the directory exp_path.
- Outputs:
- model weights:
checkpoint.pth.tar,model_best.pth.tar - log files:
train.log,train_short.log,val.log,val_short.log
- model weights:
You can choose one of model_weights for testing. All the outputs will be under the directory exp_path.
- Outputs:
- score_data: used to check the model output (
scores_XXX.npz) - confusion matrix:
confusion_matrix_XXX.pngandconfusion_matrix_XXX-topK.txt
- score_data: used to check the model output (
In ./script_train_val.sh, there are several options related to our DA approaches.
use_target: switch on/off the DA modenone: not use target data (no DA)uSv/Sv: use target data in a unsupervised/supervised way
For more details of all the arguments, please check opts.py.
The options in the scripts have comments with the following types:
- no comment: user can still change it, but NOT recommend (may need to change the code or have different experimental results)
- comments with choices (e.g.
true | false): can only choose from choices - comments as
depend on users: totally depend on users (mostly related to data path)
If you find this repository useful, please cite our papers:
@inproceedings{chen2019temporal,
title={Temporal attentive alignment for large-scale video domain adaptation},
author={Chen, Min-Hung and Kira, Zsolt and AlRegib, Ghassan and Woo, Jaekwon and Chen, Ruxin and Zheng, Jian},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2019},
url={https://arxiv.org/abs/1907.12743}
}
@article{chen2019taaan,
title={Temporal Attentive Alignment for Video Domain Adaptation},
author={Chen, Min-Hung and Kira, Zsolt and AlRegib, Ghassan},
journal={CVPR Workshop on Learning from Unlabeled Videos},
year={2019},
url={https://arxiv.org/abs/1905.10861}
}
This work was mainly done in OLIVES@GT with the guidance of Prof. Ghassan AlRegib, and the collaboration with Prof. Zsolt Kira at Georgia Tech. Part of this work was done with the collaboration with Jaekwon Yoo, Ruxin Chen and Jian Zheng.
Some codes are borrowed from TSN, pytorch-tsn, TRN-pytorch, and Xlearn.
Special thanks to the development team for the product used in the Kinetics-Gameplay dataset:
Detroit: Become Human™ ©Sony Interactive Entertainment Europe, developed by Quantic Dream
Min-Hung Chen
cmhungsteve AT gatech DOT edu