🤗 Hugging Face • 🤖 ModelScope • 💬 WeChat


{kind=link}
[2023.12.29] 🎉🎉🎉 我们发布了 Baichuan2-13B-Chat v2 版本。其中:
- 大幅提升了模型的综合能力,特别是数学和逻辑推理、复杂指令跟随能力。
- Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。
- Baichuan 2 在多个权威的中文、英文和多语言的通用、领域 benchmark 上取得同尺寸最佳的效果。
- 本次发布包含有 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。
- 所有版本对学术研究完全开放。同时,开发者通过邮件申请并获得官方商用许可后,即可免费商用,请参考协议章节。
- 欢迎阅读我们的技术报告 Baichuan 2: Open Large-scale Language Models 获取更多信息。
本次发布版本和下载链接见下表:
| 基座模型 | 对齐模型 | 对齐模型 4bits 量化 | |
|---|---|---|---|
| 7B | 🤗 Baichuan2-7B-Base | 🤗 Baichuan2-7B-Chat | 🤗 Baichuan2-7B-Chat-4bits |
| 13B | 🤗 Baichuan2-13B-Base | 🤗 Baichuan2-13B-Chat | 🤗 Baichuan2-13B-Chat-4bits |
我们在通用、法律、医疗、数学、代码和多语言翻译六个领域的中英文和多语言权威数据集上对模型进行了广泛测试。
在通用领域我们在以下数据集上进行了 5-shot 测试。
- C-Eval 是一个全面的中文基础模型评测数据集,涵盖了 52 个学科和四个难度的级别。我们使用该数据集的 dev 集作为 few-shot 的来源,在 test 集上进行测试。我们采用了 Baichuan-7B 的评测方案。
- MMLU 是包含 57 个任务的英文评测数据集,涵盖了初等数学、美国历史、计算机科学、法律等,难度覆盖高中水平到专家水平,是目前主流的 LLM 评测数据集。我们采用了开源的评测方案。
- CMMLU 是一个包含 67 个主题的综合性性中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。我们采用了其官方的评测方案。
- Gaokao 是一个以中国高考题作为评测大语言模型能力的数据集,用以评估模型的语言能力和逻辑推理能力。 我们只保留了其中的单项选择题,并进行了随机划分。我们采用了与 C-Eval 类似的评测方案。
- AGIEval 旨在评估模型的认知和解决问题相关的任务中的一般能力。 我们只保留了其中的四选一单项选择题,并进行了随机划分。我们采用了与 C-Eval 类似的评测方案。
- BBH 是一个挑战性任务 Big-Bench 的子集。Big-Bench 目前包括 204 项任务。任务主题涉及语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等方面。BBH 是从 204 项 Big-Bench 评测基准任务中大模型表现不好的任务单独拿出来形成的评测基准。
| C-Eval | MMLU | CMMLU | Gaokao | AGIEval | BBH | |
|---|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | 3-shot | |
| GPT-4 | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| GPT-3.5 Turbo | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| LLaMA-7B | 27.10 | 35.10 | 26.75 | 27.81 | 28.17 | 32.38 |
| LLaMA2-7B | 28.90 | 45.73 | 31.38 | 25.97 | 26.53 | 39.16 |
| MPT-7B | 27.15 | 27.93 | 26.00 | 26.54 | 24.83 | 35.20 |
| Falcon-7B | 24.23 | 26.03 | 25.66 | 24.24 | 24.10 | 28.77 |
| ChatGLM2-6B | 50.20 | 45.90 | 49.00 | 49.44 | 45.28 | 31.65 |
| Baichuan-7B | 42.80 | 42.30 | 44.02 | 36.34 | 34.44 | 32.48 |
| Baichuan2-7B-Base | 54.00 | 54.16 | 57.07 | 47.47 | 42.73 | 41.56 |
| C-Eval | MMLU | CMMLU | Gaokao | AGIEval | BBH | |
|---|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | 3-shot | |
| GPT-4 | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| GPT-3.5 Turbo | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| LLaMA-13B | 28.50 | 46.30 | 31.15 | 28.23 | 28.22 | 37.89 |
| LLaMA2-13B | 35.80 | 55.09 | 37.99 | 30.83 | 32.29 | 46.98 |
