partition
Partition() is the simplest function, yet critical to understand.
If the dataset size is too large, it should be sharded. For multiple datasets, they should be sharded by the same key and processed on the same shard.
A Partition() step is divided into 2 steps: "scatter" and "collect".
"scatter" step runs on each of the dataset's original set of shards. Each entry is hashed by its key, or its value of no key specified, and then allocated to a destination shard by a simple mod.
"collect" step runs on each of the dataset's destination shards. All the data from the "scatter" step is collected into a new shard.
Here are the actual Partition() source code:
func (d *Dataset) Partition(shard int) *Dataset {
if d.IsKeyPartitioned && shard == len(d.Shards) {
return d
}
ret := d.partition_scatter(shard).partition_collect(shard)
ret.IsKeyPartitioned = true
return ret
}
flow.New().TextFile(
"/etc/hosts", 7,
).Partition(
2,
).Map(func(line string) string {
return line
}).Sort(func(a string, b string) bool {
if strings.Compare(a, b) < 0 {
return true
}
return false
}).Map(func(line string) {
println(line)
}).Run()
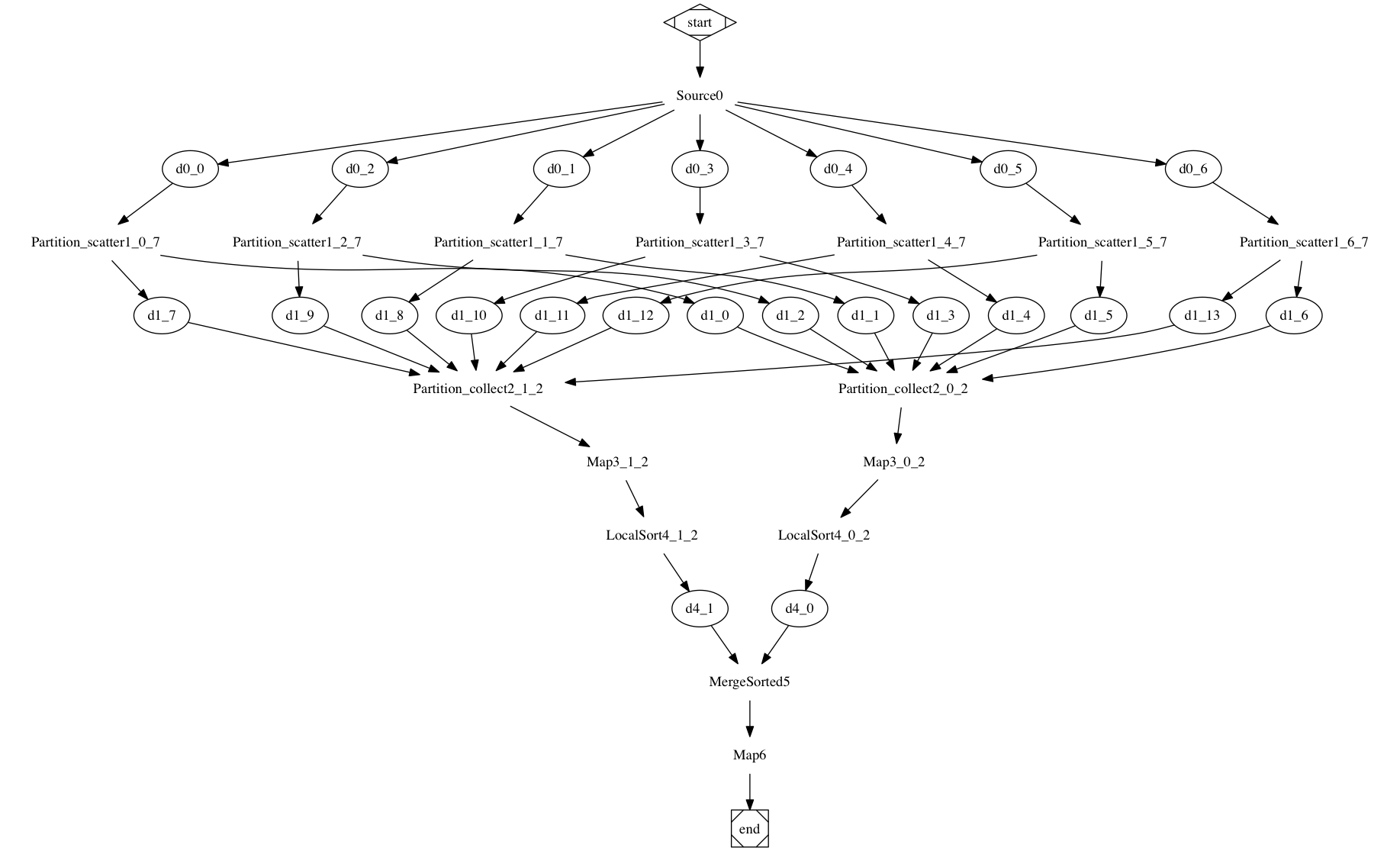
Partition is costly since it moves all the data across network. It's also used in Join(), CoJoin(). So only partition when absolutely necessary.