Parmesan is a library adding variational and semi-supervised neural network models to the neural network library Lasagne.
Parmesan depends heavily on the Lasagne and Theano libraries. Please make sure you have these installed before installing Parmesan.
Install Parmesan
git clone https://github.com/casperkaae/parmesan.git
cd parmesan
python setup.py developWork in progress. At the moment Parmesan primarily includes
- Layers for Monte Carlo approximation of integrals used in (importance weighted) variational autoencoders in parmesan/layers/sample.py
- Layers for constructing Ladder Networks in parmesan/layers/ladderlayers.py
- Layers for implementing normalizing flows in parmesan/layers/flow.py
Please see the source code and code examples for further details.
- examples/vae_vanilla.py: Variational autoencoder as described in Kingma et al. 2013
- examples/iw_vae.py: Variational autoencoder using importance sampling as described in Burda et al. 2015
- examples/iw_vae_normflow.py: Variational autoencoder using normalizing flows and importance sampling as described in Burda et al. 2015 and Rezende et al. 2015
- examples/mnist_ladder.py: Semi-supervised Ladder Network as described in Rasmus et al. 2015
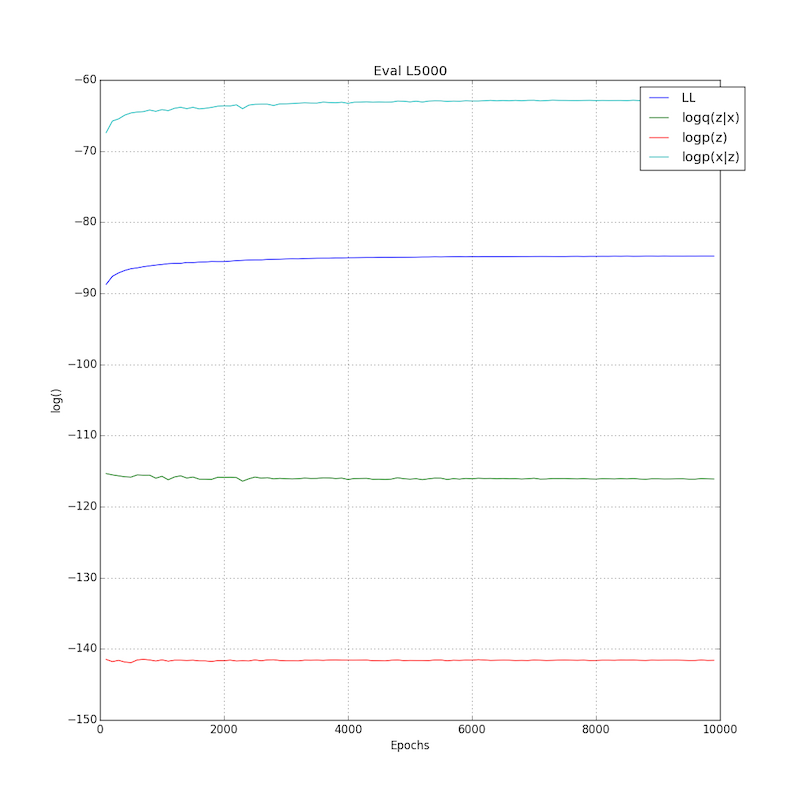
Usage example: Below is an image of the log-likelihood terms training an importance weighted autoencoder on MNIST using binomial sampling of the inputs before each epoch. Further we found it beneficial to add batch normalization to the fully connected layers. The training is done using one Monte Carlo sample to approximate the expectations over q(z|x) and one importance weighted sample. The test performance was evaluated using 5000 importance weighted samples and be should be directly comparable to the results in Burda et al. The final test performance is LL=-84.78 which is better than the current best published results at LL=-86.76 reported in Burda et al. table 1 (compare to top 1st row and 4th row in column labeled IWAE since we are training using a single importance weighted sample)).
Similar results should be obtained by running
python examples/iw_vae.py -eq_samples 1 -iw_samples 1 -lr 0.001 -nhidden 500 -nlatent 100 -nonlin_dec very_leaky_rectify -nonlin_enc rectify -batch_size 250 -anneal_lr_epoch 2000Parmesan is work in progress, inputs, contributions and bug reports are very welcome.
- The library is developed by
- Casper Kaae Sønderby
- Søren Kaae Sønderby
- Lars Maaløe
- Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
- Burda, Y., Grosse, R., & Salakhutdinov, R. (2015). Importance Weighted Autoencoders. arXiv preprint arXiv:1509.00519.
- Rezende, D. J., & Mohamed, S. (2015). Variational Inference with Normalizing Flows. arXiv preprint arXiv:1505.05770.
- Rasmus, A., Valpola, H., Honkala, M., Berglund, M., & Raiko, T. (2015). Semi-Supervised Learning with Ladder Network. arXiv preprint arXiv:1507.02672.