| Vicuna-13B | 32.80 | 52.00 | 36.28 | 30.11 | 31.55 | 43.04 |
| Chinese-Alpaca-Plus-13B | 38.80 | 43.90 | 33.43 | 34.78 | 35.46 | 28.94 |
| XVERSE-13B | 53.70 | 55.21 | 58.44 | 44.69 | 42.54 | 38.06 |
| Baichuan-13B-Base | 52.40 | 51.60 | 55.30 | 49.69 | 43.20 | 43.01 |
| Baichuan2-13B-Base | 58.10 | 59.17 | 61.97 | 54.33 | 48.17 | 48.78 |
法律领域我们使用了 JEC-QA 数据集。JEC-QA 数据集来源于中国国家司法考试。我们只保留了其中的单选题。我们采用了与 C-Eval 类似的评测方案。
医疗领域则使用通用领域数据集(C-Eval、MMLU、CMMLU)中的医学相关学科、MedQA 和 MedMCQA。我们采用了与 C-Eval 类似的评测方案。
- 为了测试方便,我们使用了 C-Eval 的 val 集进行测试。
- MedQA 数据集来源于美国、中国的医学考试。我们测试了 MedQA数据集 中的 USMLE 和 MCMLE 两个子集,并采用了五个候选的版本。
- MedMCQA 数据集来源于印度医学院的入学考试。我们只保留了其中的单选题。由于 test 集没有答案,我们使用 dev 集进行测试。
- 通用领域数据集包含的医学相关学科如下:
- C-Eval: clinical_medicine, basic_medicine
- MMLU: clinical_knowledge, anatomy, college_medicine, college_biology, nutrition, virology, medical_genetics, professional_medicine
- CMMLU: anatomy, clinical_knowledge, college_medicine, genetics, nutrition, traditional_chinese_medicine, virology
我们对以上数据集进行了 5-shot 测试。
| JEC-QA | CEval-MMLU-CMMLU | MedQA-USMLE | MedQA-MCMLE | MedMCQA | |
|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | |
| GPT-4 | 59.32 | 77.16 | 80.28 | 74.58 | 72.51 |
| GPT-3.5 Turbo | 42.31 | 61.17 | 53.81 | 52.92 | 56.25 |
| LLaMA-7B | 27.45 | 33.34 | 24.12 | 21.72 | 27.45 |
| LLaMA2-7B | 29.20 | 36.75 | 27.49 | 24.78 | 37.93 |
| MPT-7B | 27.45 | 26.67 | 16.97 | 19.79 | 31.96 |
| Falcon-7B | 23.66 | 25.33 | 21.29 | 18.07 | 33.88 |
| ChatGLM2-6B | 40.76 | 44.54 | 26.24 | 45.53 | 30.22 |
| Baichuan-7B | 34.64 | 42.37 | 27.42 | 39.46 | 31.39 |
| Baichuan2-7B-Base | 44.46 | 56.39 | 32.68 | 54.93 | 41.73 |
| JEC-QA | CEval-MMLU-CMMLU | MedQA-USMLE | MedQA-MCMLE | MedMCQA | |
|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | |
| GPT-4 | 59.32 | 77.16 | 80.28 | 74.58 | 72.51 |
| GPT-3.5 Turbo | 42.31 | 61.17 | 53.81 | 52.92 | 56.25 |
| LLaMA-13B | 27.54 | 35.14 | 28.83 | 23.38 | 39.52 |
| LLaMA2-13B | 34.08 | 47.42 | 35.04 | 29.74 | 42.12 |
| Vicuna-13B | 28.38 | 40.99 | 34.80 | 27.67 | 40.66 |
| Chinese-Alpaca-Plus-13B | 35.32 | 46.31 | 27.49 | 32.66 | 35.87 |
| XVERSE-13B | 46.42 | 58.08 | 32.99 | 58.76 | 41.34 |
| Baichuan-13B-Base | 41.34 | 51.77 | 29.07 | 43.67 | 39.60 |
| Baichuan2-13B-Base | 47.40 | 59.33 | 40.38 | 61.62 | 42.86 |
数学领域我们使用 OpenCompass 评估框架,对 GSM8K 和 MATH 数据集进行了 4-shot 测试。
- GSM8K 是由 OpenAI 发布的一个由 8.5K 高质量的语言多样化的小学数学应用题组成的数据集,要求根据给定的场景和两个可能的解决方案,选择最合理的方案。
- MATH 数据集包含 12,500 个数学问题(其中 7500 个属于训练集,5000 个属于测试集),这些问题收集自 AMC 10、AMC 12、AIME 等数学竞赛。
代码领域则采用了 HumanEval 和 MBPP 数据集。我们使用 OpenCompass,对 HumanEval 进行了 0-shot 测试,MBPP 数据集进行了 3-shot 测试。
- HumanEval 中的编程任务包括模型语言理解、推理、算法和简单数学,以评估模型功能正确性,并衡量模型的问题解决能力。
- MBPP 包括 974 个 Python 短函数、程序的文字描述以及用于检查功能正确性的测试用例的数据集。
| GSM8K | MATH | HumanEval | MBPP | |
|---|---|---|---|---|
| 4-shot | 4-shot | 0-shot | 3-shot | |
| GPT-4 | 89.99 | 40.20 | 69.51 | 63.60 |
| GPT-3.5 Turbo | 57.77 | 13.96 | 52.44 | 61.40 |
| LLaMA-7B | 9.78 | 3.02 | 11.59 | 14.00 |
| LLaMA2-7B | 16.22 | 3.24 | 12.80 | 14.80 |
| MPT-7B | 8.64 | 2.90 | 14.02 | 23.40 |
| Falcon-7B | 5.46 | 1.68 | - | 10.20 |
| ChatGLM2-6B | 28.89 | 6.40 | 9.15 | 9.00 |
| Baichuan-7B | 9.17 | 2.54 | 9.20 | 6.60 |
| Baichuan2-7B-Base | 24.49 | 5.58 | 18.29 | 24.20 |
| GSM8K | MATH | HumanEval | MBPP | |
|---|---|---|---|---|
| 4-shot | 4-shot | 0-shot | 3-shot | |
| GPT-4 | 89.99 | 40.20 | 69.51 | 63.60 |
| GPT-3.5 Turbo | 57.77 | 13.96 | 52.44 | 61.40 |
| LLaMA-13B | 20.55 | 3.68 | 15.24 | 21.40 |
| LLaMA2-13B | 28.89 | 4.96 | 15.24 | 27.00 |
| Vicuna-13B | 28.13 | 4.36 | 16.46 | 15.00 |
| Chinese-Alpaca-Plus-13B | 11.98 | 2.50 | 16.46 | 20.00 |
| XVERSE-13B | 18.20 | 2.18 | 15.85 | 16.80 |
| Baichuan-13B-Base | 26.76 | 4.84 | 11.59 | 22.80 |
| Baichuan2-13B-Base | 52.77 | 10.08 | 17.07 | 30.20 |
我们采用了 Flores-101 数据集来评估模型的多语言能力。Flores-101 涵盖了世界各地的 101 种语言。它的数据来源于新闻、旅游指南和书籍等多个不同领域。我们选择了联合国官方语言(阿拉伯文、中文、英文、法文、俄文和西班牙文)以及德文和日文作为测试语种。我们使用 OpenCompass 对 Flores-101 中的中-英、中-法、中-西班牙、中-阿拉伯、中-俄、中-日、中-德等七个子任务分别进行了 8-shot 测试。
| CN-EN | CN-FR | CN-ES | CN-AR | CN-RU | CN-JP | CN-DE | Average | |
|---|---|---|---|---|---|---|---|---|
| GPT-4 | 29.94 | 29.56 | 20.01 | 10.76 | 18.62 | 13.26 | 20.83 | 20.43 |
| GPT-3.5 Turbo | 27.67 | 26.15 | 19.58 | 10.73 | 17.45 | 1.82 | 19.70 | 17.59 |
| LLaMA-7B | 17.27 | 12.02 | 9.54 | 0.00 | 4.47 | 1.41 | 8.73 | 7.63 |
| LLaMA2-7B | 25.76 | 15.14 | 11.92 | 0.79 | 4.99 | 2.20 | 10.15 | 10.14 |
| MPT-7B | 20.77 | 9.53 | 8.96 | 0.10 | 3.54 | 2.91 | 6.54 | 7.48 |
| Falcon-7B | 22.13 | 15.67 | 9.28 | 0.11 | 1.35 | 0.41 | 6.41 | 7.91 |
| ChatGLM2-6B | 22.28 | 9.42 | 7.77 | 0.64 | 1.78 | 0.26 | 4.61 | 6.68 |
| Baichuan-7B | 25.07 | 16.51 | 12.72 | 0.41 | 6.66 | 2.24 | 9.86 | 10.50 |
| Baichuan2-7B-Base | 27.27 | 20.87 | 16.17 | 1.39 | 11.21 | 3.11 | 12.76 | 13.25 |
| CN-EN | CN-FR | CN-ES | CN-AR | CN-RU | CN-JP | CN-DE | Average | |
|---|---|---|---|---|---|---|---|---|
| GPT-4 | 29.94 | 29.56 | 20.01 | 10.76 | 18.62 | 13.26 | 20.83 | 20.43 |
| GPT-3.5 Turbo | 27.67 | 26.15 | 19.58 | 10.73 | 17.45 | 1.82 | 19.70 | 17.59 |
| LLaMA-13B | 21.75 | 16.16 | 13.29 | 0.58 | 7.61 | 0.41 | 10.66 | 10.07 |
| LLaMA2-13B | 25.44 | 19.25 | 17.49 | 1.38 | 10.34 | 0.13 | 11.13 | 12.17 |
| Vicuna-13B | 22.63 | 18.04 | 14.67 | 0.70 | 9.27 | 3.59 | 10.25 | 11.31 |
| Chinese-Alpaca-Plus-13B | 22.53 | 13.82 | 11.29 | 0.28 | 1.52 | 0.31 | 8.13 | 8.27 |
| XVERSE-13B | 29.26 | 24.03 | 16.67 | 2.78 | 11.61 | 3.08 | 14.26 | 14.53 |
| Baichuan-13B-Base | 30.24 | 20.90 | 15.92 | 0.98 | 9.65 | 2.64 | 12.00 | 13.19 |
| Baichuan2-13B-Base | 30.61 | 22.11 | 17.27 | 2.39 | 14.17 | 11.58 | 14.53 | 16.09 |
推理所需的模型权重、源码、配置已发布在 Hugging Face,下载链接见本文档最开始的表格。我们在此示范多种推理方式。程序会自动从 Hugging Face 下载所需资源。
pip install -r requirements.txt>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> from transformers.generation.utils import GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", use_fast=False, trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
>>> model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan2-13B-Chat")
>>> messages = []
>>> messages.append({"role": "user", "content": "解释一下“温故而知新”"})
>>> response = model.chat(tokenizer, messages)
>>> print(response)
"温故而知新"是一句中国古代的成语,出自《论语·为政》篇。这句话的意思是:通过回顾过去,我们可以发现新的知识和理解。换句话说,学习历史和经验可以让我们更好地理解现在和未来。
这句话鼓励我们在学习和生活中不断地回顾和反思过去的经验,从而获得新的启示和成长。通过重温旧的知识和经历,我们可以发现新的观点和理解,从而更好地应对不断变化的世界和挑战。>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Base", trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Base", device_map="auto", trust_remote_code=True)
>>> inputs = tokenizer('登鹳雀楼->王之涣\n夜雨寄北->', return_tensors='pt')
>>> inputs = inputs.to('cuda:0')
>>> pred = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1)
>>> print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
登鹳雀楼->王之涣
夜雨寄北->李商隐在上述两段代码中,模型加载指定
device_map='auto',会使用所有可用显卡。如需指定使用的设备,可以使用类似export CUDA_VISIBLE_DEVICES=0,1(使用了0、1号显卡)的方式控制。
python cli_demo.py本命令行工具是为 Chat 场景设计,因此我们不支持使用该工具调用 Base 模型。
依靠 streamlit 运行以下命令,会在本地启动一个 web 服务,把控制台给出的地址放入浏览器即可访问。本网页 demo 工具是为 Chat 场景设计,因此我们不支持使用该工具调用 Base 模型。
streamlit run web_demo.py代码
用户:找到下列数组的中位数[3.1,6.2,1.3,8.4,10.5,11.6,2.1],请用python代码完成以上功能
Baichuan 2:def find_median(numbers):
numbers.sort()
length = len(numbers)
if length % 2 == 0:
return (numbers[length // 2 - 1] + numbers[length // 2]) / 2
else:
return numbers[length // 2]
numbers = [3.1, 6.2, 1.3, 8.4, 10.5, 11.6, 2.1]
print(find_median(numbers))
数学
用户:鸡和兔在一个笼子里,共有26个头,68只脚,那么鸡有多少只,兔有多少只?
Baichuan 2:我们可以用代数方法来解决这个问题。假设鸡的数量为x,兔子的数量为y。根据题目给出的信息,我们可以得到以下两个方程:
1. x + y = 26 (头的总数)
2. 2x + 4y = 68 (脚的总数)
现在我们需要解这个二元一次方程组。首先从第一个方程中解出x:
x = 26 - y
然后将x的表达式代入第二个方程:
2(26 - y) + 4y = 68
52 - 2y + 4y = 68
2y = 16
接下来我们求解y的值:
y = 16 / 2
y = 8
现在我们得到了兔子的数量是8只。将y的值代入x的表达式求得鸡的数量:
x = 26 - 8
x = 18
所以鸡有18只,兔子有8只。
指令跟随
用户:从现在开始,请你将我接下来说的每一句话翻译成英语,准备好了吗?
Baichuan 2:I'm ready to translate every word you say next into English.
用户:你好
Baichuan 2:Hello
用户:我是Baichuan 2,很高兴认识大家
Baichuan 2:I am Baichuan 2, and I am very happy to meet everyone.
用户:希望通过大家的共同努力,早日迎接AGI时代的到来
Baichuan 2:I hope through the joint efforts of all of us, we can welcome the arrival of the AGI era as soon as possible.
解题
用户:以下物理常识题目,哪一个是错误的?A.在自然环境下,声音在固体中传播速度最快。B.牛顿第一定律:一个物体如果不受力作用,将保持静止或匀速直线运动的状态。C.牛顿第三定律:对于每个作用力,都有一个相等而反向的反作用力。D.声音在空气中的传播速度为1000m/s。
Baichuan 2:本题考查物理基本概念和原理的理解和应用能力。
A项:声音的传播需要介质,在固体、液体和气体的三种介质中,声音在固体中的传播速度是最快的,故A正确; B项:牛顿第一定律是惯性定律,其内容是:一个物体如果没有受到外力的作用,要么保持静止状态,要么保持匀速直线运动状态,直到有外力迫使它改变运动状态为止,故B正确; C项:牛顿第三定律的内容是:对于每一个作用力,都有一个大小相等、方向相反的反作用力,这两个力分别作用在两个相互作用的物体上,故C错误; D项:声音在空气中以波的形式传播,其传播速度与介质的温度、湿度等因素有关,一般情况下,声音在空气中的传播速度约为340m/s左右,而不是1000m/s,故D错误。 因此,本题的正确答案是 D 。
用户:I'm Mike 。I am going to have a busy weekend。On Saturday,I am going to learn how to swim。I will go with my father。Then we are going to have lunch in the restaurant。In the afternoon,we are going to the zoo。We are going to see the pandas。On Sunday,I will finish my homework in the morning。In the afternoon,my parents and I are going to visit my grandparents。We will have dinner together。
阅读短文,判断正确和错误!正确请写T,错误请写F:
1.Mike is going to have a busy weekend()
2.Mike is going to learn how to swim with his father()
3.They are going to have lunch at home()
Baichuan 2:1. T(正确的)
2. T(正确的)
3. F(错误的)
为了让不同的用户以及不同的平台都能运行 Baichuan 2 模型,我们针对 Baichuan 2 模型做了相应地量化工作(包括 Baichuan2-7B-Chat 和 Baichuan2-13B-Chat),方便用户快速高效地在自己的平台部署 Baichuan 2 模型。
Baichuan 2 的采用社区主流的量化方法:BitsAndBytes。该方法可以保证量化后的效果基本不掉点,目前已经集成到 transformers 库里,并在社区得到了广泛应用。BitsAndBytes 支持 8bits 和 4bits 两种量化,其中 4bits 支持 FP4 和 NF4 两种格式,Baichuan 2 选用 NF4 作为 4bits 量化的数据类型。
基于该量化方法,Baichuan 2 支持在线量化和离线量化两种模式。
对于在线量化,我们支持 8bits 和 4bits 量化,使用方式和 Baichuan-13B 项目中的方式类似,只需要先加载模型到 CPU 的内存里,再调用quantize()接口量化,最后调用 cuda()函数,将量化后的权重拷贝到 GPU 显存中。实现整个模型加载的代码非常简单,我们以 Baichuan2-7B-Chat 为例:
8bits 在线量化:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(8).cuda() 4bits 在线量化:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(4).cuda() 需要注意的是,在用 from_pretrained 接口的时候,用户一般会加上 device_map="auto",在使用在线量化时,需要去掉这个参数,否则会报错。
为了方便用户的使用,我们提供了离线量化好的 4bits 的版本 Baichuan2-7B-Chat-4bits,供用户下载。 用户加载 Baichuan2-7B-Chat-4bits 模型很简单,只需要执行:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat-4bits", device_map="auto", trust_remote_code=True)对于 8bits 离线量化,我们没有提供相应的版本,因为 Hugging Face transformers 库提供了相应的 API 接口,可以很方便的实现 8bits 量化模型的保存和加载。用户可以自行按照如下方式实现 8bits 的模型保存和加载:
# Model saving: model_id is the original model directory, and quant8_saved_dir is the directory where the 8bits quantized model is saved.
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_8bit=True, device_map="auto", trust_remote_code=True)
model.save_pretrained(quant8_saved_dir)
model = AutoModelForCausalLM.from_pretrained(quant8_saved_dir, device_map="auto", trust_remote_code=True)量化前后显存占用对比 (GPU Mem in GB):
| Precision | Baichuan2-7B | Baichuan2-13B |
|---|---|---|
| bf16 / fp16 | 15.3 | 27.5 |
| 8bits | 8.0 | 16.1 |
| 4bits | 5.1 | 8.6 |
量化后在各个 benchmark 上的结果和原始版本对比如下:
| Model 5-shot | C-Eval | MMLU | CMMLU |
|---|---|---|---|
| Baichuan2-13B-Chat | 56.74 | 57.32 | 59.68 |
| Baichuan2-13B-Chat-4bits | 56.05 | 56.24 | 58.82 |
| Baichuan2-7B-Chat | 54.35 | 52.93 | 54.99 |
| Baichuan2-7B-Chat-4bits | 53.04 | 51.72 | 52.84 |
C-Eval 是在其 val set 上进行的评测
可以看到,4bits 相对 bfloat16 精度损失在 1 - 2 个百分点左右。
Baichuan 2 模型支持 CPU 推理,但需要强调的是,CPU 的推理速度相对较慢。需按如下方式修改模型加载的方式:
# Taking Baichuan2-7B-Chat as an example
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float32, trust_remote_code=True)由于很多用户在 Baichuan 1 (Baichuan-7B, Baichuan-13B)上做了很多优化的工作,例如编译优化、量化等,为了将这些工作零成本地应用于 Baichuan 2,用户可以对 Baichuan 2 模型做一个离线转换,转换后就可以当做 Baichuan 1 模型来使用。具体来说,用户只需要利用以下脚本离线对 Baichuan 2 模型的最后一层 lm_head 做归一化,并替换掉lm_head.weight即可。替换完后,就可以像对 Baichuan 1 模型一样对转换后的模型做编译优化等工作了。
import torch
import os
ori_model_dir = 'your Baichuan 2 model directory'
# To avoid overwriting the original model, it's best to save the converted model to another directory before replacing it
new_model_dir = 'your normalized lm_head weight Baichuan 2 model directory'
model = torch.load(os.path.join(ori_model_dir, 'pytorch_model.bin'))
lm_head_w = model['lm_head.weight']
lm_head_w = torch.nn.functional.normalize(lm_head_w)
model['lm_head.weight'] = lm_head_w
torch.save(model, os.path.join(new_model_dir, 'pytorch_model.bin'))git clone https://github.com/baichuan-inc/Baichuan2.git
cd Baichuan2/fine-tune
pip install -r requirements.txt下面我们给一个微调 Baichuan2-7B-Base 的单机训练例子。
训练数据:data/belle_chat_ramdon_10k.json,该样例数据是从 multiturn_chat_0.8M 采样出 1 万条,并且做了格式转换。主要是展示多轮数据怎么训练,不保证效果。
hostfile=""
deepspeed --hostfile=$hostfile fine-tune.py \
--report_to "none" \
--data_path "data/belle_chat_ramdon_10k.json" \
--model_name_or_path "baichuan-inc/Baichuan2-7B-Base" \
--output_dir "output" \
--model_max_length 512 \
--num_train_epochs 4 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 1 \
--save_strategy epoch \
--learning_rate 2e-5 \
--lr_scheduler_type constant \
--adam_beta1 0.9 \
--adam_beta2 0.98 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--logging_steps 1 \
--gradient_checkpointing True \
--deepspeed ds_config.json \
--bf16 True \
--tf32 True多机训练只需要给一下 hostfile ,内容类似如下:
ip1 slots=8
ip2 slots=8
ip3 slots=8
ip4 slots=8
....
同时在训练脚本里面指定 hosftfile 的路径:
hostfile="/path/to/hostfile"
deepspeed --hostfile=$hostfile fine-tune.py \
--report_to "none" \
--data_path "data/belle_chat_ramdon_10k.json" \
--model_name_or_path "baichuan-inc/Baichuan2-7B-Base" \
--output_dir "output" \
--model_max_length 512 \
--num_train_epochs 4 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 1 \
--save_strategy epoch \
--learning_rate 2e-5 \
--lr_scheduler_type constant \
--adam_beta1 0.9 \
--adam_beta2 0.98 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--logging_steps 1 \
--gradient_checkpointing True \
--deepspeed ds_config.json \
--bf16 True \
--tf32 True代码已经支持轻量化微调如 LoRA,如需使用仅需在上面的脚本中加入以下参数:
--use_lora TrueLoRA 具体的配置可见 fine-tune.py 脚本。
使用 LoRA 微调后可以使用下面的命令加载模型:
from peft import AutoPeftModelForCausalLM
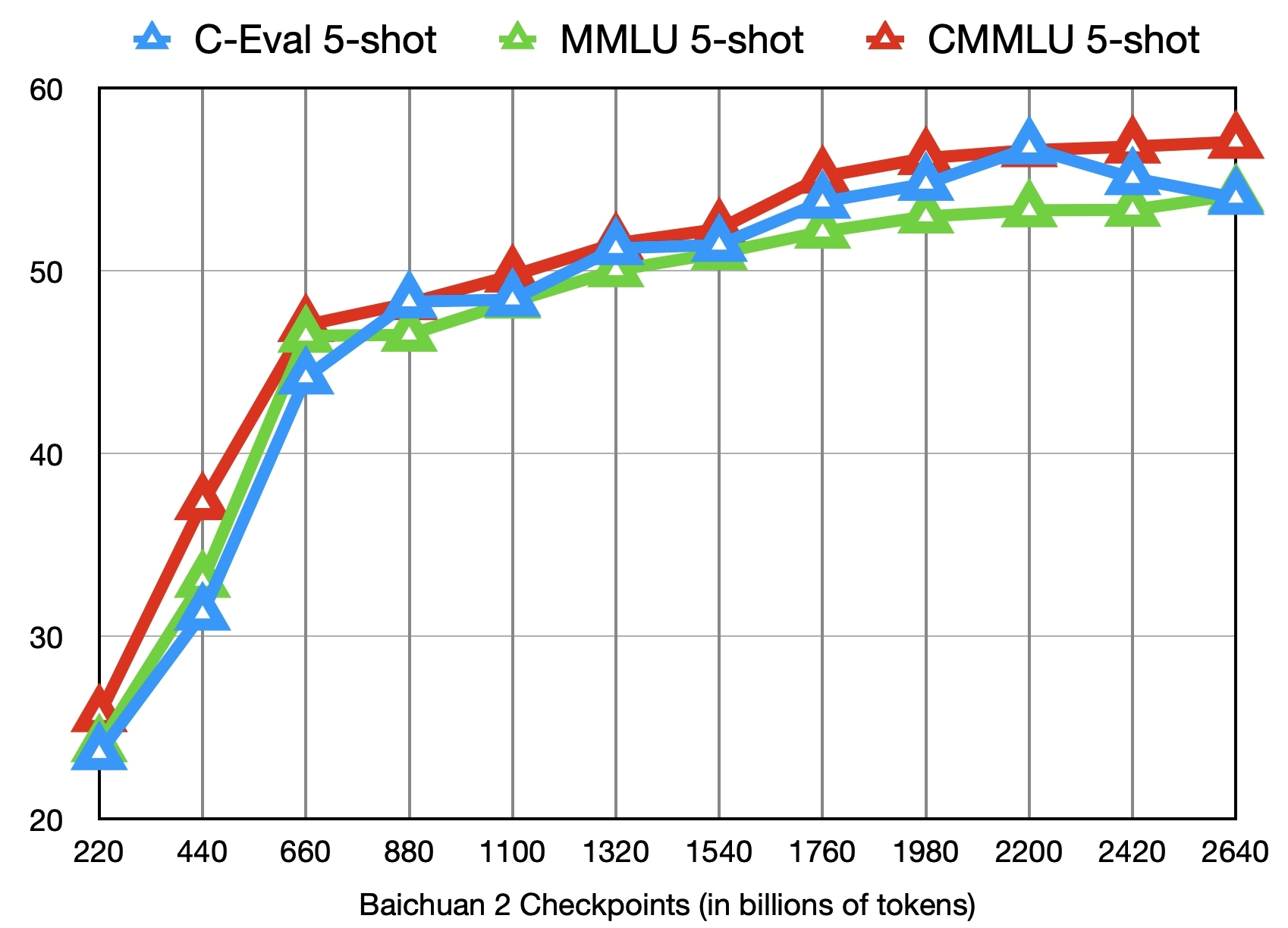
model = AutoPeftModelForCausalLM.from_pretrained("output", trust_remote_code=True)除了训练了 2.6 万亿 Tokens 的 Baichuan2-7B-Base 模型,我们还提供了在此之前的另外 11 个中间 checkpoints(分别对应训练了约 0.2 ~ 2.4 万亿 Tokens)供社区研究使用(下载地址)。下图给出了这些 checkpoints 在 C-Eval、MMLU、CMMLU 三个 benchmark 上的效果变化:
📢📢📢 我们会在此持续更新社区和生态对 Baichuan 2 的支持 😀😀😀
使用酷睿™/至强® 可扩展处理器或配合锐炫™ GPU等进行部署BaiChuan2 - 7B/Chat,BaiChuan2 - 13B/Chat模型
推荐使用 BigDL-LLM(CPU, GPU)以发挥更好推理性能。
中文操作手册,包括用notebook支持
模型微调:Baichuan 2 (7B)已原生支持基于昇腾 NPU 的 PyTorch(2.1.0)+ Transformers(4.36.0)+ DeepSpeed(0.12.4)+ Accelerate(0.25.0)模型微调,无需额外适配即可使用。
推理部署:Baichuan 2 (7B)已原生支持昇腾 NPU 推理,无需额外适配即可使用。
MindFormers 是一个基于昇思框架(MindSpore)并支持大模型训练、微调、评估、推理、部署的全流程开发套件,Baichuan2-7B / 13B 已集成于此套件,支持用户进行模型微调、部署,具体使用方式可见 README。
昇思大模型平台 基于昇思 MindSpore AI 框架、MindFormers 大模型开发套件与昇腾硬件算力,将 Baichuan2-7B 大模型能力开放给公众,欢迎大家在线体验。
LLaMA-Efficient-Tuning 已支持对 Baichuan 2 模型的微调和继续训练。
Baichuan2(7B/13B)支持太初 T100 加速卡推理,现试用通道已正式对外开启。
我们在此声明,我们的开发团队并未基于 Baichuan 2 模型开发任何应用,无论是在 iOS、Android、网页或任何其他平台。我们强烈呼吁所有使用者,不要利用 Baichuan 2 模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将 Baichuan 2 模型用于未经适当安全审查和备案的互联网服务。我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。
我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用 Baichuan 2 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
社区使用 Baichuan 2 模型需要遵循 Apache 2.0 和《Baichuan 2 模型社区许可协议》。Baichuan 2 模型支持商业用途,如果您计划将 Baichuan 2 模型或其衍生品用于商业目的,请您确认您的主体符合以下情况:
- 您或您的关联方的服务或产品的日均用户活跃量(DAU)低于100万。
- 您或您的关联方不是软件服务提供商、云服务提供商。
- 您或您的关联方不存在将授予您的商用许可,未经百川许可二次授权给其他第三方的可能。
在符合以上条件的前提下,您需要通过以下联系邮箱 [email protected] ,提交《Baichuan 2 模型社区许可协议》要求的申请材料。审核通过后,百川将特此授予您一个非排他性、全球性、不可转让、不可再许可、可撤销的商用版权许可。
如需引用我们的工作,请使用如下 reference:
@article{baichuan2023baichuan2,
title={Baichuan 2: Open Large-scale Language Models},
author={Baichuan},
journal={arXiv preprint arXiv:2309.10305},
url={https://arxiv.org/abs/2309.10305},
year={2023}
}